Evaluating Feature Dependent Noise in Preference-based Reinforcement Learning
Learning from Preferences in Reinforcement Learning (PbRL) has gained attention recently, as it serves as a natural fit for complicated tasks where the reward function is not easily available. However, preferences often come with uncertainty and noise if they are not from perfect teachers. Much prior literature aimed to detect noise, but with limited types of noise and most being uniformly distributed with no connection to observations. In this work, we formalize the notion of targeted feature-dependent noise and propose several variants like trajectory feature noise, trajectory similarity noise, uncertainty-aware noise, and Language Model noise. We evaluate feature-dependent noise, where noise is correlated with certain features in complex continuous control tasks from DMControl and Meta-world. Our experiments show that in some feature-dependent noise settings, the state-of-the-art noise-robust PbRL method’s learning performance is significantly deteriorated, while PbRL method with no explicit denoising can surprisingly outperform noise-robust PbRL in majority settings. We also find language model’s noise exhibits similar characteristics to featuredependent noise, thereby simulating realistic humans and call for further study in learning with feature-dependent noise robustly.
💡 Research Summary
The paper addresses a critical gap in preference‑based reinforcement learning (PbRL): most prior work assumes that preference noise is either uniform or independent of the observed data, which does not reflect the way human teachers actually err. To bridge this gap, the authors formalize feature‑dependent noise, a class of noise whose occurrence probability is correlated with specific characteristics of the trajectories or states involved. Four concrete instantiations are introduced: (1) Trajectory‑feature noise, where large values of selected state variables (e.g., high velocity or joint angles) increase the chance of a flipped preference; (2) Trajectory‑similarity noise, which makes preferences more likely to be wrong when the two compared trajectories are dissimilar; (3) Uncertainty‑aware noise, which ties the flip probability to the model’s own predictive uncertainty about a state; and (4) Language‑model noise, where a large language model (LLM) is prompted to emulate a human annotator, deliberately producing erroneous labels in ambiguous situations.
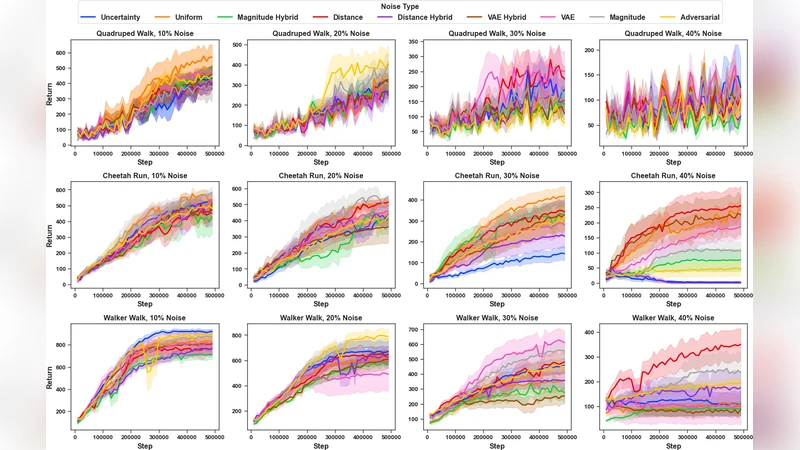
The experimental suite spans continuous‑control benchmarks from DMControl (Walker‑Walk, Hopper‑Stand, etc.) and Meta‑World (Pick‑Place, Door‑Open, etc.). For each environment, a set of 5–10 salient features is identified, and the four noise functions are parameterized to produce label error rates ranging from 10 % to 40 %. Three algorithmic baselines are evaluated: (i) a standard PbRL method (PEBBLE), (ii) two state‑of‑the‑art noise‑robust approaches (D‑REX and Rank‑Based Denoising), and (iii) a no‑noise control. Performance is measured by final episodic return, learning speed, and sensitivity to the injected noise.
Results reveal a striking paradox. When feature‑dependent noise is present, the sophisticated noise‑robust methods underperform dramatically. For example, under high uncertainty‑aware noise (≈30 % error), D‑REX’s return drops by more than 35 % relative to the clean case, and Rank‑Based Denoising often fails to converge. In contrast, the vanilla PbRL algorithm (PEBBLE) degrades far less—typically 10–15 %—and in many settings actually surpasses the robust baselines. The authors attribute this to a mismatch: robust methods are designed under the assumption of uniformly distributed noise and therefore mis‑calibrate their denoising when the noise is systematically tied to trajectory features.
The LLM‑generated noise behaves similarly to the handcrafted uncertainty‑aware noise, confirming that large language models can serve as realistic proxies for human annotators whose mistakes concentrate in difficult or ambiguous contexts. This finding underscores the ecological validity of the proposed noise models.
From these observations, the paper argues that future PbRL research must explicitly model the structure of noise rather than treating it as an i.i.d. nuisance. Potential avenues include Bayesian inference schemes that jointly learn the policy and the feature‑dependent noise distribution, adaptive denoising that leverages meta‑information from annotators (confidence scores, response latency), and data‑augmentation pipelines that synthesize realistic noisy preferences using LLMs. By highlighting the vulnerability of current noise‑robust methods to structured noise, the work paves the way toward more resilient preference‑driven learning systems suitable for real‑world human‑in‑the‑loop applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment