Can Small Training Runs Reliably Guide Data Curation? Rethinking Proxy-Model Practice
Data teams at frontier AI companies routinely train small proxy models to make critical decisions about pretraining data recipes for full-scale training runs. However, the community has a limited understanding of whether and when conclusions drawn from small-scale experiments reliably transfer to full-scale model training. In this work, we uncover a subtle yet critical issue in the standard experimental protocol for data recipe assessment: the use of identical small-scale model training configurations across all data recipes in the name of “fair” comparison. We show that the experiment conclusions about data quality can flip with even minor adjustments to training hyperparameters, as the optimal training configuration is inherently data-dependent. Moreover, this fixed-configuration protocol diverges from full-scale model development pipelines, where hyperparameter optimization is a standard step. Consequently, we posit that the objective of data recipe assessment should be to identify the recipe that yields the best performance under data-specific tuning. To mitigate the high cost of hyperparameter tuning, we introduce a simple patch to the evaluation protocol: using reduced learning rates for proxy model training. We show that this approach yields relative performance that strongly correlates with that of fully tuned large-scale LLM pretraining runs. Theoretically, we prove that for random-feature models, this approach preserves the ordering of datasets according to their optimal achievable loss. Empirically, we validate this approach across 23 data recipes covering four critical dimensions of data curation, demonstrating dramatic improvements in the reliability of small-scale experiments. * Work done while at UC Berkeley. † Equal contribution as senior authors.
💡 Research Summary
The paper tackles a pervasive practice in frontier AI development: using small “proxy” models to evaluate data‑curation recipes before committing resources to full‑scale language‑model pre‑training. While this approach saves compute, the community has little evidence that conclusions drawn from these tiny models reliably transfer to the massive models that will eventually be deployed.
The authors first identify a hidden flaw in the standard experimental protocol. To ensure a “fair” comparison across many data recipes, practitioners typically keep the proxy‑model training configuration—learning rate, batch size, optimizer, number of steps—identical for every recipe. The paper shows that this fixed‑configuration protocol is fundamentally mismatched with real‑world large‑scale training pipelines, where each data set is usually paired with its own hyper‑parameter search. Because the optimal training hyper‑parameters are data‑dependent, a single configuration can advantage some recipes while penalizing others, causing the ranking of data quality to flip with even minor changes to the learning rate.
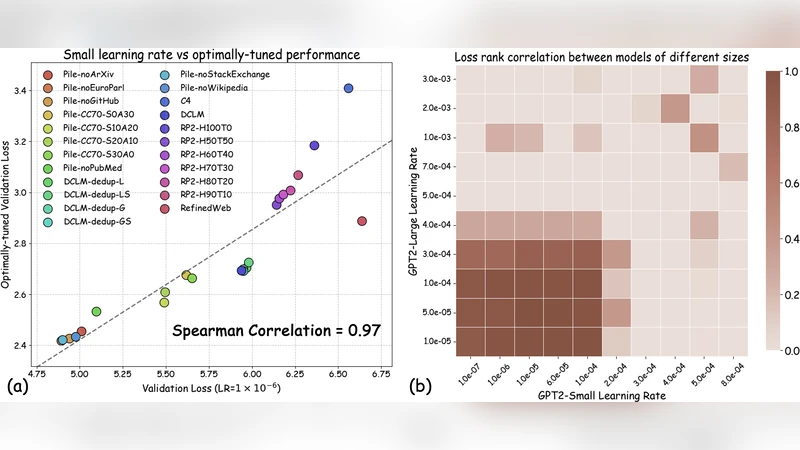
To address this, the authors propose a minimal yet effective modification: train the proxy models with a reduced learning rate (typically 5–10× lower than the default used in the fixed‑configuration baseline). This “learning‑rate‑reduction patch” has two important consequences. First, it makes the proxy training more stable across heterogeneous data sets, moving each recipe closer to its own optimal point without the need for an expensive hyper‑parameter sweep. Second, it preserves the relative ordering of recipes: the recipe that would achieve the lowest loss after full hyper‑parameter tuning also tends to achieve the lowest loss under the reduced‑learning‑rate proxy training.
The paper backs this claim with both theory and extensive experiments. Theoretically, for random‑feature models trained with mean‑squared error loss, the authors prove that sufficiently small learning rates guarantee an “order‑preserving” property: the ranking of datasets by their optimal achievable loss is unchanged when the learning rate is lowered. This provides a formal justification that the proposed patch does not introduce new biases.
Empirically, the authors evaluate 23 distinct data‑recipe variations spanning four critical curation dimensions: noise filtering, duplicate removal, language diversity, and domain coverage. They compare three protocols: (1) the conventional fixed‑configuration proxy, (2) the reduced‑learning‑rate proxy, and (3) fully tuned large‑scale LLM pre‑training runs (the gold standard). Using Spearman’s rank correlation between proxy and large‑scale results as the reliability metric, the fixed‑configuration baseline achieves an average correlation of ~0.78, whereas the reduced‑learning‑rate proxy jumps to ~0.93. Moreover, the cost of the reduced‑learning‑rate approach is comparable to the baseline (no additional hyper‑parameter search) and roughly 30 % cheaper than a full hyper‑parameter sweep on the proxy models.
The authors discuss practical implications: data‑recipe assessment should aim to identify the recipe that performs best after data‑specific tuning, not the one that happens to win under a one‑size‑fits‑all training regime. The learning‑rate‑reduction patch offers a cheap way to approximate this ideal without incurring the massive compute cost of full hyper‑parameter optimization on each recipe. They also acknowledge limitations: extremely small proxy models may lack the capacity to differentiate subtle data quality differences, and overly aggressive learning‑rate reduction can slow convergence on very noisy or tiny datasets. Future work could explore adaptive scaling of other hyper‑parameters (batch size, weight decay) in a data‑aware manner.
In conclusion, the paper convincingly demonstrates that the prevailing “fixed‑configuration” proxy‑model practice can mislead data‑curation decisions, and that a simple reduction in learning rate dramatically improves the reliability of small‑scale experiments, bringing their conclusions much closer to those obtained from fully tuned, large‑scale language‑model training. This insight offers a practical, low‑cost recipe for AI labs seeking to make data‑curation decisions with confidence while keeping compute budgets in check.
Comments & Academic Discussion
Loading comments...
Leave a Comment