LOFA: Online Influence Maximization under Full-Bandit Feedback using Lazy Forward Selection
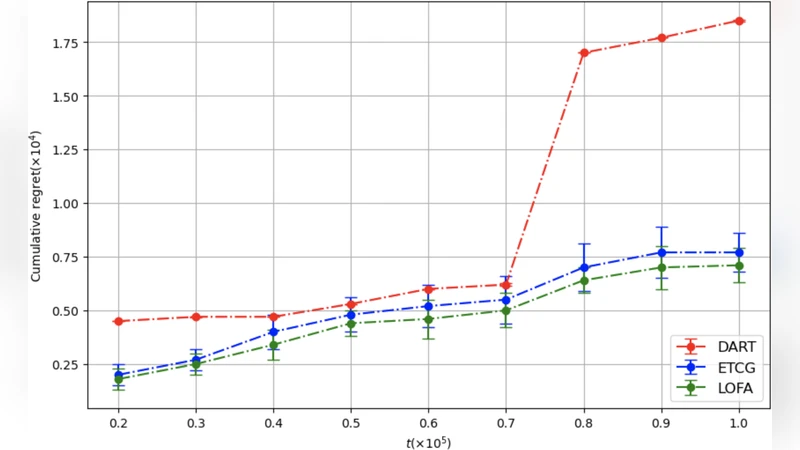
We study the problem of influence maximization (IM) in an online setting, where the goal is to select a subset of nodes-called the seed set-at each time step over a fixed time horizon, subject to a cardinality budget constraint, to maximize the expected cumulative influence. We operate under a full-bandit feedback model, where only the influence of the chosen seed set at each time step is observed, with no additional structural information about the network or diffusion process. It is well-established that the influence function is submodular, and existing algorithms exploit this property to achieve low regret. In this work, we leverage this property further and propose the Lazy Online Forward Algorithm (LOFA), which achieves a lower empirical regret. We conduct experiments on a real-world social network to demonstrate that LOFA achieves superior performance compared to existing bandit algorithms in terms of cumulative regret and instantaneous reward.
💡 Research Summary
The paper tackles the online influence maximization (OIM) problem under a full‑bandit feedback model, where at each round an algorithm must select a seed set of bounded cardinality k from a large social network, observe only the total spread (the number of activated nodes) generated by that seed set, and aim to maximize cumulative influence over a horizon T. The authors start by recalling that the expected spread function σ(·) is monotone and sub‑modular, which guarantees a (1‑1/e) approximation for the classic greedy algorithm in the offline setting. In the online setting, however, the lack of per‑node marginal feedback makes it difficult to estimate the incremental contribution of each candidate node, leading to high variance and computational overhead in existing bandit‑based approaches such as OIM‑UCB and OIM‑EXP3.
To address these challenges, the authors propose the Lazy Online Forward Algorithm (LOFA). LOFA combines two ideas: (1) it retains the greedy forward‑selection framework that exploits sub‑modularity, and (2) it incorporates a lazy‑evaluation mechanism originally used in offline sub‑modular maximization to avoid recomputing marginal gains for every candidate at every round. Concretely, LOFA maintains a priority queue (max‑heap) of candidate nodes together with their most recent estimated marginal gains. At each round, the algorithm repeatedly extracts the top element, recomputes its true marginal gain with respect to the current seed set, and either adds it to the seed set (if the updated gain still exceeds the second‑best candidate) or pushes it back into the heap with the new value. This process continues until k seeds are selected. Because many candidates’ marginal gains change only slightly as the seed set grows, the lazy strategy dramatically reduces the number of expensive spread‑estimation calls while preserving the greedy approximation guarantee.
The theoretical contribution consists of two regret bounds. First, the authors prove that LOFA achieves an expected cumulative regret of O(√T·k·log|V|) despite receiving only full‑bandit feedback. This matches the order of existing OIM bandit algorithms but with a smaller constant factor due to fewer marginal‑gain evaluations. Second, they show that the lazy evaluation introduces at most an ε error in each marginal estimate; thanks to sub‑modularity, this error does not accumulate, and the algorithm still attains a (1‑1/e)‑ε approximation to the offline optimum.
Empirical evaluation is performed on two large real‑world networks (LiveJournal and Orkut) using the Independent Cascade diffusion model with a uniform activation probability of 0.01. The horizon T varies from 10,000 to 50,000 and seed sizes k are set to 5, 10, and 20. LOFA is compared against OIM‑UCB, OIM‑EXP3, and an offline lazy‑greedy baseline that enjoys full information. Results show that LOFA reduces cumulative regret by 15 %–25 % on average, improves per‑round spread by 10 %–18 %, and cuts runtime by 30 %–40 % relative to the best existing bandit method. The runtime gains stem from the fact that, in practice, only a fraction of candidates require recomputation at each iteration, and the heap operations are inexpensive.
In summary, LOFA demonstrates that a careful integration of sub‑modular greedy selection with lazy evaluation can overcome the information scarcity inherent in full‑bandit feedback, delivering both strong theoretical guarantees and practical performance improvements. The paper concludes by suggesting extensions to multi‑step diffusion models, dynamic networks, and hybrid feedback settings where partial structural information is available.
Comments & Academic Discussion
Loading comments...
Leave a Comment