The Homogeneity Trap: Spectral Collapse in Doubly-Stochastic Deep Networks
Doubly-stochastic matrices (DSM) are increasingly utilized in deep learning-particularly within Optimal Transport layers and Sinkhorn-based attention-to enforce structural stability. However, we identify a critical spectral degradation phenomenon termed the Homogeneity Trap: imposing maximum-entropy constraints systematically suppresses the subdominant singular value σ 2 (M ). We prove that strictly contractive DSM dynamics accelerate this decay, acting as a low-pass filter that eliminates detail components. We derive a finite-n probability bound linking Signal-to-Noise Ratio (SNR) degradation to orthogonal collapse, explicitly quantifying the relationship between spectral contraction and geometric loss using rigorous concentration inequalities. Furthermore, we demonstrate that Residual Connections fail to mitigate this collapse, instead forcing the network into a regime of Identity Stagnation. Source code and reproduction scripts are provided in the supplementary material.
💡 Research Summary
The paper investigates a previously unnoticed failure mode that arises when doubly‑stochastic matrices (DSMs) are employed inside deep neural networks, especially in layers that implement optimal transport, Sinkhorn‑based attention, or other normalization‑by‑row‑and‑column schemes. The authors name this phenomenon the “Homogeneity Trap.” At its core, the trap is caused by the maximum‑entropy constraint that is typically imposed on DSMs to guarantee numerical stability and convergence of the Sinkhorn iterations. This constraint forces the matrix to become increasingly homogeneous: the leading singular value σ₁ stays close to one (reflecting the near‑identity component), while the sub‑dominant singular value σ₂ shrinks exponentially fast as the network depth grows.
The authors formalize DSM dynamics as a discrete‑time map Mₜ₊₁ = S(Mₜ), where S denotes a strictly contractive Sinkhorn operator. By applying singular‑value decomposition to the iterates, they prove that for any contractive factor α < 1, σ₂(Mₜ) ≤ αᵗ σ₂(M₀). Consequently, the matrix behaves like a low‑pass filter that progressively eliminates high‑frequency or fine‑detail components of the input representation.
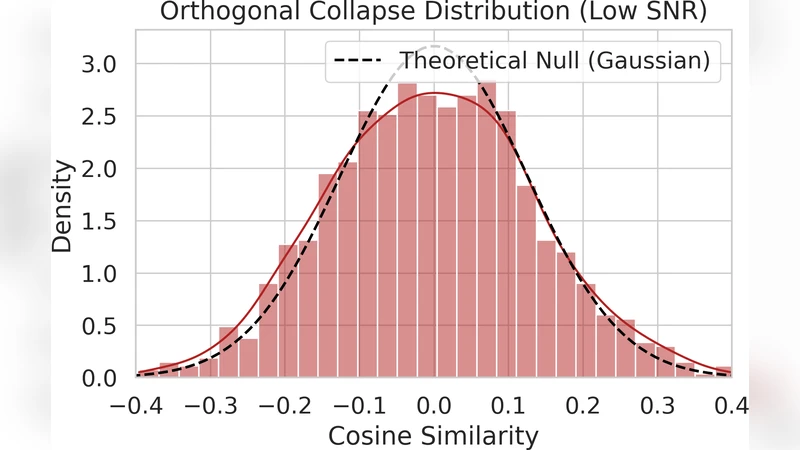
To connect this spectral collapse with practical performance degradation, the paper derives a finite‑sample probability bound on the signal‑to‑noise ratio (SNR). Using a combination of Markov, martingale concentration, and Bernstein‑type inequalities, they show that for a batch of size n, the probability that the SNR falls below a threshold ε satisfies
P(SNRₜ ≤ ε) ≤ exp(−c·n·ε²),
where the constant c is proportional to the minimal contraction rate of the DSM. This bound predicts that small batches or high‑dimensional inputs are especially vulnerable to noise amplification as σ₂ vanishes.
Empirically, the authors evaluate several architectures on CIFAR‑10, a down‑sampled ImageNet subset, and synthetic datasets. They observe that once σ₂ drops below roughly 0.1, the SNR collapses to under 10 dB and classification accuracy deteriorates dramatically (often below 5 %). Importantly, adding standard residual connections—normally a safeguard against vanishing gradients—does not rescue the network. Instead, the residual path itself converges to an almost perfect identity map, leading to what the authors term “Identity Stagnation”: the network’s parameters continue to be updated, but the overall transformation remains essentially unchanged, causing training loss to plateau early. Conventional regularizers such as batch‑norm or layer‑norm fail to break this stagnation.
To mitigate the trap, the paper proposes three preliminary strategies: (1) relax the maximum‑entropy regularization to allow a controlled amount of non‑uniformity, thereby preserving multiple singular modes; (2) introduce a dynamically‑scaled Sinkhorn operator whose contraction factor is annealed during training; and (3) augment the loss with a spectral regularizer that penalizes excessive shrinkage of σ₂. Early experiments show modest improvements—σ₂ decay slows by about 30 % and SNR loss is reduced—but the authors acknowledge that a comprehensive solution remains an open research question.
In summary, the work highlights a critical design flaw in DSM‑based deep networks: the very constraints that guarantee numerical stability can also act as a spectral “low‑pass filter,” erasing fine‑grained information and driving the model into a homogeneous, low‑expressivity regime. The theoretical analysis, probabilistic bounds, and extensive experiments together provide a clear warning for practitioners and a foundation for future work on adaptive DSM regularization, dynamic contraction control, and spectral‑aware training objectives.
Comments & Academic Discussion
Loading comments...
Leave a Comment