📝 Original Info
- Title: Cost-Efficient Cross-Lingual Retrieval-Augmented Generation for Low-Resource Languages: A Case Study in Bengali Agricultural Advisory
- ArXiv ID: 2601.02065
- Date: 2026-01-05
- Authors: Researchers from original ArXiv paper
📝 Abstract
Access to reliable agricultural advisory remains limited in many developing regions due to a persistent language barrier: authoritative agricultural manuals are predominantly written in English, while farmers primarily communicate in low-resource local languages such as Bengali. Although recent advances in Large Language Models (LLMs) enable natural language interaction, direct generation in low-resource languages often exhibits poor fluency and factual inconsistency, while cloudbased solutions remain cost-prohibitive. This paper presents a cost-efficient, cross-lingual Retrieval-Augmented Generation (RAG) framework for Bengali agricultural advisory that emphasizes factual grounding and practical deployability. The proposed system adopts a translation-centric architecture in which Bengali user queries are translated into English, enriched through domain-specific keyword injection to align colloquial farmer terminology with scientific nomenclature, and answered via dense vector retrieval over a curated corpus of English agricultural manuals (FAO, IRRI). The generated English response is subsequently translated back into Bengali to ensure accessibility. The system is implemented entirely using open-source models and operates on consumer-grade hardware without reliance on paid APIs. Experimental evaluation demonstrates reliable sourcegrounded responses, robust rejection of out-of-domain queries, and an average end-to-end latency below 20 seconds. The results indicate that cross-lingual retrieval combined with controlled translation offers a practical and scalable solution for agricultural knowledge access in low-resource language settings.
💡 Deep Analysis
Deep Dive into Cost-Efficient Cross-Lingual Retrieval-Augmented Generation for Low-Resource Languages: A Case Study in Bengali Agricultural Advisory.
Access to reliable agricultural advisory remains limited in many developing regions due to a persistent language barrier: authoritative agricultural manuals are predominantly written in English, while farmers primarily communicate in low-resource local languages such as Bengali. Although recent advances in Large Language Models (LLMs) enable natural language interaction, direct generation in low-resource languages often exhibits poor fluency and factual inconsistency, while cloudbased solutions remain cost-prohibitive. This paper presents a cost-efficient, cross-lingual Retrieval-Augmented Generation (RAG) framework for Bengali agricultural advisory that emphasizes factual grounding and practical deployability. The proposed system adopts a translation-centric architecture in which Bengali user queries are translated into English, enriched through domain-specific keyword injection to align colloquial farmer terminology with scientific nomenclature, and answered via dense vector retrieva
📄 Full Content
Cost-Efficient Cross-Lingual Retrieval-Augmented
Generation for Low-Resource Languages: A Case
Study in Bengali Agricultural Advisory
1st Md. Asif Hossain
Dept. of Computer Science and Engineering
East West University
Dhaka, Bangladesh
asifhossain8612@gmail.com
3rdMantasha Rahman Mahi
Dept. of Computer Science and Engineering
East West University
Dhaka, Bangladesh
mantashamahi11@gmail.com
2nd Nabil Subhan
Dept. of Computer Science and Engineering
East West University
Dhaka, Bangladesh
nabilsubhan861@gmail.com
4th Jannatul Ferdous Nabila
Dept. of Computer Science and Engineering
East West University
Dhaka, Bangladesh
jannatulferdousnabila1@gmail.com
Abstract—Access to reliable agricultural advisory remains
limited in many developing regions due to a persistent language
barrier: authoritative agricultural manuals are predominantly
written in English, while farmers primarily communicate in
low-resource local languages such as Bengali. Although recent
advances in Large Language Models (LLMs) enable natural
language interaction, direct generation in low-resource languages
often exhibits poor fluency and factual inconsistency, while cloud-
based solutions remain cost-prohibitive.
This paper presents a cost-efficient, cross-lingual Retrieval-
Augmented Generation (RAG) framework for Bengali agricul-
tural advisory that emphasizes factual grounding and practical
deployability. The proposed system adopts a translation-centric
architecture in which Bengali user queries are translated into
English, enriched through domain-specific keyword injection to
align colloquial farmer terminology with scientific nomenclature,
and answered via dense vector retrieval over a curated corpus
of English agricultural manuals (FAO, IRRI). The generated
English response is subsequently translated back into Bengali
to ensure accessibility.
The system is implemented entirely using open-source models
and operates on consumer-grade hardware without reliance on
paid APIs. Experimental evaluation demonstrates reliable source-
grounded responses, robust rejection of out-of-domain queries,
and an average end-to-end latency below 20 seconds. The results
indicate that cross-lingual retrieval combined with controlled
translation offers a practical and scalable solution for agricultural
knowledge access in low-resource language settings.
Index Terms—Retrieval-Augmented Generation (RAG), Cross-
Lingual NLP, Low-Resource Languages, Bengali, Agricultural
Advisory, Quantization, Large Language Models (LLMs)
I. INTRODUCTION
Agriculture plays a vital role in developing countries such
as Bangladesh, where millions of people depend on farming
for food security and income. International organizations in-
cluding the Food and Agriculture Organization (FAO) and the
International Rice Research Institute (IRRI) publish detailed
agricultural manuals containing scientifically validated guid-
ance on crop diseases, fertilizer usage, and best practices [1],
[2]. However, a major accessibility challenge remains: these
manuals are predominantly written in English and distributed
as static PDF documents. For smallholder farmers who pri-
marily communicate in Bengali, this information is effectively
inaccessible.
Recent advances in Large Language Models (LLMs) have
enabled natural language interfaces for information access.
However, directly applying standard LLMs for Bengali agri-
cultural advisory presents significant limitations. Most high-
performing models are trained primarily on English data,
resulting in poor grammatical quality and factual inconsisten-
cies in Bengali outputs [3]. In addition, commercial cloud-
based LLM services are often cost-prohibitive for low-cost
rural deployment. More critically, generative models operating
without external grounding are prone to hallucinations, which
can lead to unsafe recommendations in agriculture-related
decision-making [4].
Retrieval-Augmented Generation (RAG) [5] has been pro-
posed as a solution to reduce hallucinations by grounding
responses in authoritative documents. In a RAG system, the
model retrieves relevant information from trusted sources be-
fore generating an answer. While effective, most existing RAG
frameworks are designed for English-language use or require
high computational resources, limiting their applicability in
low-resource linguistic and deployment settings [6].
In the Bangladeshi agricultural context, an additional chal-
lenge arises from a pronounced vocabulary gap. Farmers
frequently use local or colloquial terms to describe crop dis-
eases and symptoms (e.g., “Magra”), whereas official manuals
rely on scientific terminology (e.g., “Stem Borer”) [7]. This
mismatch prevents standard retrieval systems from effectively
arXiv:2601.02065v1 [cs.CL] 5 Jan 2026
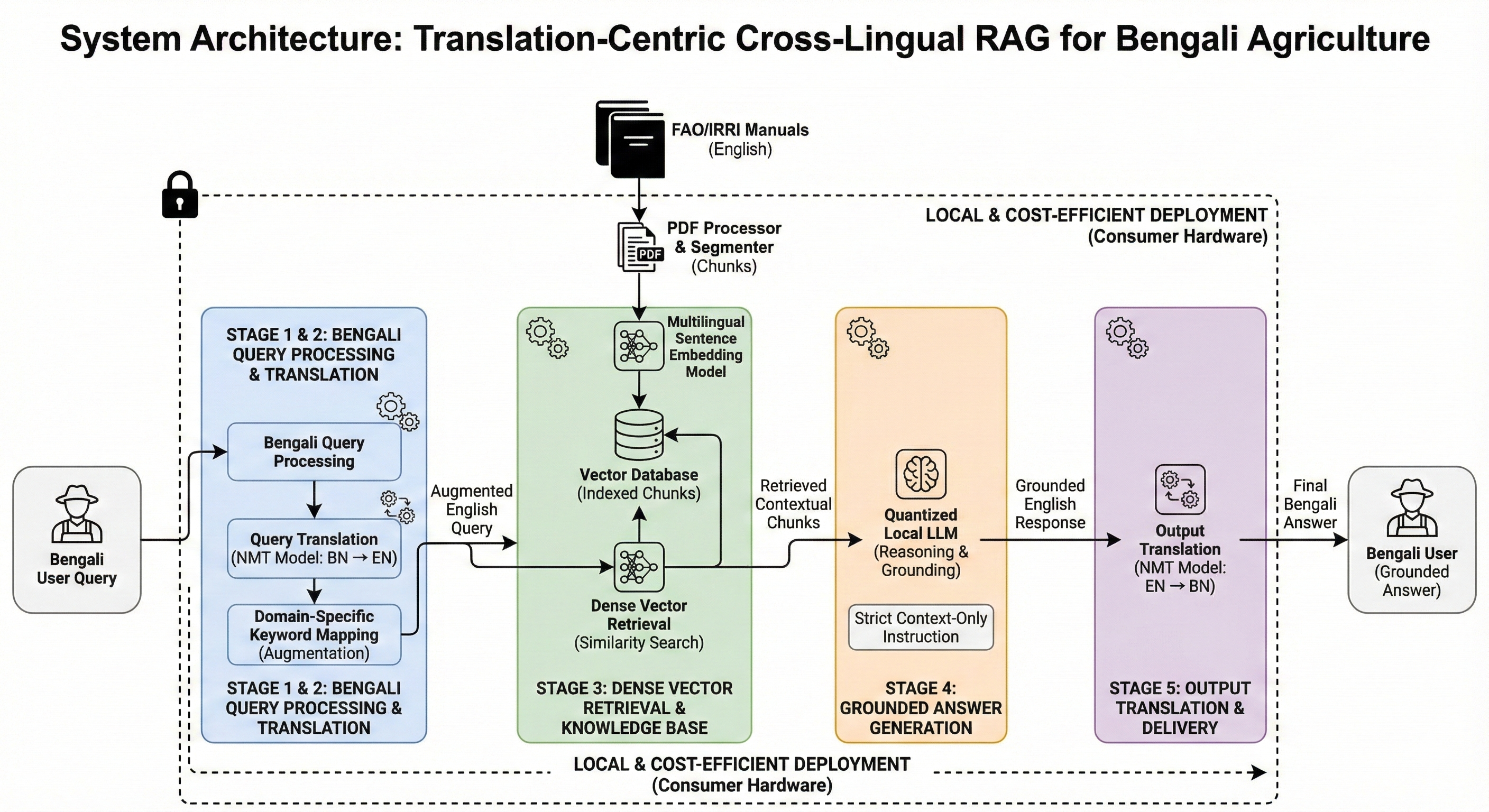
Fig. 1. System Architecture of the proposed Translation-Centric Cross-Lingual RAG Pipeline. The system processes Bengali queries by translating them to
English, enriching them with domain-specific keywords, and retrieving relevant inform
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.