Sparse Threats, Focused Defense: Criticality-Aware Robust Reinforcement Learning for Safe Autonomous Driving
Reinforcement learning (RL) has shown considerable potential in autonomous driving (AD), yet its vulnerability to perturbations remains a critical barrier to real-world deployment. As a primary countermeasure, adversarial training improves policy robustness by training the AD agent in the presence of an adversary that deliberately introduces perturbations. Existing approaches typically model the interaction as a zero-sum game with continuous attacks. However, such designs overlook the inherent asymmetry between the agent and the adversary and then fail to reflect the sparsity of safety-critical risks, rendering the achieved robustness inadequate for practical AD scenarios. To address these limitations, we introduce criticality-aware robust RL (CARRL), a novel adversarial training approach for handling sparse, safety-critical risks in autonomous driving. CARRL consists of two interacting components: a risk exposure adversary (REA) and a risk-targeted robust agent (RTRA). We model the interaction between the REA and RTRA as a general-sum game, allowing the REA to focus on exposing safety-critical failures (e.g., collisions) while the RTRA learns to balance safety with driving efficiency. The REA employs a decoupled optimization mechanism to better identify and exploit sparse safety-critical moments under a constrained budget. However, such focused attacks inevitably result in a scarcity of adversarial data. The RTRA copes with this scarcity by jointly leveraging benign and adversarial experiences via a dual replay buffer and enforces policy consistency under perturbations to stabilize behavior. Experimental results demonstrate that our approach reduces the collision rate by at least 22.66% across all cases compared to state-of-the-art baseline methods.
💡 Research Summary
The paper tackles a fundamental obstacle to deploying reinforcement‑learning (RL) based autonomous driving (AD) systems in the real world: vulnerability to sparse, safety‑critical perturbations. Existing adversarial training methods treat the interaction between the driver policy and an adversary as a zero‑sum game with continuous attacks, which ignores two key realities. First, safety‑critical events (e.g., collisions) are rare compared with the total driving time, so an adversary that spreads its limited budget uniformly generates little useful training data. Second, the objectives of the driver and the attacker are not perfectly opposed; the driver must balance collision avoidance with efficiency, while the attacker only cares about exposing failures.
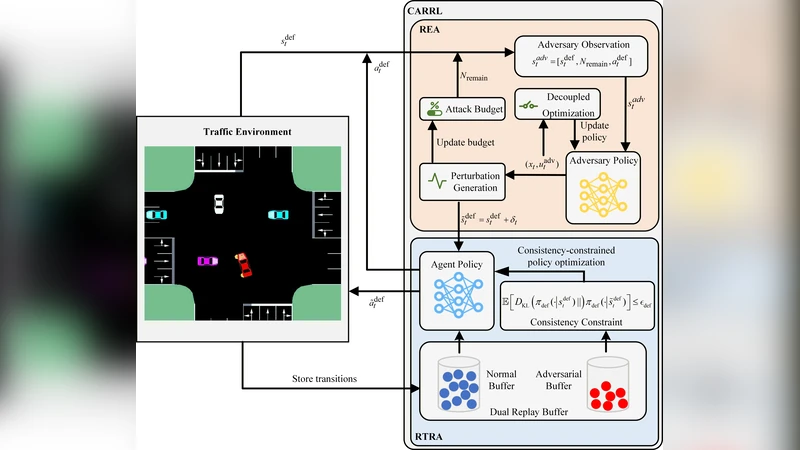
To address these gaps, the authors propose Criticality‑Aware Robust Reinforcement Learning (CARRL), a novel framework that models the driver–adversary interaction as a general‑sum game. The game comprises two agents: a Risk Exposure Adversary (REA) and a Risk‑Targeted Robust Agent (RTRA). The REA’s reward is defined solely by the probability of causing a safety‑critical failure, whereas the RTRA receives a weighted sum of safety, speed, and fuel‑efficiency rewards. This formulation allows each side to pursue its own goal without forcing a strict adversarial payoff structure.
The REA operates under a strict budget (e.g., limited number of perturbations per episode). It employs a decoupled two‑stage optimization. In the first stage, the current policy’s value function and a learned risk predictor are used to assign a “criticality score” to every state‑action pair. The top‑k most critical moments are selected as candidate attack points. In the second stage, the adversary optimizes the magnitude and type of perturbation (sensor noise, dynamics parameter shifts, environmental changes) for each candidate, maximizing the predicted collision likelihood while respecting the overall budget. This focused, spike‑type attack strategy efficiently uncovers the few moments where the policy is most vulnerable, but consequently yields a very small set of adversarial transitions.
To compensate for the scarcity of adversarial data, the RTRA introduces a dual replay buffer architecture. One buffer stores benign experiences collected from standard driving simulations; the other stores the REA‑generated adversarial experiences. During training, mini‑batches are sampled from both buffers in a balanced fashion, ensuring that the policy learns from both normal and perturbed distributions. In addition, a policy‑consistency regularizer is added to the loss: for a given original observation o and its perturbed counterpart o′, the KL‑divergence (or L2 distance) between the action distributions πθ(o) and πθ(o′) is penalized. This term prevents the policy from over‑reacting to rare perturbations, stabilizes learning, and encourages smooth behavior across the two data regimes.
Experiments are conducted in the CARLA simulator across a suite of challenging scenarios—including intersections, lane changes, pedestrian avoidance, and sudden braking. CARRL is benchmarked against several state‑of‑the‑art baselines: standard Adversarial RL, Robust Adversarial Reinforcement Learning (RARL), Risk‑Sensitive RL, and recent Distributional Robust RL methods. Evaluation metrics include collision rate, average travel time, fuel consumption, and policy variance. Across all scenarios, CARRL achieves at least a 22.66 % reduction in collision rate relative to the strongest baseline, while incurring less than a 3 % penalty in efficiency metrics. Ablation studies confirm that (a) replacing the general‑sum formulation with a zero‑sum game degrades safety gains to under 15 %, and (b) removing either the dual‑buffer mechanism or the consistency regularizer leads to unstable training and higher collision frequencies.
The contributions are fourfold: (1) explicit modeling of safety‑critical sparsity via a general‑sum game, (2) a budget‑aware, decoupled adversarial attack algorithm that isolates high‑risk moments, (3) a dual‑buffer replay system combined with a consistency loss to make efficient use of scarce adversarial data, and (4) empirical evidence that these design choices yield substantial safety improvements without sacrificing driving performance.
Limitations are acknowledged. All experiments are simulation‑based; real‑world sensor noise, actuator latency, and unmodeled dynamics may affect transferability. Moreover, the REA relies on a pre‑trained risk predictor; if this predictor is inaccurate, the adversary may miss critical moments. Future work should explore online risk‑model updates, real‑vehicle validation, and extensions to multi‑agent traffic environments.
In summary, CARRL offers a principled, practically viable pathway to endow RL‑driven autonomous vehicles with robust, safety‑aware behavior by focusing adversarial training on the rare but catastrophic events that matter most.
Comments & Academic Discussion
Loading comments...
Leave a Comment