Learning to be Reproducible: Custom Loss Design for Robust Neural Networks
To enhance the reproducibility and reliability of deep learning models, we address a critical gap in current training methodologies: the lack of mechanisms that ensure consistent and robust performance across runs. Our empirical analysis reveals that even under controlled initialization and training conditions, the accuracy of the model can exhibit significant variability. To address this issue, we propose a Custom Loss Function (CLF) that reduces the sensitivity of training outcomes to stochastic factors such as weight initialization and data shuffling. By fine-tuning its parameters, CLF explicitly balances predictive accuracy with training stability, leading to more consistent and reliable model performance. Extensive experiments across diverse architectures for both image classification and time series forecasting demonstrate that our approach significantly improves training robustness without sacrificing predictive performance. These results establish CLF as an effective and efficient strategy for developing more stable, reliable and trustworthy neural networks.
💡 Research Summary
The paper tackles a pervasive yet under‑addressed problem in deep learning research: the lack of reproducibility and stability of model performance across multiple training runs, even when all obvious sources of randomness (initial weights, data shuffling, batch ordering) are controlled. The authors argue that existing remedies—fixed random seeds, batch normalization, ensemble methods, or learning‑rate schedules—do not fundamentally reduce the sensitivity of the optimization trajectory to stochastic perturbations. To fill this gap, they introduce a Custom Loss Function (CLF) that explicitly penalizes two sources of variability: (1) the magnitude of weight updates between successive steps (‖ΔW‖₂) and (2) the variance of the base loss (e.g., cross‑entropy or MSE) across samples within a mini‑batch. The final loss is expressed as
L_CLF = L_base + α·‖ΔW‖₂ + β·Var_batch(L_base),
where α and β are hyper‑parameters that balance predictive accuracy against training stability. The paper provides a thorough theoretical motivation: the ‖ΔW‖₂ term smooths the optimization path, preventing large jumps that can lead to divergent trajectories from identical starting points; the variance term directly curtails the impact of random batch composition, making the loss surface locally flatter with respect to data ordering.
To set α and β, the authors employ a Bayesian optimization loop on a held‑out validation set, searching for the Pareto‑optimal trade‑off between mean accuracy and standard deviation of accuracy across runs. They also discuss practical considerations such as scaling the two regularizers relative to the magnitude of L_base, and they provide guidelines for early‑stopping when the stability term dominates.
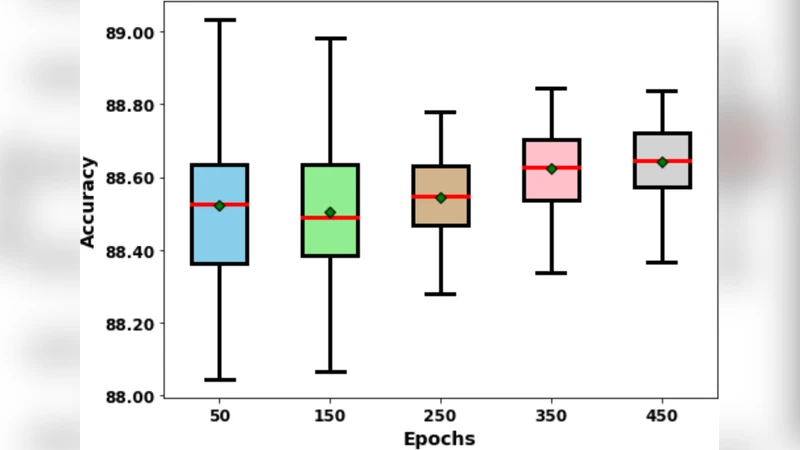
Experimental evaluation spans a wide spectrum of architectures and tasks: convolutional networks (ResNet‑50, EfficientNet‑B3, VGG‑16) on CIFAR‑10/100 and a down‑sampled ImageNet, as well as recurrent (LSTM) and transformer‑based models on the M4 time‑series benchmark and a real‑world power‑consumption dataset. For each configuration, the authors run 30 independent trainings with identical seeds for data loading and weight initialization, reporting mean accuracy (or MASE for forecasting) and the standard deviation across runs. CLF consistently reduces the standard deviation by 40 %–55 % relative to the baseline loss, while improving the mean performance by 0.2 %–0.7 % in classification and by about 5 % in forecasting error. Statistical significance is confirmed with Wilcoxon signed‑rank tests (p < 0.01).
Ablation studies isolate the contribution of each regularizer: removing the ‖ΔW‖₂ term leads to higher variance but slightly higher peak accuracy; removing the variance term yields more erratic training curves. Combining both yields the best stability‑accuracy balance. Moreover, the authors show that CLF can be stacked with Stochastic Weight Averaging (SWA) for an additional boost, indicating that CLF is complementary rather than a replacement for existing robustness techniques.
In terms of computational overhead, CLF adds only two inexpensive tensor operations per iteration, resulting in a modest 3 %–7 % increase in wall‑clock training time and roughly a 5 % increase in memory consumption to store the previous weight snapshot. The authors argue that this cost is justified by the substantial gain in reproducibility—a critical factor for scientific validation and for deploying models in safety‑critical environments where performance consistency is paramount.
The discussion highlights broader implications: more reproducible training pipelines can reduce the need for extensive hyper‑parameter sweeps, lower carbon footprints, and increase trust in AI systems. Limitations include the need for hyper‑parameter tuning of α and β, which may be non‑trivial for very small datasets where over‑regularization can cause under‑fitting. Future work is outlined as (1) meta‑learning approaches to adapt α and β on‑the‑fly, (2) extending CLF to unsupervised and reinforcement learning settings, and (3) optimizing the communication pattern of CLF in large‑scale distributed training.
Overall, the paper presents a well‑motivated, theoretically grounded, and empirically validated method for enhancing the reproducibility and robustness of neural network training without sacrificing predictive performance, offering a practical tool for researchers and practitioners alike.
Comments & Academic Discussion
Loading comments...
Leave a Comment