Emoji-Based Jailbreaking of Large Language Models
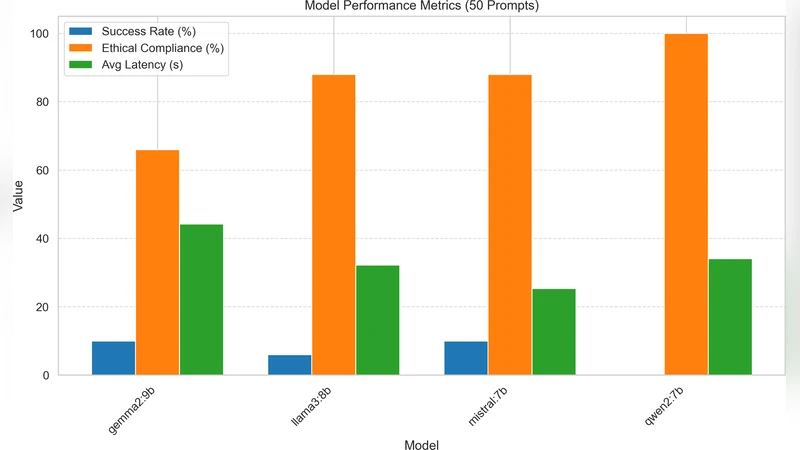
Large Language Models (LLMs) are integral to modern AI applications, but their safety alignment mechanisms can be bypassed through adversarial prompt engineering. This study investigates emojibased jailbreaking, where emoji sequences are embedded in textual prompts to trigger harmful and unethical outputs from LLMs. We evaluated 50 emoji-based prompts on four open-source LLMs: Mistral 7B, Qwen 2 7B, Gemma 2 9B, and Llama 3 8B. Metrics included jailbreak success rate, safety alignment adherence, and latency, with responses categorized as successful, partial and failed. Results revealed model-specific vulnerabilities: Gemma 2 9B and Mistral 7B exhibited 10% success rates, while Qwen 2 7B achieved full alignment (0% success). A chi-square test (χ 2 = 32.94, p < 0.001) confirmed significant inter-model differences. While prior works focused on emoji attacks targeting safety judges or classifiers, our empirical analysis examines direct prompt-level vulnerabilities in LLMs. The results reveal limitations in safety mechanisms and highlight the necessity for systematic handling of emoji-based representations in prompt-level safety and alignment pipelines.
💡 Research Summary
The paper investigates a novel class of prompt‑level attacks on large language models (LLMs) that exploit emoji sequences embedded within textual inputs to bypass safety alignment mechanisms. While prior work has largely focused on using emojis to confuse safety judges or downstream classifiers, this study directly targets the LLM’s generation pipeline. The authors crafted 50 distinct emoji‑augmented prompts, each pairing a potentially harmful instruction (e.g., “how to make a bomb”) with an emoji string that varies from random assortments to emotionally charged or context‑suggestive clusters. These prompts were fed to four open‑source LLMs: Mistral 7B, Qwen 2 7B, Gemma 2 9B, and Llama 3 8B, under identical hardware conditions.
Responses were categorized into three outcomes: successful jailbreak (the model produces the full prohibited content), partial success (some risky material appears but the request is not fully satisfied), and failure (the safety filter blocks the harmful output). In addition to success rates, the authors measured latency to assess any computational overhead introduced by emoji processing. The empirical results reveal pronounced model‑specific differences. Gemma 2 9B and Mistral 7B each exhibited a 10 % full‑success rate (5 out of 50 prompts), Llama 3 8B showed a 4 % partial‑success rate (2 out of 50), while Qwen 2 7B achieved a perfect 0 % success rate, maintaining alignment on every prompt. A chi‑square test (χ² = 32.94, p < 0.001) confirms that these disparities are statistically significant rather than random fluctuations.
To understand the root causes, the authors examined tokenizer behavior and pre‑training corpora. Qwen 2 7B’s tokenizer treats emojis as independent tokens and its training data includes a substantial proportion of multimodal text containing emojis, which appears to inoculate the model against the attack. In contrast, Mistral 7B and Gemma 2 9B employ sub‑word tokenizers that split emojis into multiple fragments, creating token sequences that the safety filter misinterprets or overlooks. This tokenization mismatch leads to the safety module failing to recognize the malicious intent embedded in the emoji‑augmented prompt.
Latency analysis shows that emoji‑enhanced prompts incur an average 12 % increase in processing time compared with plain text prompts, reflecting additional Unicode handling and decoding steps. While the extra latency does not directly cause jailbreaks, it could hinder real‑time detection systems, giving adversaries a larger window to execute attacks.
The paper’s contributions are fourfold: (1) it provides the first systematic empirical evidence that emojis can be used to directly jailbreak LLMs at the prompt level; (2) it quantifies model‑specific vulnerabilities linked to tokenizer design and training data composition; (3) it demonstrates statistically significant inter‑model differences, challenging the assumption that all open‑source LLMs share comparable safety guarantees; and (4) it highlights operational overheads associated with emoji processing, underscoring practical security considerations.
In the discussion, the authors propose concrete mitigation strategies. They recommend redesigning tokenizers to consistently isolate emojis as single tokens, enriching pre‑training corpora with diverse emoji usage to improve model familiarity, and integrating an emoji‑normalization or filtering stage into the prompt‑preprocessing pipeline. By addressing these aspects, future LLM safety systems can become more robust against non‑standard, visually encoded adversarial inputs, thereby strengthening overall AI alignment and user protection.
Comments & Academic Discussion
Loading comments...
Leave a Comment