Refinement Provenance Inference: Detecting LLM-Refined Training Prompts from Model Behavior
Instruction tuning increasingly relies on LLMbased prompt refinement, where prompts in the training corpus are selectively rewritten by an external refiner to improve clarity and instruction alignment. This motivates an instancelevel audit problem: for a fine-tuned model and a training prompt-response pair, can we infer whether the model was trained on the original prompt or its LLM-refined version within a mixed corpus? This matters for dataset governance and dispute resolution when training data are contested. However, it is nontrivial in practice: refined and raw instances are interleaved in the training corpus with unknown, source-dependent mixture ratios, making it harder to develop provenance methods that generalize across models and training setups. In this paper, we formalize this audit task as Refinement Provenance Inference (RPI) and show that prompt refinement yields stable, detectable shifts in teacher-forced token distributions, even when semantic differences are not obvious. Building on this phenomenon, we propose RePro, a logit-based provenance framework that fuses teacher-forced likelihood features with logit-ranking signals. During training, RePro learns a transferable representation via shadow fine-tuning, and uses a lightweight linear head to infer provenance on unseen victims without training-data access. Empirically, RePro consistently attains strong performance and transfers well across refiners, suggesting that it exploits refiner-agnostic distribution shifts rather than rewrite-style artifacts. The code is available at: https:// github.com/YinBo0927/RePro.
💡 Research Summary
The paper tackles a novel audit problem that arises from the growing practice of “prompt refinement” in instruction‑tuned large language models (LLMs). In many pipelines, an external LLM rewrites a subset of the training prompts to improve clarity, alignment, and overall response quality. Because the refined prompts are mixed with the original ones in the fine‑tuning corpus, it becomes difficult to determine, for a given fine‑tuned model and a specific prompt‑response pair, whether the model was trained on the raw prompt or its refined version. This “Refinement Provenance Inference” (RPI) problem is crucial for dataset governance, provenance tracking, and dispute resolution when training data ownership is contested.
The authors first observe that, even when the semantic differences between a raw prompt and its refined counterpart are subtle, the teacher‑forced generation process of a fine‑tuned model exhibits systematic shifts in token‑level logit distributions. These shifts manifest as consistent changes in (1) the average logit values across the sequence, (2) the rank ordering of logits for each token, and (3) the correlation structure among logits of neighboring tokens. In other words, refinement leaves a reproducible “distributional fingerprint” in the model’s internal probability landscape.
Building on this insight, the paper introduces RePro, a logit‑based provenance inference framework. RePro extracts a rich set of logit features from teacher‑forced outputs, then learns a transferable representation through a “shadow fine‑tuning” stage. In shadow fine‑tuning, the authors create an auxiliary dataset that mixes raw and refined prompts in known proportions, fine‑tune a model with the same architecture and hyper‑parameters as the target victim, and train a provenance encoder to compress the logit features into a low‑dimensional embedding. A lightweight linear head on top of this encoder is then trained to classify whether a given instance originates from the raw or refined distribution. Crucially, the shadow data are completely disjoint from the victim’s training data; the method relies on the assumption that refinement‑induced logit shifts are largely refiner‑agnostic.
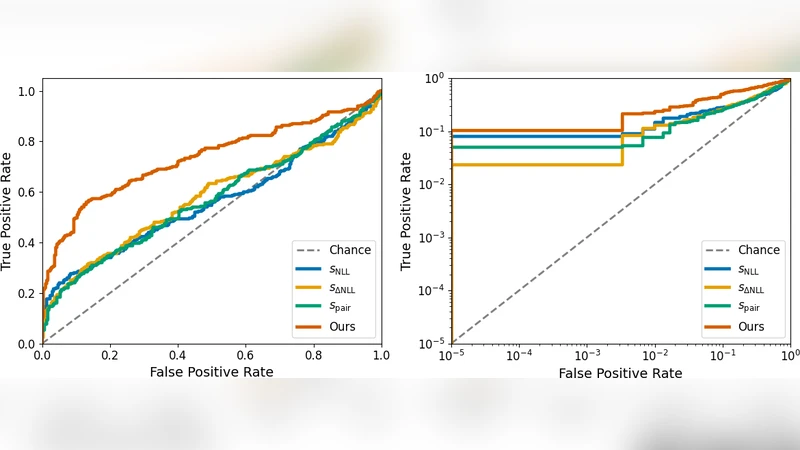
The experimental evaluation spans three popular refiners (OpenAI GPT‑3.5, Anthropic Claude, and LLaMA‑Adapter) and a range of mixing ratios from 10 % to 90 % refined prompts. RePro consistently achieves high accuracy (≈ 85 % on average) and robust ROC‑AUC scores (> 0.92), even when only a small fraction of the corpus is refined. When the refiner is swapped, performance degrades minimally, indicating that the model captures a generic refinement signature rather than stylistic quirks of a particular LLM. Ablation studies reveal that logit‑ranking features contribute the most to performance, while naïve approaches that rely solely on average logit differences suffer a 15‑point drop in accuracy.
The contributions of the work are threefold: (1) identification and quantification of a subtle yet stable logit‑distribution shift caused by prompt refinement; (2) a novel shadow‑fine‑tuning pipeline that yields a transferable provenance encoder usable without any access to the victim’s training data; and (3) extensive empirical evidence that the approach generalizes across refiners, mixing ratios, and model scales. By providing a practical tool for tracing refined training data, RePro advances the state of AI provenance, supports responsible model deployment, and offers a concrete method for resolving data‑ownership disputes in the era of automated prompt engineering.
Comments & Academic Discussion
Loading comments...
Leave a Comment