Dynamic Differential Linear Attention: Enhancing Linear Diffusion Transformer for High-Quality Image Generation
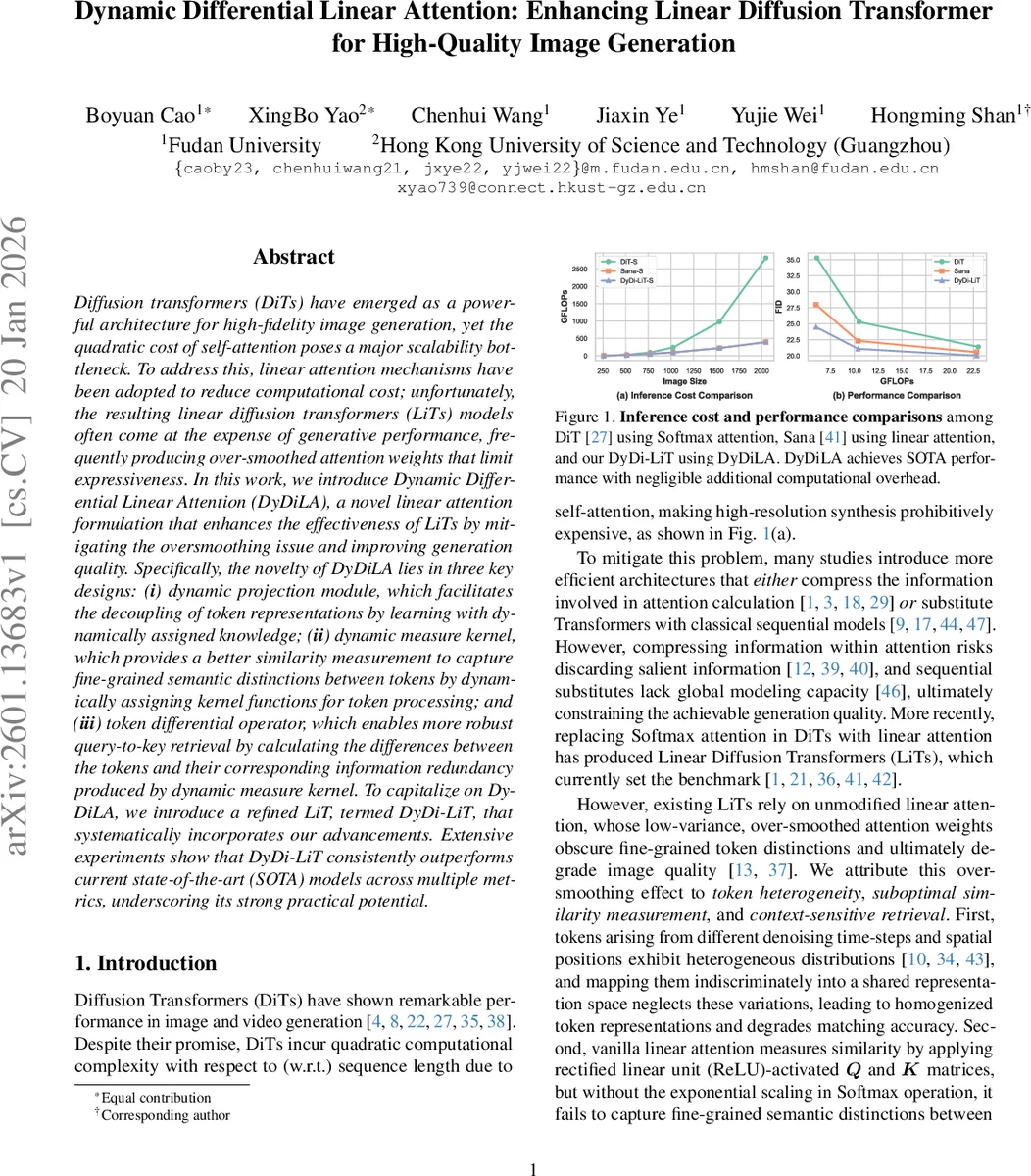
Diffusion transformers (DiTs) have emerged as a powerful architecture for high-fidelity image generation, yet the quadratic cost of self-attention poses a major scalability bottleneck. To address this, linear attention mechanisms have been adopted to reduce computational cost; unfortunately, the resulting linear diffusion transformers (LiTs) models often come at the expense of generative performance, frequently producing over-smoothed attention weights that limit expressiveness. In this work, we introduce Dynamic Differential Linear Attention (DyDiLA), a novel linear attention formulation that enhances the effectiveness of LiTs by mitigating the oversmoothing issue and improving generation quality. Specifically, the novelty of DyDiLA lies in three key designs: (i) dynamic projection module, which facilitates the decoupling of token representations by learning with dynamically assigned knowledge; (ii) dynamic measure kernel, which provides a better similarity measurement to capture fine-grained semantic distinctions between tokens by dynamically assigning kernel functions for token processing; and (iii) token differential operator, which enables more robust query-to-key retrieval by calculating the differences between the tokens and their corresponding information redundancy produced by dynamic measure kernel. To capitalize on DyDiLA, we introduce a refined LiT, termed DyDi-LiT, that systematically incorporates our advancements. Extensive experiments show that DyDi-LiT consistently outperforms current state-of-the-art (SOTA) models across multiple metrics, underscoring its strong practical potential.
💡 Research Summary
The paper tackles a fundamental scalability issue in diffusion transformers (DiTs): the quadratic cost of standard soft‑max self‑attention, which becomes prohibitive for high‑resolution image synthesis. While recent “linear diffusion transformers” (LiTs) replace soft‑max with linear attention to achieve O(N) complexity, they typically suffer from over‑smoothed attention weights, leading to a noticeable drop in generation quality. The authors attribute this degradation to three intertwined factors: (1) heterogeneous token distributions across diffusion timesteps and spatial locations, (2) sub‑optimal similarity measurement in vanilla linear attention, and (3) context‑sensitive query‑to‑key retrieval that is polluted by redundant information.
To address these problems, the authors propose Dynamic Differential Linear Attention (DyDiLA), a novel linear‑attention formulation that introduces three complementary mechanisms:
-
Dynamic Projection Module – Instead of using a single shared linear projector for queries (Q) and keys (K), DyDiLA learns a set of token‑specific projectors. For each token, a lightweight router selects the most appropriate projector based on a learned compatibility score. This decouples token representations, preserving the distinct statistical properties of tokens originating from different diffusion steps or spatial positions.
-
Dynamic Measure Kernel – Conventional linear attention applies the same kernel function ϕ(·) to all tokens (e.g., ReLU followed by a power operation). DyDiLA replaces this with a pool of learnable, norm‑preserving kernel functions, each parameterized by its own exponent γ_f. A second router assigns each token to the kernel that best matches its characteristics, thereby sharpening the dot‑product similarity for semantically related tokens while keeping unrelated tokens suppressed.
-
Token Differential Operator (TDO) – After the dynamic projection and kernel stages, each token has a primary representation (e_Q, f_K) and a redundancy counterpart (e_Q′, f_K′) derived from the token‑specific projectors. TDO learns token‑wise scaling factors λ_Q and λ_K (again via routing) and subtracts the scaled redundancies from the primary representations before performing the linear attention multiplication. This operation mitigates the “key redundancy” problem, making query‑to‑key retrieval more robust.
The final attention output combines the TDO result with a lightweight 3×3 depth‑wise convolution applied to the value matrix, enriching local spatial context without breaking linear complexity.
DyDi‑LiT Architecture – The authors embed DyDiLA into a standard diffusion transformer backbone (AdaLN conditioning, VAE‑encoded latent tokens, and a stack of L blocks). The overall computational cost remains O(N) and the additional parameters introduced by the routers and dynamic kernels constitute only a few percent of the total model size.
Experimental Setup – Experiments are conducted on ImageNet‑1K and a subset (Sub‑IN) at 256×256 and 512×512 resolutions. Three model scales (small, base, large) are trained on four NVIDIA RTX 3090 GPUs, following the original DiT training schedule (256 batch size, 400 K steps, AdamW, 1e‑4 LR, EMA). Diffusion hyper‑parameters match those of ADM (1000 steps, linear variance schedule). The pre‑trained VAE is taken from Stable Diffusion.
Results – Across all metrics—FID, sFID, KID, sKID, Inception Score (IS), precision (P%) and recall (R%)—DyDi‑LiT consistently outperforms the baseline DiT‑S (soft‑max) and recent linear‑attention models such as Sana, DiG‑S, and PixArt‑Σ‑S, while using comparable FLOPs (~110 GFLOPs). For example, the small DyDi‑LiT achieves FID 7.15 versus 11.81 for DiT‑S, sFID 0.0080 versus 0.0053, and IS 47.05 versus 43.28. Ablation studies reveal that removing any of the three components leads to a substantial performance drop, confirming their synergistic contribution. Replacing the token‑wise differential with an attention‑map‑wise differential yields slightly worse results, indicating the importance of fine‑grained token‑level correction.
Analysis & Limitations – The dynamic routing is implemented via arg‑max selection, which is non‑differentiable and may limit gradient flow; a soft‑assignment alternative could be explored. The router matrices scale with token count, potentially becoming memory‑intensive for extremely long sequences (e.g., video diffusion). Moreover, the evaluation is confined to image generation; extending DyDiLA to video, text‑to‑image, or multimodal diffusion models remains an open question.
Conclusions – DyDiLA introduces a principled way to retain the efficiency of linear attention while addressing its principal weakness—over‑smoothing—through token‑specific projection, adaptive kernel selection, and redundancy‑aware differential correction. Integrated into DyDi‑LiT, these innovations deliver state‑of‑the‑art generation quality on standard benchmarks with linear computational complexity, opening a promising path for scalable high‑fidelity diffusion models. Future work may focus on soft routing, memory‑efficient router designs, and broader multimodal applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment