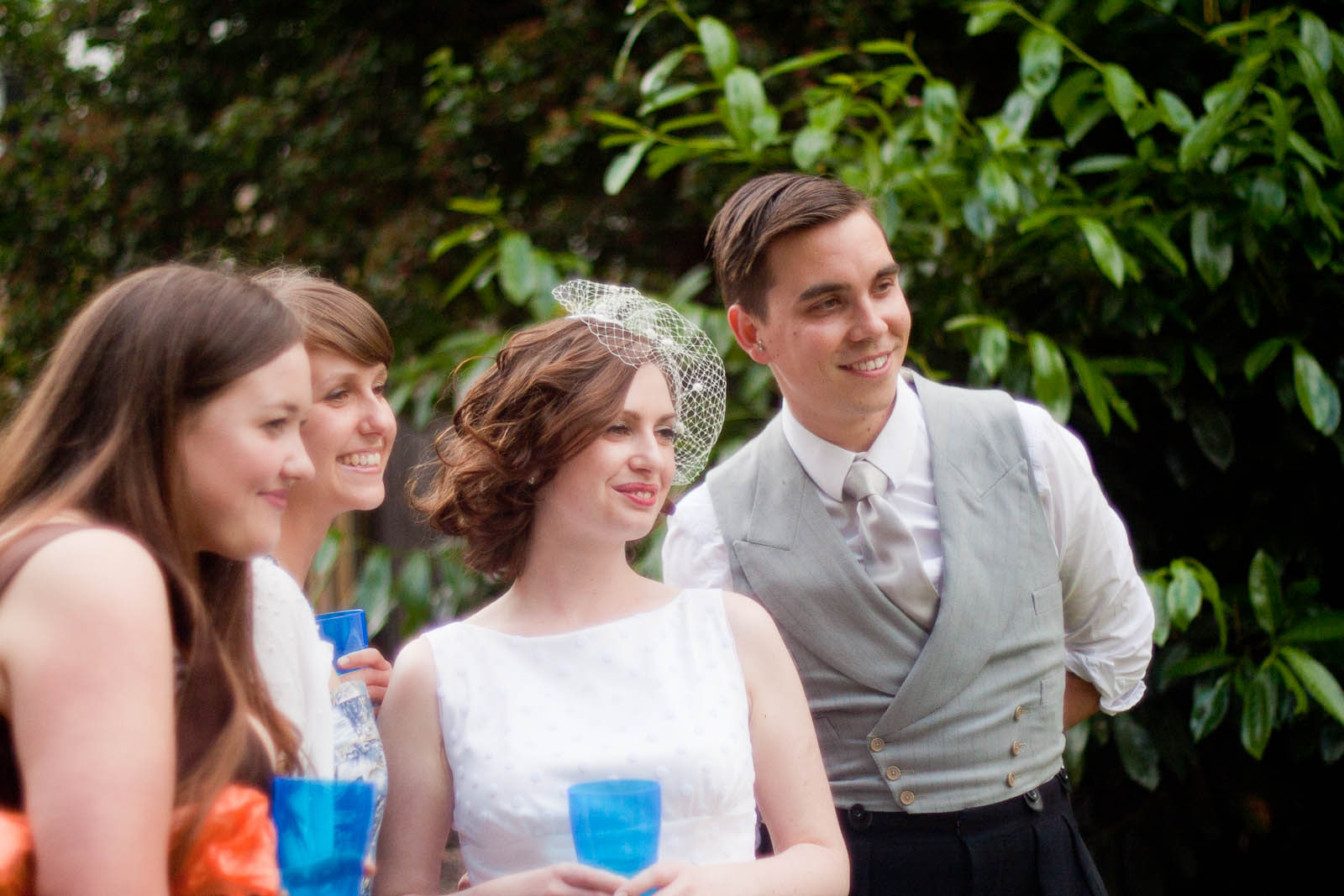📝 Original Info
- Title: SPoRC-VIST: A Benchmark for Evaluating Generative Natural Narrative in Vision-Language Models
- ArXiv ID: 2601.01062
- Date: 2026-01-03
- Authors: ** Yunlin Zeng (Georgia Institute of Technology, yzeng@gatech.edu) **
📝 Abstract
Vision-Language Models (VLMs) have achieved remarkable success in descriptive tasks such as image captioning and visual question answering (VQA). However, their ability to generate engaging, long-form narratives-specifically multi-speaker podcast dialogues-remains under-explored and difficult to evaluate. Standard metrics like BLEU and ROUGE fail to capture the nuances of conversational naturalness, personality, and narrative flow, often rewarding safe, repetitive outputs over engaging storytelling. In this work, we present a novel pipeline for end-to-end visual podcast generation, and fine-tune a Qwen3-VL-32B model on a curated dataset of 4,000 image-dialogue pairs. Crucially, we use a synthetic-to-real training strategy: we train on high-quality podcast dialogues from the Structured Podcast Research Corpus (SPoRC) paired with synthetically generated imagery, and evaluate on real-world photo sequences from the Visual Storytelling Dataset (VIST). This rigorous setup tests the model's ability to generalize from synthetic training data to real-world visual domains. We propose a comprehensive evaluation framework that moves beyond textual overlap, and use AI-as-a-judge (Gemini 3 Pro, Claude Opus 4.5, GPT 5.2) and novel style metrics (average turn length, speaker switch rate) to assess quality. Our experiments demonstrate that our fine-tuned 32B model significantly outperforms a 235B base model in conversational naturalness (>80% win rate) and narrative depth (+50% turn length), while maintaining identical visual grounding capabilities (CLIPScore: 20.39).
💡 Deep Analysis
Deep Dive into SPoRC-VIST: A Benchmark for Evaluating Generative Natural Narrative in Vision-Language Models.
Vision-Language Models (VLMs) have achieved remarkable success in descriptive tasks such as image captioning and visual question answering (VQA). However, their ability to generate engaging, long-form narratives-specifically multi-speaker podcast dialogues-remains under-explored and difficult to evaluate. Standard metrics like BLEU and ROUGE fail to capture the nuances of conversational naturalness, personality, and narrative flow, often rewarding safe, repetitive outputs over engaging storytelling. In this work, we present a novel pipeline for end-to-end visual podcast generation, and fine-tune a Qwen3-VL-32B model on a curated dataset of 4,000 image-dialogue pairs. Crucially, we use a synthetic-to-real training strategy: we train on high-quality podcast dialogues from the Structured Podcast Research Corpus (SPoRC) paired with synthetically generated imagery, and evaluate on real-world photo sequences from the Visual Storytelling Dataset (VIST). This rigorous setup tests the model’s a
📄 Full Content
SPoRC-VIST: A Benchmark for Evaluating Generative Natural Narrative in
Vision-Language Models
Yunlin Zeng
Georgia Institute of Technology
yzeng@gatech.edu
Abstract
Vision-Language Models (VLMs) have achieved remark-
able success in descriptive tasks such as image captioning
and visual question answering (VQA). However, their abil-
ity to generate engaging, long-form narratives—specifically
multi-speaker podcast dialogues—remains under-explored
and difficult to evaluate. Standard metrics like BLEU and
ROUGE fail to capture the nuances of conversational nat-
uralness, personality, and narrative flow, often rewarding
safe, repetitive outputs over engaging storytelling. In this
work, we present a novel pipeline for end-to-end visual pod-
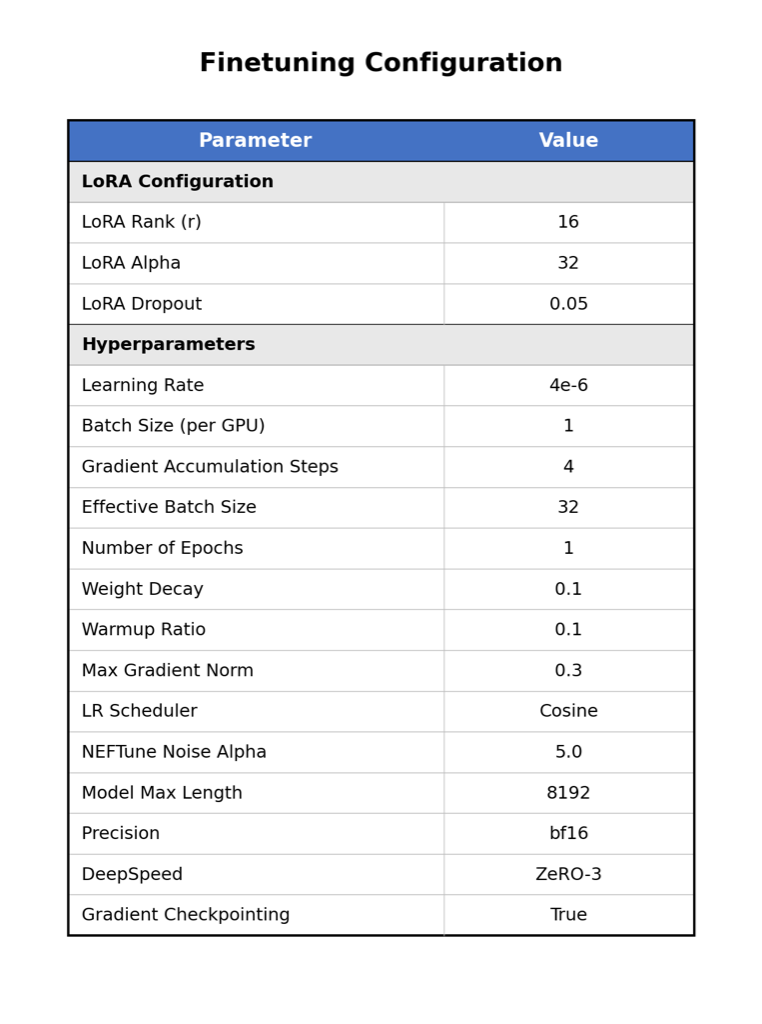
cast generation, and fine-tune a Qwen3-VL-32B model on a
curated dataset of 4,000 image-dialogue pairs. Crucially,
we use a synthetic-to-real training strategy: we train on
high-quality podcast dialogues from the Structured Podcast
Research Corpus (SPoRC) paired with synthetically gener-
ated imagery, and evaluate on real-world photo sequences
from the Visual Storytelling Dataset (VIST). This rigor-
ous setup tests the model’s ability to generalize from syn-
thetic training data to real-world visual domains. We pro-
pose a comprehensive evaluation framework that moves be-
yond textual overlap, and use AI-as-a-judge (Gemini 3 Pro,
Claude Opus 4.5, GPT 5.2) and novel style metrics (aver-
age turn length, speaker switch rate) to assess quality. Our
experiments demonstrate that our fine-tuned 32B model sig-
nificantly outperforms a 235B base model in conversational
naturalness (>80% win rate) and narrative depth (+50%
turn length), while maintaining identical visual grounding
capabilities (CLIPScore: 20.39).
1. Introduction
The field of Computer Vision has rapidly evolved from pas-
sive perception (classification, detection) to active genera-
tion. Modern Vision-Language Models (VLMs) are capa-
ble of processing complex visual inputs and generating de-
tailed textual descriptions. However, a significant gap re-
mains between description and storytelling. While state-
of-the-art models can accurately identify “a white bus in a
forest,” they often struggle to weave that visual cue into an
engaging, multi-turn conversation that exhibits personality,
humor, and natural flow.
This limitation is partly due to training data—most
VLMs are trained on caption-heavy datasets like LAION [1]
or COCO [2], which prioritize factual brevity—and partly
due to the lack of appropriate evaluation metrics for
narrative quality.
Standard n-gram metrics (BLEU [3],
ROUGE [4]) penalize creativity and linguistic diversity, ef-
fectively encouraging models to produce safe, repetitive,
and robotic outputs. As Generative AI moves into creative
domains, assessing the “quality” of a generated narrative
requires new frameworks that account for hallucinations of
personality, conversational dynamics, and prosodic struc-
ture.
In this paper, we address the challenge of visual podcast
generation: transforming a sequence of images into a coher-
ent, entertaining podcast script between two distinct hosts.
Figure 1 illustrates a typical input from the Visual Story-
telling (VIST) dataset [5] (five images, each with a simple
one-sentence caption), which we aim to transform into rich
multi-turn dialogues.
We introduce the SPoRC-VIST Benchmark, a frame-
work that uses the abundance of high-quality text data by
pairing it with synthetic visuals for training, while test-
ing on real-world photographic sequences. Our contribu-
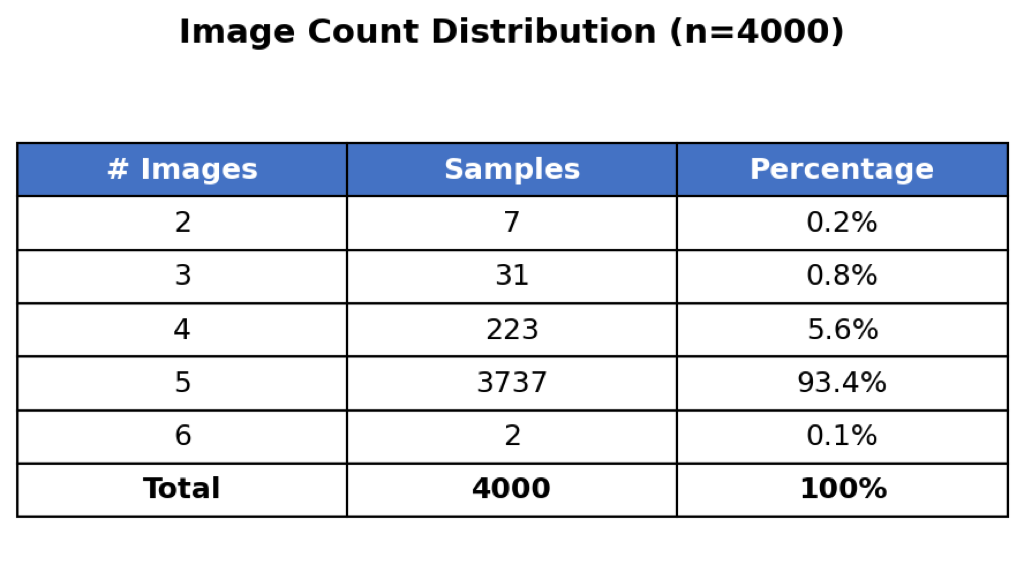
tions are threefold: (1) We curate a dataset of 4,000 visual-
dialogue pairs and fine-tune a parameter-efficient Qwen3-
VL-32B model using LoRA to perform style transfer from
“captioner” to “podcaster.” (2) We propose a new set of
style-aware metrics (turn length, switch rate) and an AI-
as-a-Judge protocol to evaluate “Hallucination of Person-
ality” and conversational naturalness. (3) We demonstrate
that a smaller, fine-tuned model (32B) can outperform a
massive base model (235B) in narrative quality without
degrading visual grounding performance, and validate the
effectiveness of our synthetic-to-real generalization strat-
egy. Code to reproduce data generation and model train-
ing is available at https://github.com/Yunlin-
1
arXiv:2601.01062v1 [cs.LG] 3 Jan 2026
Zeng/visual-podcast-VLM.
2. Related Work
2.1. Visual Storytelling
The task of generating narratives from image sequences
was formalized by the VIST dataset [5]. While VIST es-
tablished sequential visual storytelling, its annotations con-
sist of a sequence of descriptive single sentences per im-
age. Other approaches have focused on generating a sin-
gle, paragraph-length story for a set of images. Our work
diverges from these fields by structuring the narrative as a
multi-speaker dialogue, a significantly more complex task
that requires modeling conversational flow, personality, and
inter-speaker dynamics, which are not the primary focus
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.