Leveraging Prediction Entropy for Automatic Prompt Weighting in Zero-Shot Audio-Language Classification
Audio-language models have recently demonstrated strong zero-shot capabilities by leveraging natural-language supervision to classify audio events without labeled training data. Yet, their performance is highly sensitive to the wording of text prompts, with small variations leading to large fluctuations in accuracy. Prior work has mitigated this issue through prompt learning or prompt ensembling. However, these strategies either require annotated data or fail to account for the fact that some prompts may negatively impact performance. In this work, we present an entropy-guided prompt weighting approach that aims to find a robust combination of prompt contributions to maximize prediction confidence. To this end, we formulate a tailored objective function that minimizes prediction entropy to yield new prompt weights, utilizing low-entropy as a proxy for high confidence. Our approach can be applied to individual samples or a batch of audio samples, requiring no additional labels and incurring negligible computational overhead. Experiments on five audio classification datasets covering environmental, urban, and vocal sounds, demonstrate consistent gains compared to classical prompt ensembling methods in a zero-shot setting, with accuracy improvements 5-times larger across the whole benchmark.
💡 Research Summary
The paper addresses a critical limitation of audio‑language models (ALMs) such as CLAP‑2022: while they can perform zero‑shot audio classification by matching audio embeddings with text embeddings of class names, their predictions are highly sensitive to the exact wording of the textual prompts. Small variations in phrasing can cause large swings in accuracy, making deployment unreliable. Existing remedies fall into two categories. Prompt learning requires a few labeled examples and incurs additional computational cost, while simple prompt ensembling (majority voting or averaging text embeddings) treats all prompts equally and cannot suppress poorly performing prompts, often leading to sub‑optimal results.
To overcome these issues, the authors propose an entropy‑guided prompt weighting scheme that automatically learns a weight vector β over a set of N_T hand‑crafted prompt templates. The key idea is to treat low prediction entropy as a proxy for high confidence. They formulate an objective L(β) consisting of three terms: (i) the average entropy H(p_i) of the model’s class probability vectors across a batch of samples, which is minimized to encourage confident predictions; (ii) a zero‑shot regularization term that penalizes divergence from the baseline single‑template prediction \hat{p}_i (the “This is a sound of {class}” prompt), preventing β from drifting too far from the original zero‑shot behavior; and (iii) an entropy regularizer on β itself, encouraging a smooth, non‑sparse distribution and implicitly enforcing non‑negativity. β is constrained to the probability simplex (sum to one, non‑negative).
The optimization proceeds by pre‑computing all audio embeddings f_i and text embeddings t_{jk} once, then iteratively updating β via a fixed‑point rule derived from setting ∂L/∂β = 0. The update equation β_j ∝ exp(R_j/λ_β) normalizes the exponentiated “responsibility” R_j, which aggregates per‑sample contributions from both the entropy term and the zero‑shot regularization term (weighted by λ_zs). The algorithm stops when the L2 change in β falls below 1e‑6, typically after a few iterations, and adds negligible overhead (≈0.2 s) beyond feature extraction.
Experiments are conducted on five benchmark audio classification datasets covering environmental (ESC‑50, ESC‑Actions), urban (US8K, SESA), and vocal (VS) domains. A total of 35 diverse prompt templates, drawn from prior work, are used uniformly across all datasets. Three experimental settings are explored:
-
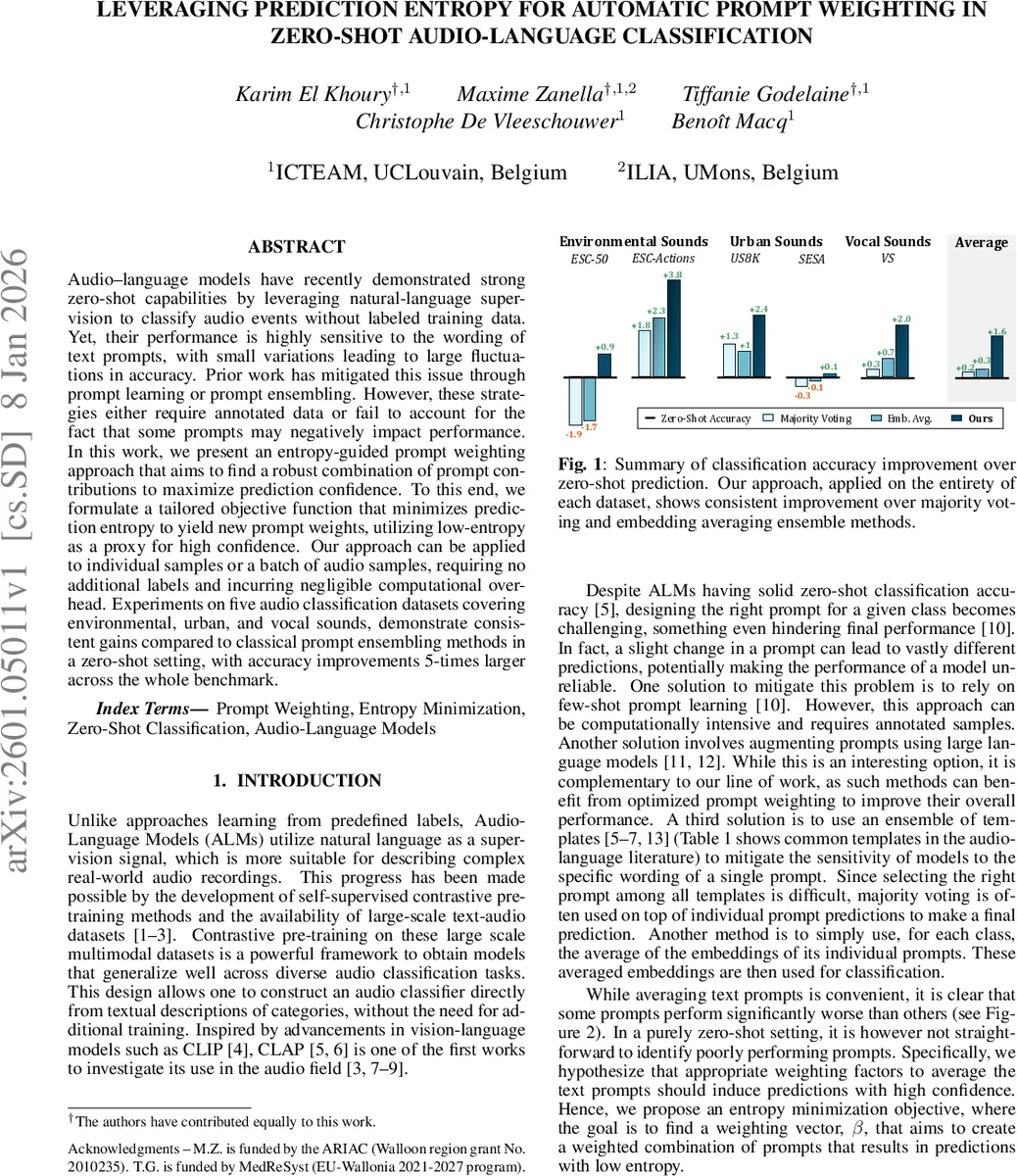
Single‑sample β – β is optimized independently for each test sample (N_S = 1). This zero‑shot‑only scenario yields average accuracy gains of up to 0.7 % over the raw zero‑shot baseline and outperforms all six baseline ensembling methods. Notably, on ESC‑50 the method surpasses the simple average‑embedding baseline by 2.4 % absolute.
-
Dataset β – β is learned jointly over the entire test set (N_S equals dataset size). Here λ_zs is reduced to 0.1 because the larger sample pool already stabilizes the optimization. This setting improves over single‑sample β by ~0.7 % and over all baselines by ~0.9 % on average, confirming that a globally learned weighting vector can capture dataset‑level prompt usefulness.
-
Dataset β with pruning – The authors introduce iterative pruning cycles: after each β optimization, the 15 % of prompts with the highest entropy contributions are removed, and β is re‑initialized for the next cycle. After four cycles (≈50 % total pruning), further gains of ~0.4 % are observed, leading to a cumulative improvement of ~1.4 % across all baselines. ESC‑Actions benefits the most, with a 3.8 % absolute boost.
Baseline methods include plain majority voting, entropy‑weighted voting, voting after pruning, average text embedding, entropy‑weighted embedding averaging, and embedding averaging after pruning. Across all datasets, the proposed entropy‑guided weighting consistently achieves the highest accuracy, demonstrating robustness to prompt variability.
Ablation studies on λ_zs (regularization strength) and pruning percentages confirm the chosen hyper‑parameters (λ_zs = 100 for single‑sample, 0.1 for dataset‑level, 15 % pruning per cycle) as optimal. Runtime analysis shows the method adds only 0.2 seconds of overhead compared to feature extraction, making it practical for real‑time or large‑scale deployments.
In summary, the paper contributes (i) a principled entropy‑minimization framework for prompt weighting that operates without any labeled data, (ii) a combined entropy and zero‑shot regularization that balances confidence with fidelity to the original model, and (iii) an effective pruning strategy to discard detrimental prompts. This approach substantially mitigates the prompt‑sensitivity problem of zero‑shot audio‑language models, offering a lightweight, label‑free solution that can be readily integrated into existing ALM pipelines and potentially extended to other multimodal zero‑shot tasks.
Comments & Academic Discussion
Loading comments...
Leave a Comment