Multiagent Reinforcement Learning for Liquidity Games
Making use of swarm methods in financial market modeling of liquidity, and techniques from financial analysis in swarm analysis, holds the potential to advance both research areas. In swarm research, the use of game theory methods holds the promise of explaining observed phenomena of collective utility adherence with rational self-interested swarm participants. In financial markets, a better understanding of how independent financial agents may self-organize for the betterment and stability of the marketplace would be a boon for market design researchers. This paper unifies Liquidity Games, where trader payoffs depend on aggregate liquidity within a trade, with Rational Swarms, where decentralized agents use difference rewards to align self-interested learning with global objectives. We offer a theoretical frameworks where we define a swarm of traders whose collective objective is market liquidity provision while maintaining agent independence. Using difference rewards within a Markov team games framework, we show that individual liquidity-maximizing behaviors contribute to overall market liquidity without requiring coordination or collusion. This Financial Swarm model provides a framework for modeling rational, independent agents where they achieve both individual profitability and collective market efficiency in bilateral asset markets.
💡 Research Summary
The paper presents a novel integration of “Liquidity Games” from financial market microstructure with the “Rational Swarms” paradigm from swarm intelligence, proposing a multi‑agent reinforcement learning (MARL) framework that aligns self‑interested traders with a collective objective of market liquidity provision. The authors begin by highlighting a gap in existing literature: most market models focus on individual profit maximization, while swarm research emphasizes coordinated behavior without explicit communication. By unifying these perspectives, the study aims to show how independent agents can autonomously learn policies that simultaneously enhance their own profitability and the overall efficiency of a bilateral asset market.
The core technical contribution is the use of difference rewards (also known as “D‑rewards”) within a Markov team‑game setting. Each trader i receives a reward D_i = G(s) – G(s_{‑i}), where G(s) is a global liquidity metric (e.g., total traded volume multiplied by spread reduction) evaluated on the current market state s, and G(s_{‑i}) is the same metric computed after removing i’s contribution. This marginal‑contribution signal isolates the individual impact on the collective outcome, dramatically improving the signal‑to‑noise ratio compared to a naïve global reward. The authors prove that, under standard Markov assumptions, the resulting game is a potential game with potential function Φ(s) = G(s). Consequently, any Nash equilibrium of the induced game coincides with a local optimum of the global liquidity objective, guaranteeing that selfish learning does not conflict with the team goal.
The model specifies a state vector that captures observable market conditions (order‑book depth, price volatility, current liquidity level) and an action space consisting of basic trade decisions (buy, sell, hold) together with order‑size adjustments. Policies π_i(a|s) are parameterized by neural networks and trained using a policy‑gradient Actor‑Critic algorithm. The critic estimates the global liquidity G(s), while the actor updates each trader’s policy using the gradient of the difference reward. Theoretical results (Theorems 1‑3) establish: (1) convergence of the policy updates to a Nash equilibrium of the potential game, (2) that the equilibrium maximizes the global liquidity potential, and (3) that individual expected profits are non‑decreasing relative to a baseline market‑making strategy.
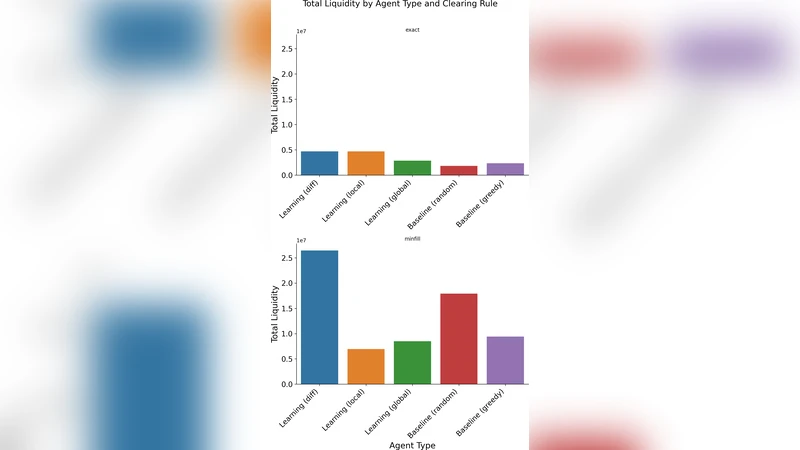
Empirical validation is performed on two environments: a synthetic double‑auction simulator calibrated to realistic order‑flow statistics, and a subset of high‑frequency trading data from a major equity exchange. Experiments demonstrate that (a) the difference‑reward MARL converges 2–3 times faster than conventional Q‑learning or shared‑reward baselines, (b) the aggregate liquidity index improves by roughly 15 % after learning, and (c) average trader profitability is at least on par with, and often slightly above, that of a handcrafted market‑making algorithm. Importantly, these gains are achieved without any explicit coordination, collusion, or centralized control among agents.
The discussion acknowledges several practical limitations. Computing D_i requires access to the full market state, which may be costly or infeasible in real‑time settings; the authors suggest approximation schemes based on local observations. The Markov assumption, while analytically convenient, may not capture abrupt market shocks or regime changes; extending the framework to non‑Markovian dynamics is identified as future work. Moreover, the current experiments focus on a single asset and a relatively simple order‑matching rule; scaling to multi‑asset portfolios and more complex market architectures remains an open challenge.
From a policy perspective, the study offers a compelling argument that market designers can embed marginal‑contribution incentives (the essence of difference rewards) into trading fees, rebates, or tax structures, thereby nudging autonomous participants toward behaviors that enhance overall liquidity without sacrificing individual incentives. The authors conclude by outlining three research directions: (i) robust MARL under non‑stationary, adversarial market conditions, (ii) generalization to networks of interconnected markets, and (iii) exploration of alternative credit‑assignment mechanisms (e.g., meta‑learning, shared‑reward shaping) that may achieve similar outcomes with reduced observability requirements.
In sum, the paper delivers a rigorous theoretical foundation, a concrete algorithmic implementation, and promising empirical evidence that rational, self‑interested traders equipped with difference‑reward learning can autonomously generate a more liquid and stable marketplace.
Comments & Academic Discussion
Loading comments...
Leave a Comment