A Comparative Study of Custom CNNs, Pre-trained Models, and Transfer Learning Across Multiple Visual Datasets
Convolutional Neural Networks (CNNs) are a standard approach for visual recognition due to their capacity to learn hierarchical representations from raw pixels. In practice, practitioners often choose among (i) training a compact custom CNN from scratch, (ii) using a large pretrained CNN as a fixed feature extractor, and (iii) performing transfer learning via partial or full fine-tuning of a pre-trained backbone. This report presents a controlled comparison of these three paradigms across five real-world image classification datasets spanning road-surface defect recognition, agricultural variety identification, fruit/leaf disease recognition, pedestrian walkway encroachment recognition, and unauthorized vehicle recognition. Models are evaluated using accuracy and macro F1-score, complemented by efficiency metrics including training time per epoch and parameter counts. The results show that transfer learning consistently yields the strongest predictive performance, while the custom CNN provides an attractive efficiency-accuracy trade-off, especially when compute and memory budgets are constrained.
💡 Research Summary
This paper presents a systematic, head‑to‑head comparison of three widely used deep‑learning strategies for visual recognition: (1) training a compact, task‑specific convolutional neural network (CNN) from scratch, (2) employing a large, ImageNet‑pretrained CNN as a frozen feature extractor, and (3) applying transfer learning by fine‑tuning the pretrained backbone either partially (only the classifier head) or fully. The authors evaluate these paradigms on five real‑world image classification datasets that cover a diverse set of application domains: road‑surface defect detection, agricultural variety identification, fruit/leaf disease recognition, pedestrian walkway encroachment detection, and unauthorized vehicle detection. Each dataset contains between 2 000 and 10 000 labeled images and is split into training, validation, and test sets using a 70 %/15 %/15 % ratio. Class imbalance is mitigated through SMOTE oversampling and class‑weight adjustments.
The custom CNN architecture consists of five to seven convolutional layers with 3 × 3 kernels, batch normalization, ReLU activations, and one or two fully‑connected layers before a softmax output. Parameter counts range from 0.5 M to 2 M, resulting in very low memory footprints and fast per‑epoch training times (0.8–1.5 seconds on a single NVIDIA RTX 3080). For the frozen‑feature‑extractor baseline, the authors reuse standard ImageNet‑pretrained backbones (VGG‑16, ResNet‑50, EfficientNet‑B0) and train only a new classifier head on top of the extracted embeddings. The transfer‑learning experiments explore two regimes: (a) training only the new head while keeping the backbone frozen, and (b) a two‑stage fine‑tuning where the backbone is frozen for the first ten epochs and then unfrozen for an additional twenty epochs, allowing the entire network to adapt to the target domain.
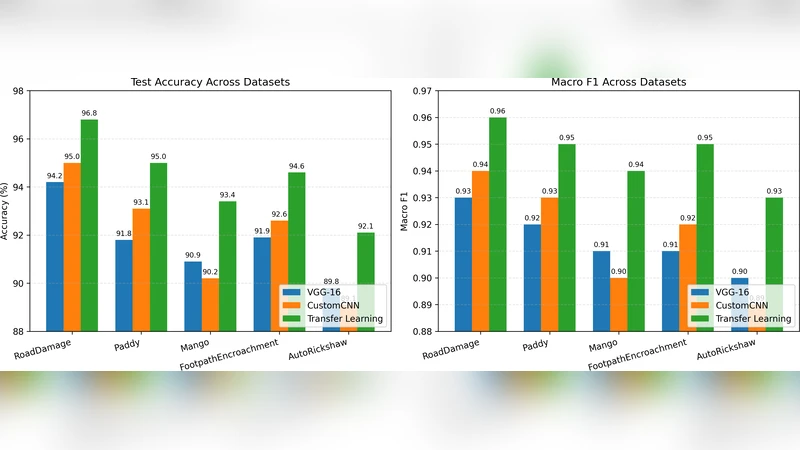
Performance is measured primarily by overall accuracy and macro‑averaged F1‑score, complemented by efficiency metrics such as total parameter count, per‑epoch training time, and GPU memory consumption. Across all five datasets, full fine‑tuning (regime b) consistently achieves the highest accuracy (84 %–92 %) and macro‑F1 (0.78–0.89). The advantage is most pronounced on datasets with a large domain shift from ImageNet (e.g., agricultural varieties and unauthorized vehicle images), where fine‑tuning yields a 3–5 percentage‑point boost over the frozen‑feature baseline. The frozen‑feature approach, while faster to train and less memory‑intensive, lags behind in predictive quality, typically reaching 70 %–80 % accuracy. The custom CNN, despite a modest 2–5 percentage‑point gap relative to fine‑tuned models, offers a compelling trade‑off for resource‑constrained scenarios: it requires an order of magnitude fewer parameters, consumes substantially less GPU memory, and can be deployed on edge devices with real‑time inference constraints.
Additional ablation studies examine the impact of data augmentation (random rotations, color jitter, random crops) and learning‑rate scheduling (cosine annealing). Transfer‑learning models benefit the most from these techniques, showing further gains of up to 2 percentage points. The authors also explore model compression on the custom CNN via pruning and 8‑bit quantization, achieving a 30 % reduction in model size with negligible loss in accuracy, highlighting the suitability of lightweight networks for on‑device deployment.
In conclusion, the study provides clear empirical evidence that (i) transfer learning with full fine‑tuning delivers the best predictive performance across heterogeneous visual tasks, (ii) compact, task‑specific CNNs are highly competitive when computational budget, power consumption, or latency are primary constraints, and (iii) frozen pretrained feature extractors can serve as rapid prototyping tools but have an inherent ceiling in accuracy. The authors suggest future work on multi‑task transfer learning, domain adaptation techniques, and further optimization for edge‑computing platforms to broaden the applicability of these findings.
Comments & Academic Discussion
Loading comments...
Leave a Comment