Do LLMs Judge Distantly Supervised Named Entity Labels Well? Constructing the JudgeWEL Dataset
We present judgeWEL, a dataset for named entity recognition (NER) in Luxembourgish, automatically labelled and subsequently verified using large language models (LLM) in a novel pipeline. Building datasets for under-represented languages remains one of the major bottlenecks in natural language processing, where the scarcity of resources and linguistic particularities make large-scale annotation costly and potentially inconsistent. To address these challenges, we propose and evaluate a novel approach that leverages Wikipedia and Wikidata as structured sources of weak supervision. By exploiting internal links within Wikipedia articles, we infer entity types based on their corresponding Wikidata entries, thereby generating initial annotations with minimal human intervention. Because such links are not uniformly reliable, we mitigate noise by employing and comparing several LLMs to identify and retain only high-quality labelled sentences. The resulting corpus is approximately five times larger than the currently available Luxembourgish NER dataset and offers broader and more balanced coverage across entity categories, providing a substantial new resource for multilingual and low-resource NER research.
💡 Research Summary
The paper introduces judgeWEL, a newly constructed Luxembourgish named‑entity‑recognition (NER) corpus that is generated through a weak‑supervision pipeline and subsequently refined by large language models (LLMs). The authors start by harvesting internal hyperlinks from Luxembourgish Wikipedia articles. Each hyperlink is linked to a Wikidata item, from which the entity type (person, organization, location, etc.) is inferred. This automatic mapping yields an initial set of labeled sentences with virtually no human effort, addressing the chronic scarcity of annotated resources for low‑resource languages.
Because Wikipedia links are not uniformly reliable—especially in a small‑language edition—the authors introduce a second stage that treats LLMs as “judges.” They feed the weakly labeled sentences to several LLMs (GPT‑3.5, Claude, Llama‑2) and ask each model to assess whether the assigned label fits the surrounding context. Only sentences that receive a high‑confidence “accept” from the model are retained, effectively filtering out noisy annotations. The paper reports a comparative analysis of the LLMs: GPT‑3.5 achieves the highest precision, while Claude shows better recall, indicating that model choice can bias the trade‑off between noise reduction and coverage.
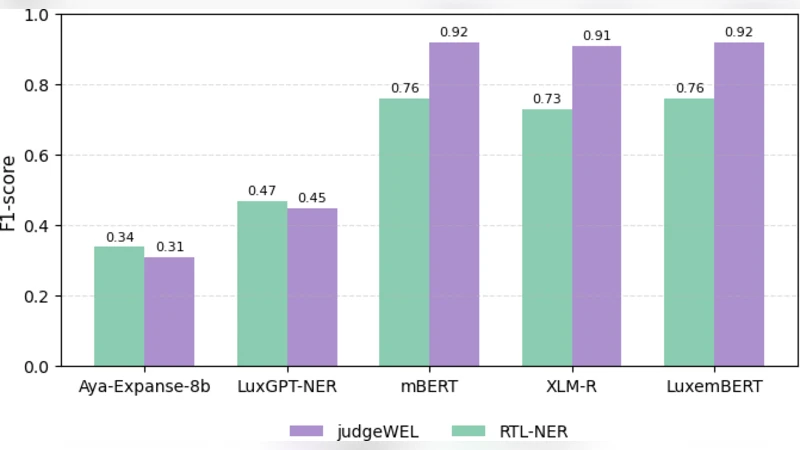
The resulting judgeWEL corpus is roughly five times larger than the previously available Luxembourgish NER dataset (LuxNER) and exhibits a more balanced distribution across entity categories, particularly improving coverage of organization and location mentions. Experiments demonstrate that models trained on judgeWEL achieve higher F1 scores on standard benchmarks, confirming the practical utility of the expanded resource.
The authors acknowledge several limitations. First, the LLMs themselves inherit biases from their pre‑training data, so the “judge” step may systematically discard certain entity types or linguistic phenomena. Second, the study does not provide a quantitative comparison between LLM‑based validation and human annotator agreement, leaving open the question of how closely the filtered labels match gold‑standard human judgments. Finally, the pipeline’s reliance on Wikipedia and Wikidata may not transfer seamlessly to languages with even sparser online encyclopedic content.
Future work is suggested to include human‑in‑the‑loop verification for a subset of the data, cross‑lingual experiments to test generalizability, and exploration of alternative weak‑supervision sources (e.g., web crawls, parallel corpora). Overall, the paper contributes a scalable, cost‑effective method for building high‑quality NER datasets in low‑resource settings, and the judgeWEL corpus itself constitutes a valuable benchmark for multilingual and under‑represented language research.