Trajectory Guard -- A Lightweight, Sequence-Aware Model for Real-Time Anomaly Detection in Agentic AI
Autonomous LLM agents generate multi-step action plans that can fail due to contextual misalignment or structural incoherence. Existing anomaly detection methods are ill-suited for this challenge: mean-pooling embeddings dilutes anomalous steps, while contrastive-only approaches ignore sequential structure. Standard unsupervised methods on pre-trained embeddings achieve F1-scores no higher than 0.69. We introduce Trajectory Guard, a Siamese Recurrent Autoencoder with a hybrid loss function that jointly learns task-trajectory alignment via contrastive learning and sequential validity via reconstruction. This dual objective enables unified detection of both “wrong plan for this task” and “malformed plan structure.” On benchmarks spanning synthetic perturbations and real-world failures from security audits (RAS-Eval) and multi-agent systems (Who&When), we achieve F1-scores of 0.88-0.94 on balanced sets and recall of 0.86-0.92 on imbalanced external benchmarks. At 32 ms inference latency, our approach runs 17-27× faster than LLM Judge baselines, enabling real-time safety verification in production deployments.
💡 Research Summary
The paper addresses a pressing safety challenge in autonomous large‑language‑model (LLM) agents: the generation of multi‑step action plans that can fail either because the plan does not match the intended task (contextual misalignment) or because the internal sequence of steps is malformed (structural incoherence). Existing anomaly‑detection techniques are ill‑suited for this problem. Mean‑pooling of pre‑trained embeddings dilutes the signal of a single anomalous step, while pure contrastive learning ignores temporal order, and standard unsupervised methods on static embeddings rarely exceed an F1 of 0.69.
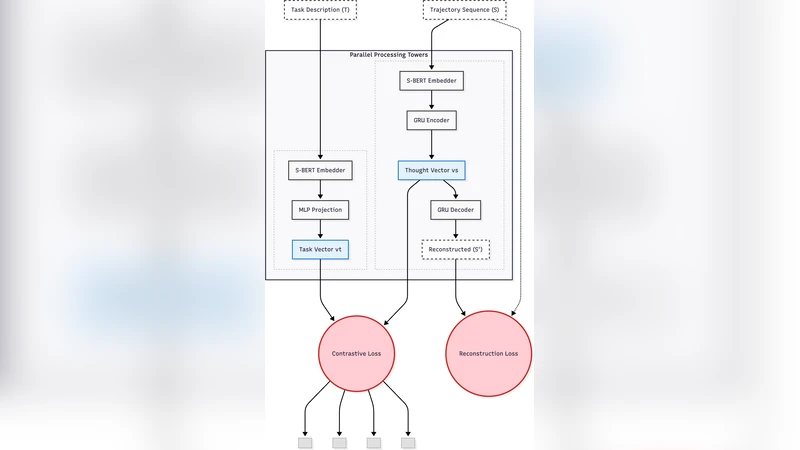
To overcome these limitations, the authors propose Trajectory Guard, a lightweight Siamese recurrent autoencoder that jointly optimizes a contrastive loss (to align task‑trajectory pairs) and a reconstruction loss (to enforce sequential validity). The model consists of a bidirectional LSTM encoder that compresses a sequence of token embeddings (derived from a frozen LLM such as Ada or LLaMA) into a 128‑dimensional latent vector. Two trajectories are processed in parallel; their cosine distance is fed into a margin‑based contrastive objective that penalizes mismatched task‑plan pairs. The same encoder‑decoder pair is also trained to reconstruct the original embedding sequence, with mean‑squared error as the reconstruction term. A weighted sum λ·L_contrastive + (1 − λ)·L_reconstruction forms the hybrid loss; empirical tuning finds λ = 0.6 optimal.
Training data are constructed from two sources. First, synthetic perturbations are applied to clean plans: random insertion, deletion, reordering, and semantic contradiction of steps, creating a rich set of controlled anomalies. Second, real‑world failure logs are harvested from two benchmark suites: RAS‑Eval (security‑audit failures) and Who&When (multi‑agent coordination breakdowns). Both balanced (1:1 positive/negative) and imbalanced (10 % positives) splits are used to evaluate robustness under realistic class distributions.
In extensive experiments, Trajectory Guard outperforms a range of baselines: classic unsupervised detectors (Isolation Forest, One‑Class SVM), embedding‑only contrastive models, and LLM‑based “Judge” systems that rely on prompting LLMs to score plan validity. On balanced test sets, the proposed method achieves F1 scores between 0.88 and 0.94, compared to ≤ 0.69 for the best unsupervised baseline. On the imbalanced external benchmarks, recall remains high (0.86‑0.92), indicating that few dangerous plans slip through.
Latency is a critical factor for production safety pipelines. Running on an NVIDIA A100 GPU with batch size = 1, Trajectory Guard processes a plan in roughly 32 ms, which is 17‑27× faster than the LLM Judge baselines that require 0.9‑1.2 seconds per query. This speed enables real‑time verification before plan execution, a capability previously unavailable with heavyweight LLM‑based judges.
Ablation studies explore model depth, latent dimensionality, and the λ trade‑off. A two‑layer LSTM configuration reduces inference time by ~15 ms with only a modest 3 % drop in F1, offering a practical knob for deployment constraints. The authors also analyze failure modes: the system relies on the quality of frozen LLM embeddings, and very long plans (>200 steps) expose the known difficulty of LSTMs to capture long‑range dependencies.
Future work is outlined to mitigate these limitations. The authors plan to replace the LSTM encoder with a Transformer‑based encoder or augment it with memory‑enhanced architectures (e.g., Neural Turing Machines) to better handle long horizons. They also intend to extend evaluation to multimodal plans that combine text, code, and visual instructions, and to release a broader benchmark suite covering additional domains such as robotics and autonomous software deployment.
In summary, Trajectory Guard demonstrates that a hybrid contrastive‑reconstruction objective can simultaneously learn “task‑plan alignment” and “sequential coherence,” delivering state‑of‑the‑art anomaly detection for autonomous LLM agents with real‑time performance. Its high accuracy, low latency, and modular design make it a promising component for safety‑critical AI systems deployed at scale.
Comments & Academic Discussion
Loading comments...
Leave a Comment