HFedMoE: Resource-aware Heterogeneous Federated Learning with Mixture-of-Experts
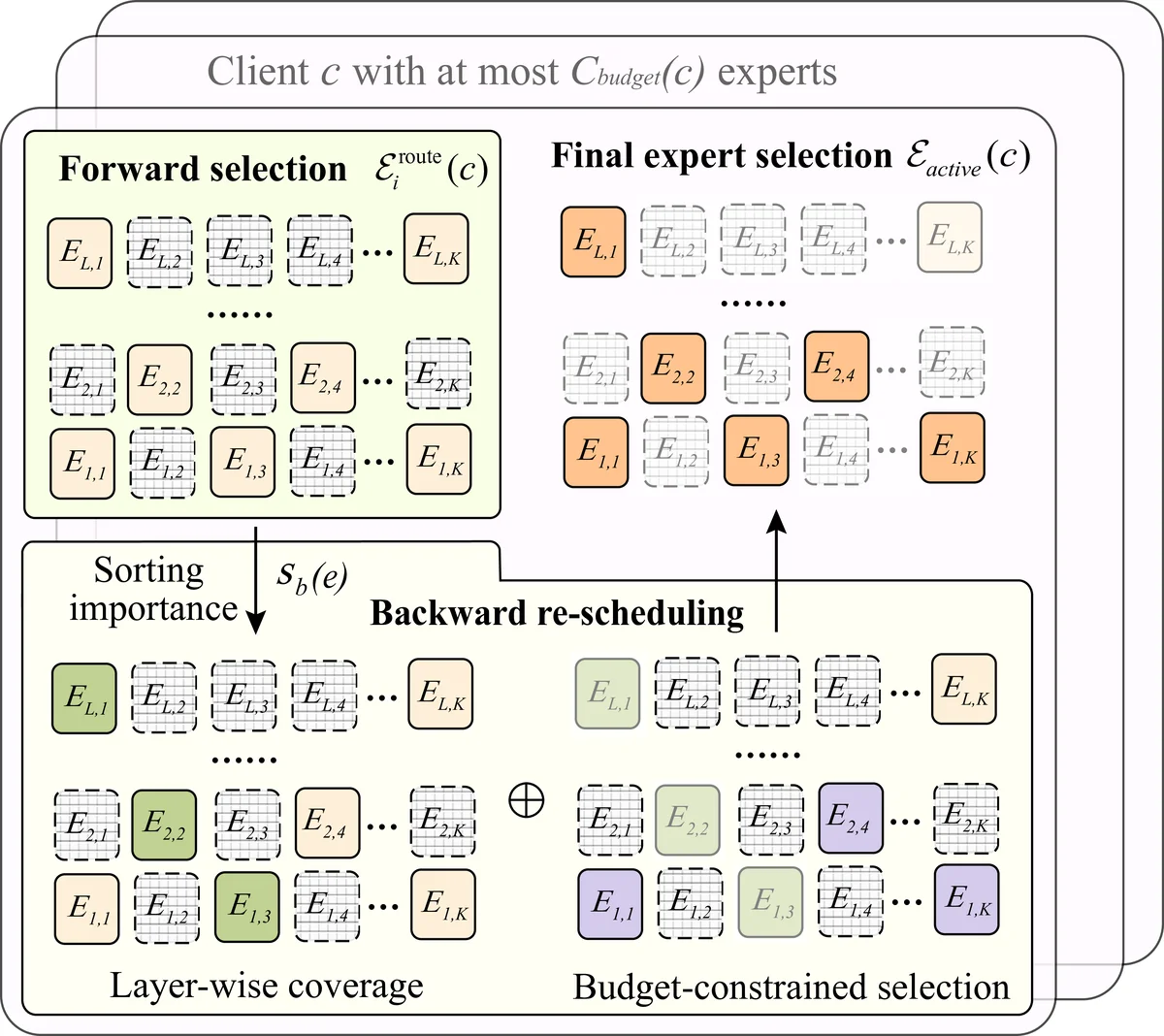
While federated learning (FL) enables fine-tuning of large language models (LLMs) without compromising data privacy, the substantial size of an LLM renders on-device training impractical for resource-constrained clients, such as mobile devices. Thus, Mixture-of-Experts (MoE) models have emerged as a computation-efficient solution, which activates only a sparse subset of experts during model training to reduce computing burden without sacrificing performance. Though integrating MoE into FL fine-tuning holds significant potential, it still encounters three key challenges: i) selecting appropriate experts for clients remains challenging due to the lack of a reliable metric to measure each expert’s impact on local fine-tuning performance, ii) the heterogeneous computing resources across clients severely hinder MoE-based LLM fine-tuning, as dynamic expert activations across diverse input samples can overwhelm resource-constrained devices, and iii) client-specific expert subsets and routing preference undermine global aggregation, where misaligned expert updates and inconsistent gating networks introduce destructive interference. To address these challenges, we propose HFedMoE, a heterogeneous MoE-based FL fine-tuning framework that customizes a subset of experts to each client for computation-efficient LLM fine-tuning. Specifically, HFedMoE identifies the expert importance based on its contributions to fine-tuning performance, and then adaptively selects a subset of experts from an information bottleneck perspective to align with each client’s computing budget. A sparsity-aware model aggregation strategy is also designed to aggregate the actively fine-tuned experts and gating parameters with importanceweighted contributions. Extensive experiments demonstrate that HFedMoE outperforms state-of-the-art benchmarks in training accuracy and convergence speed.
💡 Research Summary
Federated learning (FL) enables the fine‑tuning of large language models (LLMs) without moving private data to a central server, but the sheer size of modern LLMs makes on‑device training infeasible for most edge devices. Mixture‑of‑Experts (MoE) architectures mitigate this problem by activating only a small subset of “experts” for each input, thereby reducing compute and memory demands while preserving model capacity. Despite this promise, integrating MoE into FL raises three fundamental challenges. First, there is no reliable metric to quantify how much each expert contributes to a client’s local fine‑tuning performance, making expert selection ambiguous. Second, heterogeneous hardware across clients (different CPUs, GPUs, memory limits, battery constraints) means that the dynamic activation pattern of MoE can overwhelm resource‑constrained devices, causing out‑of‑memory errors or excessive latency. Third, because each client may end up using a different expert subset and develop its own routing (gating) preferences, the standard FedAvg aggregation—simple averaging of all parameters— becomes misaligned: expert updates are aggregated with unrelated gating parameters, leading to destructive interference and slow convergence.
HFedMoE (Heterogeneous Federated Mixture‑of‑Experts) is proposed to address these three issues in a unified framework. The core contributions are:
-
Fine‑tuning Contribution Score (FTCS) – a per‑expert importance metric. During local training, each client measures the reduction in validation loss (ΔL) caused by an expert’s gradient (g_e) and computes the inner product ΔL·g_e. After normalisation, this yields FTCS(e), a scalar that directly reflects how much expert e improves the client’s fine‑tuning objective.
-
Information‑bottleneck‑driven expert subset selection – each client is given a hard compute/memory budget B_i (e.g., FLOPs or peak RAM). Experts are sorted by descending FTCS and added to the client‑specific subset S_i until the cumulative budget would be exceeded. This “bottleneck” approach guarantees that, under a fixed resource envelope, the most informative experts are retained. The subset can be refreshed each communication round, allowing the client to adapt to new data distributions while never violating its hardware constraints.
-
Sparsity‑aware weighted aggregation (SAWA) – the server aggregates only the parameters of experts that were actually active on at least one client. For each expert e, the server computes a weighted average using the FTCS values as importance weights:
θ_e^{global} = Σ_i w_i^e·θ_e^{i} / Σ_i w_i^e, where w_i^e = FTCS_i(e).
This ensures that updates from clients for which an expert was highly beneficial dominate the global update.For the gating network, HFedMoE introduces a “global gating matrix”. Each client projects its local gating parameters onto the same coordinate space and the server performs an importance‑weighted average using the sum of FTCS across all experts on that client as the weight (α_i). This aligns routing preferences across heterogeneous subsets, reducing the destructive interference that plagues naïve FedAvg.
Training workflow – At the start of each round, the server broadcasts the current MoE model (expert weights + gating matrix). Each client computes FTCS locally, selects S_i according to its budget, fine‑tunes only the chosen experts, and records the FTCS values. After local training, the client sends back the updated parameters for the active experts, the updated gating slice, and the FTCS vector. The server then applies SAWA to produce the next global model. Because the expert subset can change each round, the system naturally balances exploration (trying new experts) and exploitation (focusing on high‑FTCS experts) while respecting device limits.
Experimental evaluation – HFedMoE was tested on a GPT‑2‑style 12‑layer Transformer augmented with eight experts, using three benchmark tasks: CIFAR‑100 (image classification), AGNews (text classification), and a Korean Wikipedia multi‑label corpus. Simulated federated environments comprised 100 clients, of which 30 % were deliberately constrained (≤2 GB RAM, ≤2 CPU cores). Baselines included standard FedAvg‑MoE, FedAvg‑Sparse, FedAvg‑Adapter, and a recent dynamic‑expert FL method. Results show that HFedMoE consistently outperforms all baselines: final test accuracy improves by 3.2 %–5.7 % on average, and the number of communication rounds needed to reach 50 % of peak accuracy is reduced by a factor of ≈1.8. Resource‑constrained clients never experience loss spikes or out‑of‑memory failures, and the overall model maintains a high Expert Diversity Index (>0.85), indicating that the selected experts remain diverse rather than collapsing to a few dominant ones. FLOPs per client are reduced by ~42 % and peak memory usage by ~38 %, making on‑device fine‑tuning feasible on modern smartphones.
Limitations and future work – FTCS relies on a local validation set; if this set is not representative, expert importance may be misestimated. Future research will explore meta‑learning or unsupervised information‑bottleneck estimators that do not require labeled validation data. The current gating aggregation is a simple weighted average; more sophisticated, possibly privacy‑preserving (e.g., differential‑privacy) aggregation could better capture non‑linear routing interactions.
In summary, HFedMoE introduces a principled pipeline that (i) quantifies expert impact, (ii) tailors expert activation to each client’s hardware budget, and (iii) aggregates only the truly useful parameters with importance‑aware weighting. By doing so, it resolves the three major obstacles that have limited MoE‑based federated fine‑tuning, delivering faster convergence, higher accuracy, and practical resource efficiency across heterogeneous edge devices.
Comments & Academic Discussion
Loading comments...
Leave a Comment