iReasoner: Trajectory-Aware Intrinsic Reasoning Supervision for Self-Evolving Large Multimodal Models
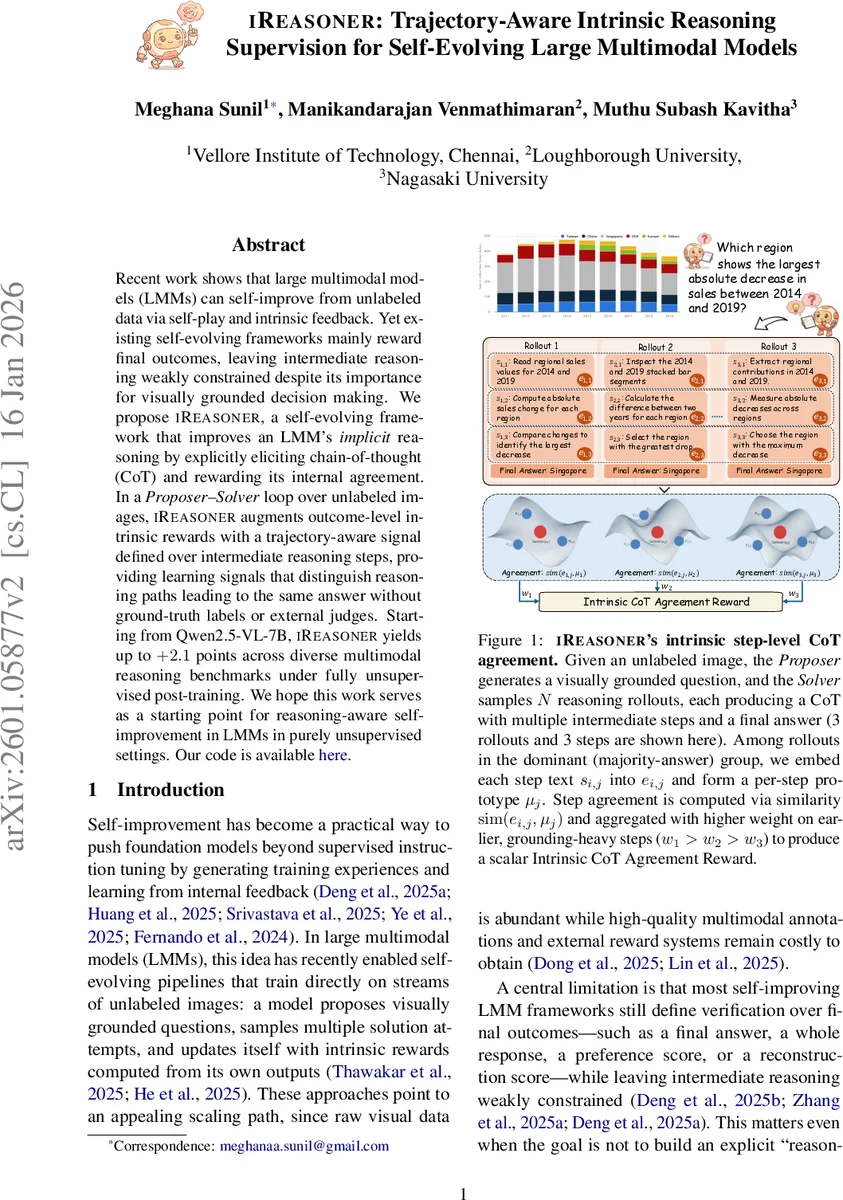
Recent work shows that large multimodal models (LMMs) can self-improve from unlabeled data via self-play and intrinsic feedback. Yet existing self-evolving frameworks mainly reward final outcomes, leaving intermediate reasoning weakly constrained despite its importance for visually grounded decision making. We propose iReasoner, a self-evolving framework that improves an LMM’s implicit reasoning by explicitly eliciting chain-of-thought (CoT) and rewarding its internal agreement. In a Proposer–Solver loop over unlabeled images, iReasoner augments outcome-level intrinsic rewards with a trajectory-aware signal defined over intermediate reasoning steps, providing learning signals that distinguish reasoning paths leading to the same answer without ground-truth labels or external judges. Starting from Qwen2.5-VL-7B, iReasoner yields up to $+2.1$ points across diverse multimodal reasoning benchmarks under fully unsupervised post-training. We hope this work serves as a starting point for reasoning-aware self-improvement in LMMs in purely unsupervised settings.
💡 Research Summary
iReasoner introduces a novel self‑evolving framework for large multimodal models (LMMs) that explicitly supervises intermediate reasoning steps, rather than only rewarding final answers. Building on the Proposer‑Solver loop popularized by recent works such as EvoLMM and VisPlay, the system first lets a Proposer generate a visually grounded question from an unlabeled image. The Solver then samples N reasoning rollouts, each producing a structured output consisting of a multi‑step chain‑of‑thought (CoT) enclosed in a <think> block and a final answer in an <answer> block.
The key innovation is the Intrinsic CoT Agreement Reward, a trajectory‑aware intrinsic signal that evaluates how well the intermediate steps of rollouts that share the same dominant answer align with each other. After identifying the dominant answer (\hat a) (the most frequent answer among the N rollouts), the rollouts belonging to the dominant‑answer group (G) are used to construct per‑step prototypes. Each step (s_{i,j}) is embedded via the model’s internal text encoder (f(\cdot)) (implemented as an ℓ2‑normalized mean of token embeddings) to obtain a vector (e_{i,j}). For each step index (j) that appears in at least one rollout of (G), a prototype (\mu_j) is computed as the mean of the corresponding embeddings. The cosine similarity between a rollout’s step embedding and its prototype, (r_{i,j}=sim(e_{i,j},\mu_j)), quantifies step‑wise agreement. Early steps, which typically contain visual grounding, receive higher weights (w_j) (with (w_1 > w_2 > \dots)), and the weighted sum (\tilde r_{step,i}) is scaled by the density factor (\rho = |G|/N) to produce the final step‑level reward (r_{step,i}= \rho \tilde r_{step,i}).
Solver training combines this step‑level reward with the traditional answer‑level self‑consistency reward. The answer‑level reward is defined as (r_{ans,i}=p(a_i|x,q)^{\alpha} (1-\eta \bar\ell_i)), where (p(a_i|x,q)) is the empirical answer probability, (\alpha) sharpens the distribution, and (\bar\ell_i) penalizes overly long CoT sequences. A time‑varying mixing coefficient (\lambda(t)) gradually shifts emphasis from answer‑level to step‑level supervision:
(r_{sol,i}= (1-\lambda(t)) r_{ans,i} + \lambda(t) r_{step,i}).
Early training thus relies on answer consistency to stabilize the loop, while later stages prioritize step agreement once a reliable dominant group and consistent step positions have emerged.
The Proposer receives an uncertainty‑shaped reward based on the entropy of the answer distribution, encouraging it to generate questions of moderate difficulty rather than trivial ones. This entropy‑based shaping keeps the Proposer’s output from collapsing to overly easy prompts throughout training.
Empirical evaluation uses Qwen2.5‑VL‑7B as the base LMM and applies fully unsupervised post‑training on large collections of unlabeled images. Across a suite of multimodal reasoning benchmarks—including VQA‑X, ScienceQA‑Vision, OCR‑based reasoning, and others—iReasoner achieves average improvements of up to +2.1 points over the baseline self‑evolving pipelines that only use answer‑level rewards. Detailed analyses show that the size of the dominant‑answer group and the mean step‑wise similarity both increase steadily during training, indicating that the Solver’s CoT traces become more coherent and aligned. Ablation studies confirm that removing the step‑level reward or fixing (\lambda(t)=0) leads to significantly lower performance, underscoring the necessity of trajectory‑aware supervision.
Limitations are acknowledged: the prototype‑based similarity relies on simple averaging of text embeddings, which may not capture complex logical structures or multi‑branch reasoning paths. Moreover, the current approach treats visual grounding implicitly through the text encoder, potentially missing fine‑grained cross‑modal alignment. Future work could explore graph‑structured reasoning representations, multimodal attention‑based step alignment, and hybrid rewards that incorporate external knowledge without sacrificing the fully unsupervised nature of the loop.
In summary, iReasoner demonstrates that intrinsic, step‑aware rewards can be constructed without any labeled data or external judges, enabling LMMs to self‑evolve not only toward correct answers but also toward consistent, grounded reasoning processes. This bridges a critical gap between self‑play based model improvement and chain‑of‑thought optimization, opening a pathway toward more reliable and interpretable multimodal AI systems trained purely from raw visual data.
Comments & Academic Discussion
Loading comments...
Leave a Comment