📝 Original Info
- Title: Reading Between the Lines: Deconfounding Causal Estimates using Text Embeddings and Deep Learning
- ArXiv ID: 2601.01511
- Date: 2026-01-04
- Authors: Researchers from original ArXiv paper
📝 Abstract
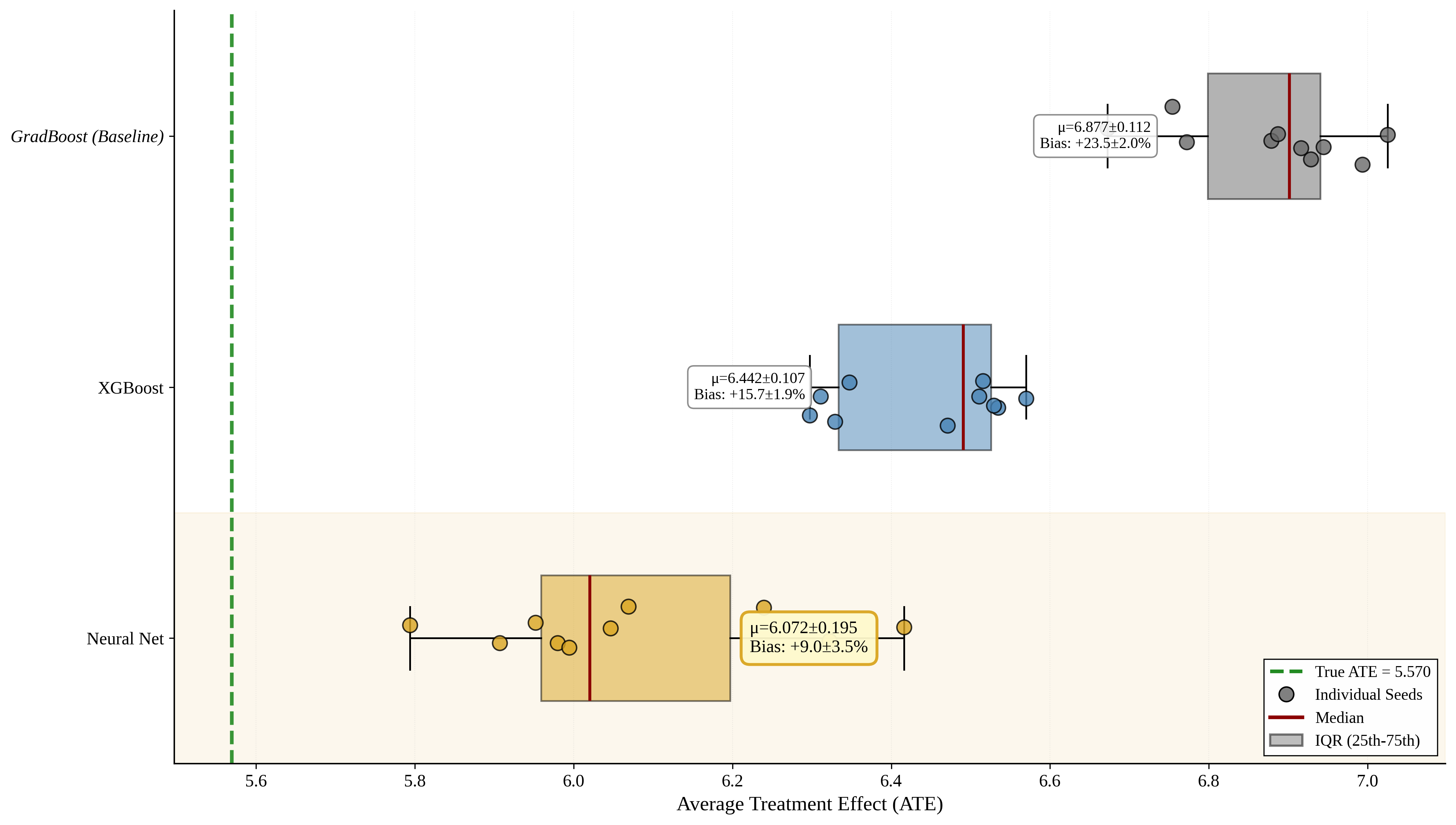
Estimating causal treatment effects in observational settings is frequently compromised by selection bias arising from unobserved confounders. While traditional econometric methods struggle when these confounders are orthogonal to structured covariates, high-dimensional unstructured text often contains rich proxies for these latent variables. This study proposes a Neural Network-Enhanced Double Machine Learning (DML) framework designed to leverage text embeddings for causal identification. Using a rigorous synthetic benchmark, we demonstrate that unstructured text embeddings capture critical confounding information that is absent from structured tabular data. However, we show that standard tree-based DML estimators retain substantial bias (+24%) due to their inability to model the continuous topology of embedding manifolds. In contrast, our deep learning approach reduces bias to -0.86% with optimized architectures, effectively recovering the ground-truth causal parameter. These findings suggest that deep learning architectures are essential for satisfying the unconfoundedness assumption when conditioning on high-dimensional natural language data.
💡 Deep Analysis
Deep Dive into Reading Between the Lines: Deconfounding Causal Estimates using Text Embeddings and Deep Learning.
Estimating causal treatment effects in observational settings is frequently compromised by selection bias arising from unobserved confounders. While traditional econometric methods struggle when these confounders are orthogonal to structured covariates, high-dimensional unstructured text often contains rich proxies for these latent variables. This study proposes a Neural Network-Enhanced Double Machine Learning (DML) framework designed to leverage text embeddings for causal identification. Using a rigorous synthetic benchmark, we demonstrate that unstructured text embeddings capture critical confounding information that is absent from structured tabular data. However, we show that standard tree-based DML estimators retain substantial bias (+24%) due to their inability to model the continuous topology of embedding manifolds. In contrast, our deep learning approach reduces bias to -0.86% with optimized architectures, effectively recovering the ground-truth causal parameter. These finding
📄 Full Content
Reading Between the Lines: Deconfounding Causal
Estimates using Text Embeddings and Deep Learning
Ahmed Dawoud
Osama El-Shamy
December 2025
Abstract
Estimating causal treatment effects in observational settings is frequently compromised by selection
bias arising from unobserved confounders. While traditional econometric methods struggle when these
confounders are orthogonal to structured covariates, high-dimensional unstructured text often contains
rich proxies for these latent variables. This study proposes a Neural Network-Enhanced Double
Machine Learning (DML) framework designed to leverage text embeddings for causal identification.
Using a rigorous synthetic benchmark, we demonstrate that unstructured text embeddings capture critical
confounding information that is absent from structured tabular data. However, we show that standard
tree-based DML estimators retain substantial bias (+24%) due to their inability to model the continuous
topology of embedding manifolds.
In contrast, our deep learning approach reduces bias to -0.86%
with optimized architectures, effectively recovering the ground-truth causal parameter. These findings
suggest that deep learning architectures are essential for satisfying the unconfoundedness assumption
when conditioning on high-dimensional natural language data.
1
Introduction
The integration of unstructured data into econometric analysis represents one of the most promising frontiers
in causal inference. Social scientists increasingly recognize that high-dimensional text data—such as medical
notes, financial news, or employment histories—often contains precise proxies for latent variables that are
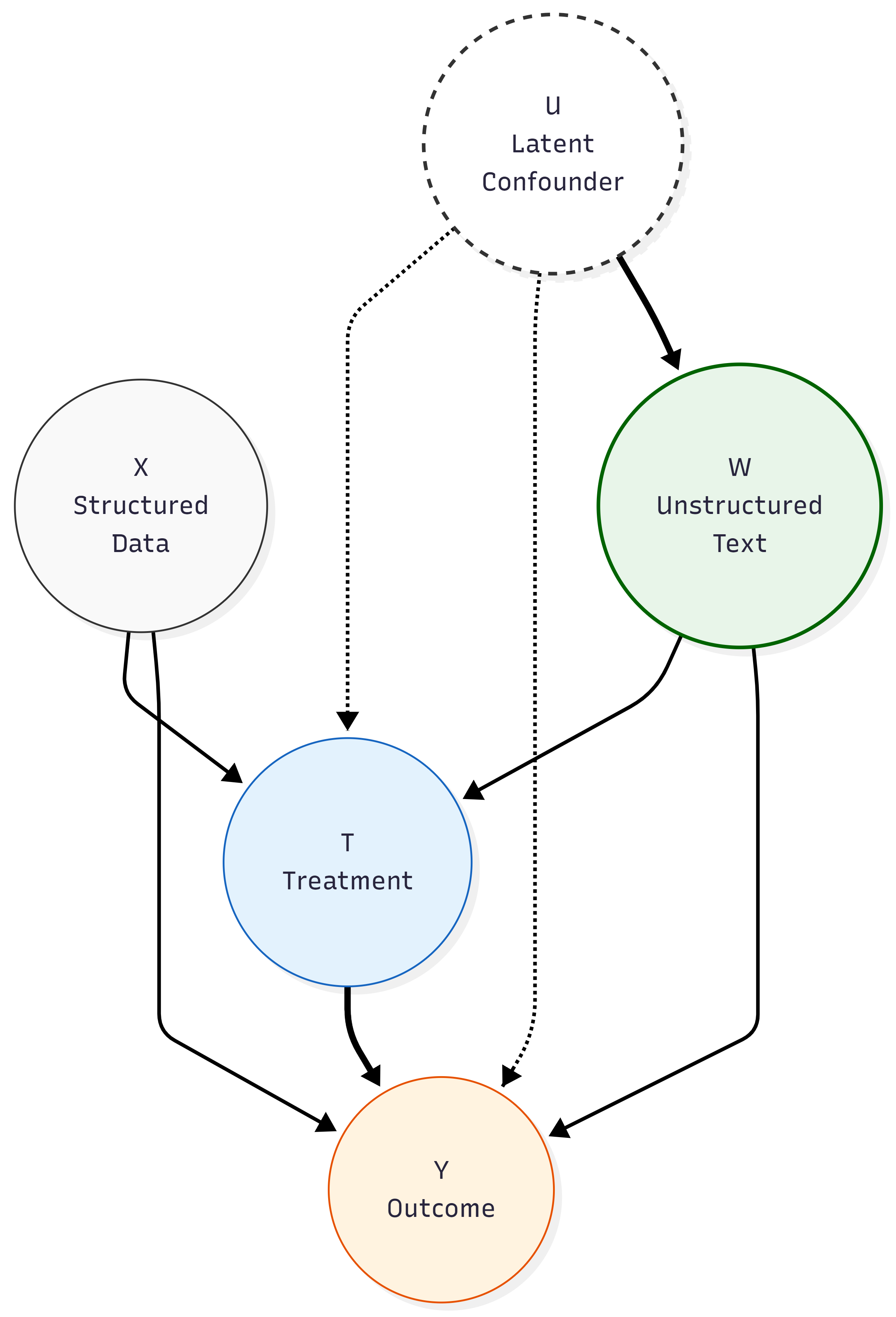
otherwise treated as “unobserved heterogeneity” in structured datasets. Theoretically, if these latent con-
founders can be recovered from text, the “selection on observables” assumption (unconfoundedness) can be
satisfied in settings where it would otherwise fail.
1
arXiv:2601.01511v1 [cs.AI] 4 Jan 2026
However, operationalizing text for causal adjustment presents a distinct topological challenge. Modern
Natural Language Processing (NLP) represents text as dense, continuous vectors (embeddings) situated
in high-dimensional manifolds. This dimensionality poses a fundamental problem for classical econometric
methods, which suffer from the curse of dimensionality. As Telea et al. (2024) argue, seeing patterns in such
high-dimensional spaces requires the synergy of dimensionality reduction and advanced machine learning;
traditional linear methods are insufficient to capture the complex, non-linear relationships inherent in these
dense representations.
Consequently, the use of Double Machine Learning (DML) (Chernozhukov et al., 2018) is not merely
a preference but a necessity. DML provides a robust theoretical apparatus for handling high-dimensional
controls via Neyman orthogonality. Yet, DML is practically agnostic regarding the choice of the nuisance
parameter learner.
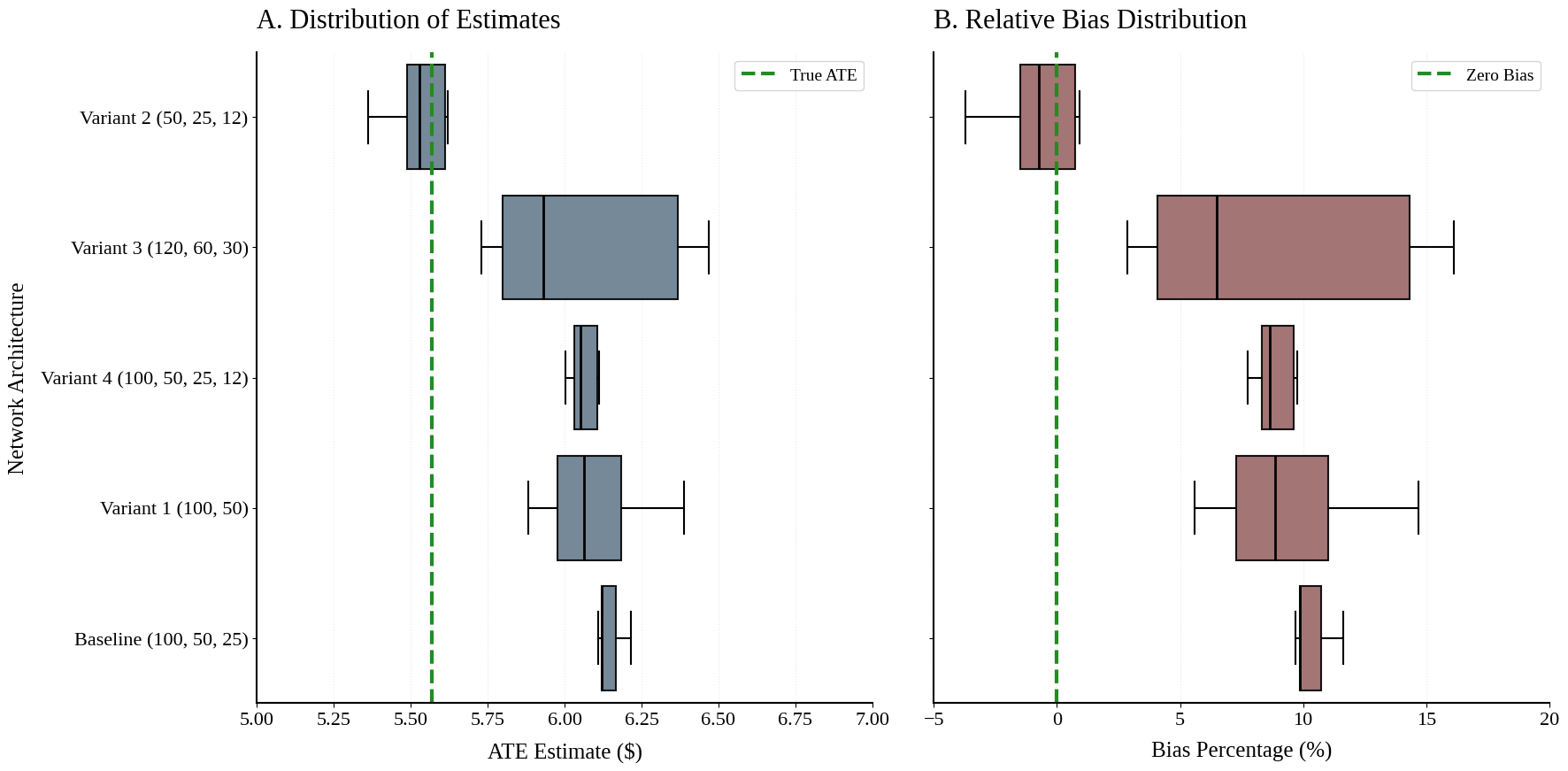
In applied practice, researchers often default to tree-based ensembles (e.g., Random
Forests, Gradient Boosting) due to their robustness on tabular data.
This paper argues that this default choice is methodologically suboptimal when applied to text embed-
dings. We posit the existence of an “Architecture Gap”: a topological mismatch between the orthogonal
splitting mechanisms of decision trees and the smooth, continuous geometry of embedding spaces. Because
decision trees approximate functions via step-wise constants, they are inefficient at modeling the diagonal
or non-linear decision boundaries characteristic of dense vector spaces. Consequently, even when the text
data contains sufficient information to de-confound a causal estimate, tree-based DML estimators may fail
to recover it due to approximation error.
We propose a Neural Network-Enhanced DML approach as the necessary solution. As universal
function approximators capable of modeling continuous manifolds (Hornik et al., 1989), Neural Networks are
theoretically superior candidates for the nuisance functions (E[Y |W] and E[T|W]) when W includes dense
embeddings.
To empirically validate this methodological claim, we construct a rigorous Monte Carlo simulation. By
generating a dataset where the ground-truth confounding signal is strictly encoded in unstructured text, we
isolate the performance of the estimator architecture. We demonstrate that the choice of machine learning
architecture is not merely a technical detail, but a fundamental condition for identification in the era of
high-dimensional text data.
The remainder of this paper proceeds as follows. We first establish the theoretical framework, defining the
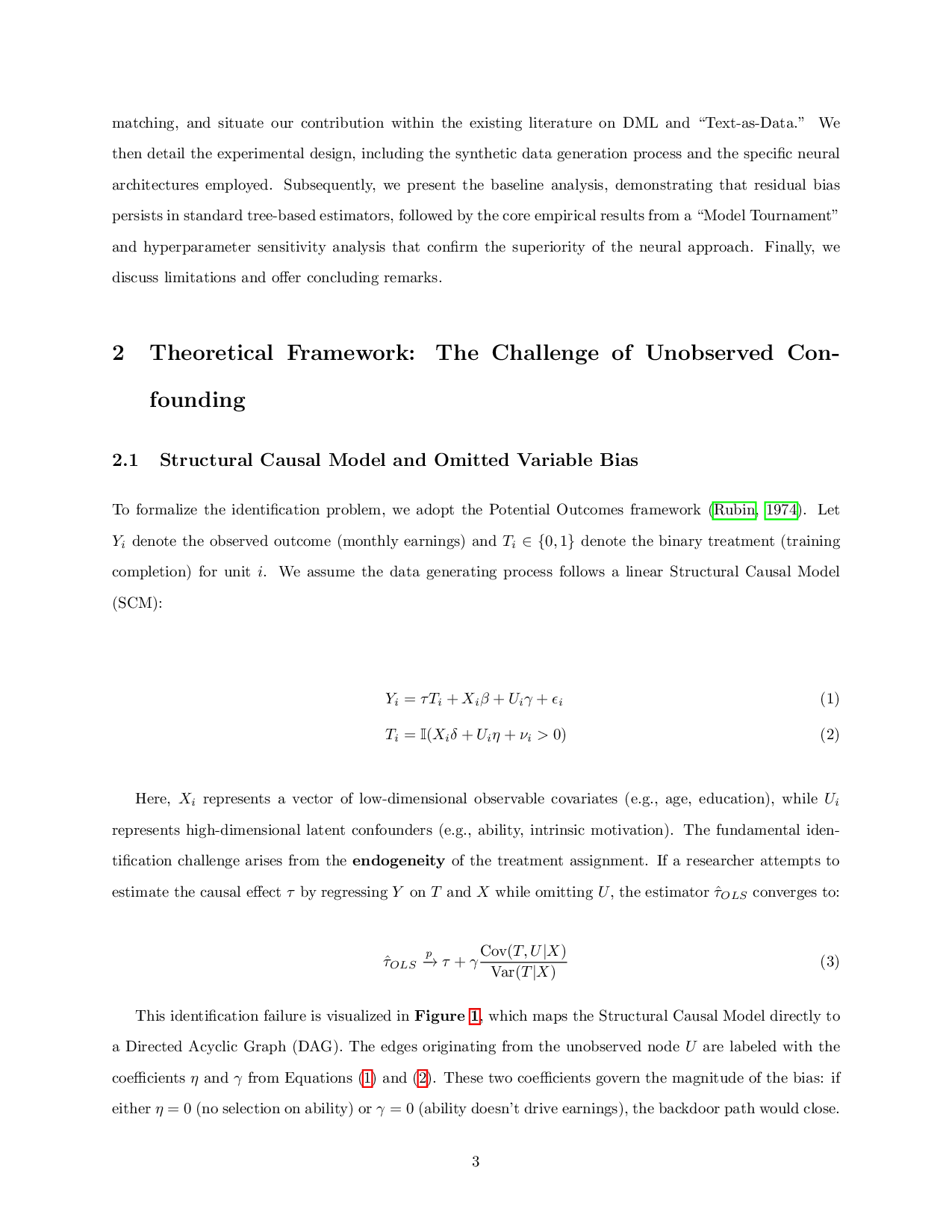
problem of unobserved confounding using Structural Causal Models and Directed Acyclic Graphs. Next, we
justify the use of high-dimensional embeddings as causal proxies, contrasting them with traditional lexical
2
matching, and situate our contribution within the existing literature on DML and “Text-as-Data.”
We
then detail the experimental design, includ
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.