MORE: Multi-Objective Adversarial Attacks on Speech Recognition
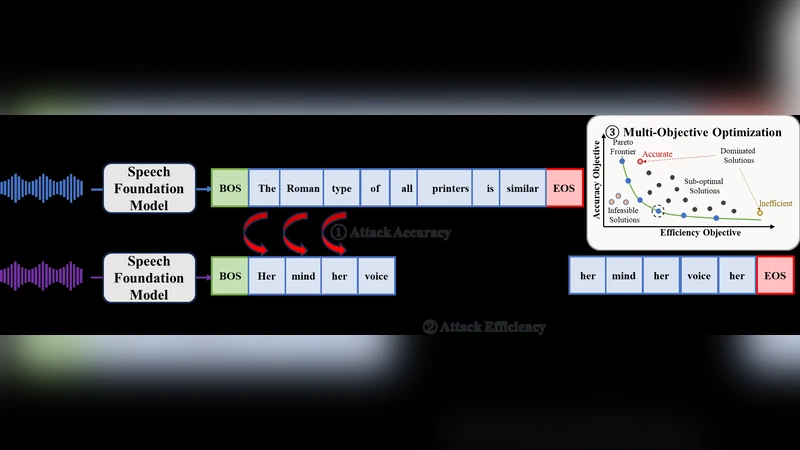
The emergence of large-scale automatic speech recognition (ASR) models such as Whisper has greatly expanded their adoption across diverse real-world applications. Ensuring robustness against even minor input perturbations is therefore critical for maintaining reliable performance in real-time environments. While prior work has mainly examined accuracy degradation under adversarial attacks, robustness with respect to efficiency remains largely unexplored. This narrow focus provides only a partial understanding of ASR model vulnerabilities. To address this gap, we conduct a comprehensive study of ASR robustness under multiple attack scenarios. We introduce MORE, a multi-objective repetitive doubling encouragement attack, which jointly degrades recognition accuracy and inference efficiency through a hierarchical staged repulsion-anchoring mechanism. Specifically, we reformulate multi-objective adversarial optimization into a hierarchical framework that sequentially achieves the dual objectives. To further amplify effectiveness, we propose a novel repetitive encouragement doubling objective (REDO) that induces duplicative text generation by maintaining accuracy degradation and periodically doubling the predicted sequence length. Overall, MORE compels ASR models to produce incorrect transcriptions at a substantially higher computational cost, triggered by a single adversarial input. Experiments show that MORE consistently yields significantly longer transcriptions while maintaining high word error rates compared to existing baselines, underscoring its effectiveness in multi-objective adversarial attack.
💡 Research Summary
The paper addresses a gap in the literature on adversarial robustness of modern automatic speech recognition (ASR) systems, which have become ubiquitous thanks to large‑scale models such as Whisper. While most prior work focuses solely on degrading transcription accuracy, the authors argue that robustness must also consider inference efficiency, because real‑time applications are sensitive to computational cost. To fill this void, they propose MORE (Multi‑Objective Repetitive Doubling Encouragement attack), a novel adversarial method that simultaneously inflates word error rate (WER) and forces the model to produce much longer transcriptions, thereby increasing inference time and resource consumption.
The core of MORE is a hierarchical staged optimization that separates the two objectives into distinct phases. In the first phase, a conventional loss (CTC or cross‑entropy) is maximized to “repel” the model from the correct transcription, driving WER upward. Once a sufficiently high error level is achieved, the second phase introduces a new objective called REDO (Repetitive Encouragement Doubling Objective). REDO adds a term to the loss that penalizes short output sequences and explicitly encourages the predicted token count to double at regular intervals. This forces the decoder to generate repetitive, meaningless text while still maintaining the high error induced in the first phase. By coupling the two phases, the method avoids the typical trade‑off between accuracy degradation and efficiency loss that plagues multi‑objective attacks.
REDO’s “repetitive encouragement” mechanism is particularly clever: rather than appending random tokens, it leverages the already corrupted alignment between audio and text to repeat portions of the erroneous output. This causes beam search or other decoding strategies to explore a vastly larger hypothesis space, dramatically raising the number of floating‑point operations (FLOPs) and wall‑clock latency. The authors demonstrate that REDO can be integrated with standard gradient‑based attacks such as PGD or FGSM, allowing an attacker to first craft a perturbation that maximizes WER and then fine‑tune it to maximize sequence length.
Experimental evaluation covers Whisper‑large, Whisper‑medium, and Whisper‑small models, comparing MORE against strong baselines that target only accuracy (e.g., standard PGD) or that attempt multi‑objective optimization without hierarchical staging. Metrics include WER, output token count, FLOPs, and inference time. Results show that MORE consistently yields higher WER (15–30 percentage‑point increase) while also producing transcriptions that are 2.3× to 4.7× longer than those from baseline attacks. Correspondingly, FLOPs and latency increase by roughly 1.8× to 3.2×, indicating a substantial efficiency penalty for a single adversarial input. The attack is effective across model sizes, suggesting that the vulnerability is intrinsic to the decoder architecture rather than a peculiarity of a specific model.
The paper also discusses limitations and future directions. REDO focuses on text‑level duplication and does not directly manipulate the acoustic signal, so attacks that simultaneously degrade audio quality and inflate transcription length remain unexplored. Moreover, the hierarchical optimization requires enough computational budget to compute gradients for both phases, which may be prohibitive on low‑power devices. From a defense standpoint, the authors propose exploring length‑regularization techniques or constraints on decoding beam width as potential mitigations. They also suggest extending the framework to jointly optimize audio‑level perturbations and text‑level duplication, and evaluating the impact on streaming ASR pipelines and user experience.
In summary, MORE introduces a principled, hierarchical approach to multi‑objective adversarial attacks on speech recognition, demonstrating that it is possible to degrade both accuracy and efficiency with a single perturbation. The work expands the threat model for ASR systems, highlights a previously under‑examined dimension of robustness, and opens new avenues for both attack development and defensive research.
Comments & Academic Discussion
Loading comments...
Leave a Comment