BenchSeg: A Large-Scale Dataset and Benchmark for Multi-View Food Video Segmentation
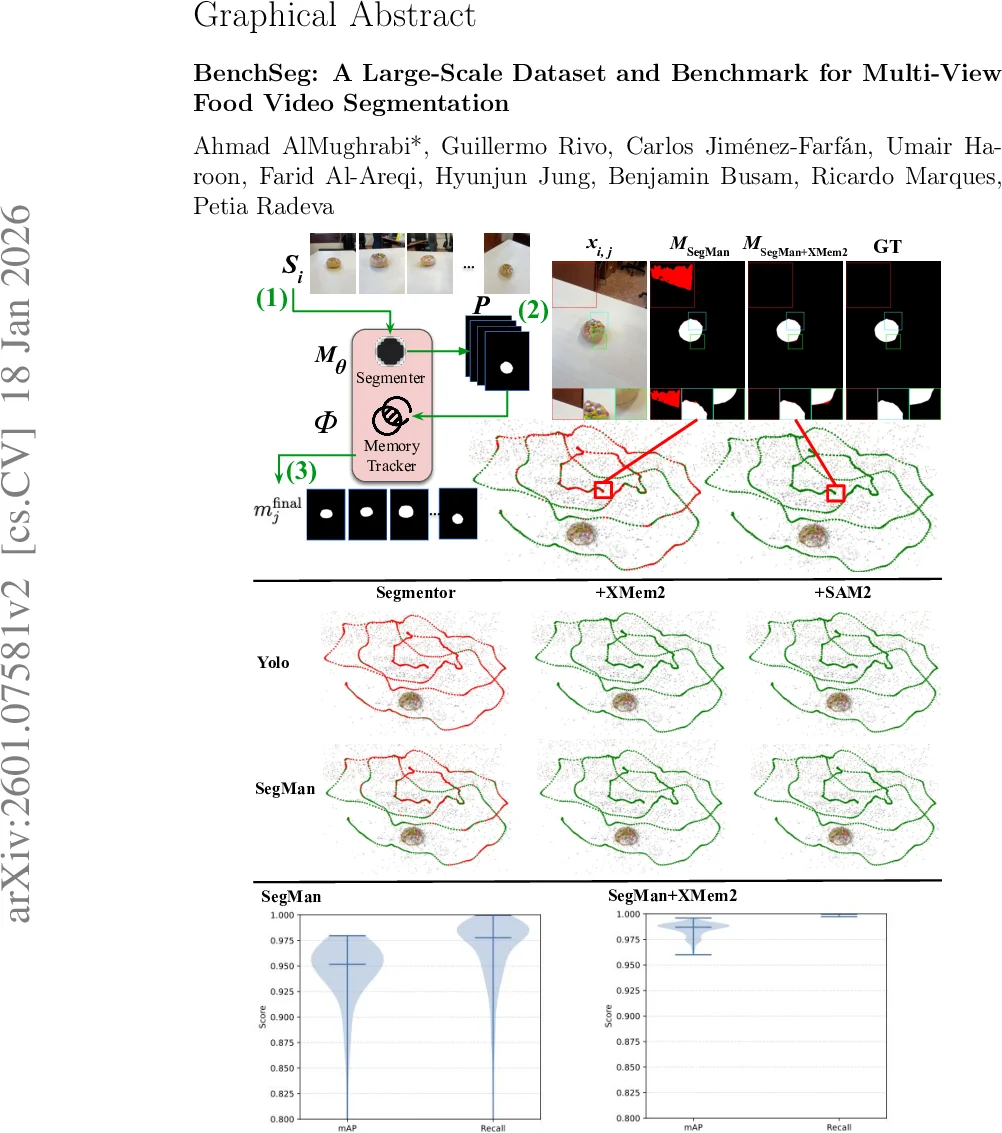
Food image segmentation is a critical task for dietary analysis, enabling accurate estimation of food volume and nutrients. However, current methods suffer from limited multi-view data and poor generalization to new viewpoints. We introduce BenchSeg, a novel multi-view food video segmentation dataset and benchmark. BenchSeg aggregates 55 dish scenes (from Nutrition5k, Vegetables & Fruits, MetaFood3D, and FoodKit) with 25,284 meticulously annotated frames, capturing each dish under free 360° camera motion. We evaluate a diverse set of 20 state-of-the-art segmentation models (e.g., SAM-based, transformer, CNN, and large multimodal) on the existing FoodSeg103 dataset and evaluate them (alone and combined with video-memory modules) on BenchSeg. Quantitative and qualitative results demonstrate that while standard image segmenters degrade sharply under novel viewpoints, memory-augmented methods maintain temporal consistency across frames. Our best model based on a combination of SeTR-MLA+XMem2 outperforms prior work (e.g., improving over FoodMem by ~2.63% mAP), offering new insights into food segmentation and tracking for dietary analysis. In addition to frame-wise spatial accuracy, we introduce a dedicated temporal evaluation protocol that explicitly quantifies segmentation stability over time through continuity, flicker rate, and IoU drift metrics. This allows us to reveal failure modes that remain invisible under standard per-frame evaluations. We release BenchSeg to foster future research. The project page including the dataset annotations and the food segmentation models can be found at https://amughrabi.github.io/benchseg.
💡 Research Summary
The paper introduces BenchSeg, a large‑scale multi‑view food video segmentation dataset and benchmark designed to address the shortcomings of existing food segmentation resources, which largely focus on static images or limited viewpoints. BenchSeg aggregates 55 dish scenes drawn from four public food datasets—Nutrition5k, Vegetables & Fruits, MetaFood3D, and FoodKit—capturing each dish under free 360° camera motion and providing dense pixel‑level annotations for a total of 25,284 frames. This design mirrors real‑world dietary monitoring scenarios where users record handheld sweeps of meals, thereby exposing models to extreme viewpoint changes, occlusions, lighting variations, and hand or utensil interference.
The benchmark evaluation protocol consists of two complementary dimensions. The first dimension uses conventional per‑frame segmentation metrics (mAP, IoU, Recall, Precision, F1, Accuracy) to assess spatial accuracy. The second dimension introduces three novel temporal stability metrics—Continuity, Flicker Rate, and IoU Drift—that quantify how consistently a mask evolves over time, capturing phenomena such as abrupt label switches, mask flickering, and gradual degradation that are invisible to frame‑wise scores alone.
Twenty state‑of‑the‑art segmentation models are evaluated, covering SAM‑based promptable methods, transformer backbones (Swin, SeTR, BiRefNet), classic CNNs (FPN, DeepLab), and large multimodal models. All models are trained exclusively on the existing FoodSeg103 dataset, ensuring that performance on BenchSeg reflects pure cross‑dataset generalization to unseen camera poses. The results show a pronounced drop in mAP (often >10 %) for pure image‑segmenters when confronted with novel viewpoints, confirming that scaling model capacity alone does not solve the viewpoint‑generalization problem.
To mitigate this, the authors attach video‑memory modules (XMem, XMem2) to each base segmenter, forming a two‑stage pipeline where a strong per‑frame mask is first generated and then temporally refined via memory‑based propagation. Hybrid configurations such as SeTR‑MLA+XMem2 and SegMan+XMem2 demonstrate markedly higher temporal stability: Flicker Rate and IoU Drift are substantially reduced, and overall mAP improves. Notably, the best hybrid model (SeTR‑MLA+XMem2) surpasses the prior FoodMem baseline by 2.63 % mAP, while also delivering smoother mask evolution across the 360° video sequences.
Beyond accuracy, the paper provides a systematic analysis of computational efficiency, reporting model size, memory footprint, and inference speed (FPS). Lightweight CNNs run fast but fail to maintain temporal consistency; large transformers achieve high spatial accuracy but are memory‑intensive; hybrid models strike a pragmatic balance suitable for deployment on mobile devices used in dietary assessment pipelines.
The contributions are fourfold: (1) the release of BenchSeg, a richly annotated, multi‑view food video dataset; (2) the definition of temporal stability metrics that expose failure modes invisible to traditional benchmarks; (3) an extensive cross‑dataset evaluation of 20 diverse models, highlighting the superiority of memory‑augmented approaches; and (4) practical guidance on model selection based on accuracy, stability, and efficiency trade‑offs.
Future research directions suggested include extending memory mechanisms to handle longer video horizons, tighter integration of promptable foundation models (e.g., SAM, large multimodal models) with memory trackers, and end‑to‑end evaluation of downstream nutrition estimation tasks using BenchSeg as a testbed. By providing both data and diagnostic tools, BenchSeg aims to catalyze the development of robust, temporally consistent food segmentation systems that can be reliably deployed in real‑world dietary monitoring applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment