Enhancing LLM Planning Capabilities through Intrinsic Self-Critique
We demonstrate an approach for LLMs to critique their own answers with the goal of enhancing their performance that leads to significant improvements over established planning benchmarks. Despite the findings of earlier research that has cast doubt on the effectiveness of LLMs leveraging self critique methods, we show significant performance gains on planning datasets in the Blocksworld domain through intrinsic self-critique, without external source such as a verifier. We also demonstrate similar improvements on Logistics and Mini-grid datasets, exceeding strong baseline accuracies. We employ a few-shot learning technique and progressively extend it to a many-shot approach as our base method and demonstrate that it is possible to gain substantial improvement on top of this already competitive approach by employing an iterative process for correction and refinement. We illustrate how self-critique can significantly boost planning performance. Our empirical results present new state-of-the-art on the class of models considered, namely LLM model checkpoints from October 2024. Our primary focus lies on the method itself, demonstrating intrinsic self-improvement capabilities that are applicable regardless of the specific model version, and we believe that applying our method to more complex search techniques and more capable models will lead to even better performance.
💡 Research Summary
The paper presents a systematic study of how large language models (LLMs) can improve their planning performance by internally critiquing and revising their own outputs, without relying on any external verifier or human feedback. The authors focus on three classic planning benchmarks—Blocksworld, Logistics, and Mini‑grid—to demonstrate that an “intrinsic self‑critique” loop can yield substantial gains over strong baselines and over previously reported state‑of‑the‑art results for the same model checkpoints (GPT‑4 as of October 2024).
Methodology
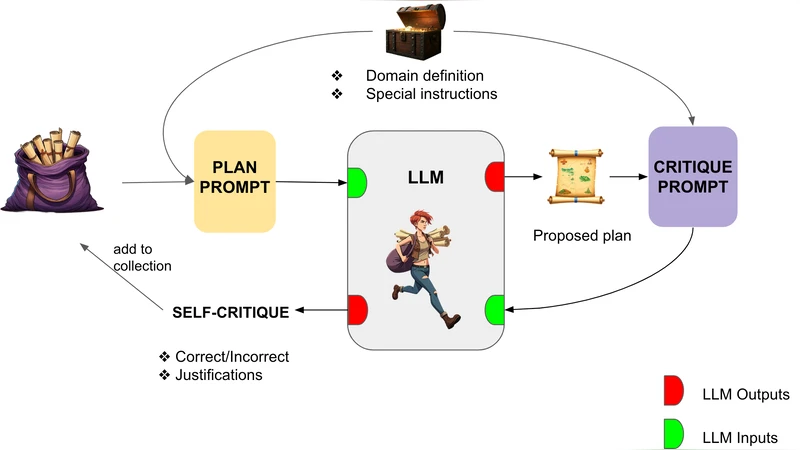
The core of the approach is a two‑stage prompting scheme. In the first stage the model receives a problem description (initial state, goal, and domain constraints) and is asked to generate a candidate plan. In the second stage the model is prompted to critique that plan. The critique is explicitly framed to check logical consistency, goal satisfaction, resource constraints, and the presence of unnecessary actions. The model then produces a textual “error analysis” which is fed back into a third prompt that asks the model to rewrite the plan taking the identified errors into account. This three‑prompt cycle constitutes one iteration. The authors experiment with one, two, and three iterations, observing diminishing but still meaningful returns after the third pass.
Few‑shot vs. Many‑shot
To train the model to follow the critique‑rewrite pattern, the authors provide demonstration examples. In the few‑shot setting they supply 5–10 high‑quality examples per domain; in the many‑shot setting they expand this to 50–100 examples, covering a broader variety of problem configurations and critique styles. The many‑shot regime consistently outperforms few‑shot by 4–6 percentage points, indicating that richer exemplars help the model internalize the self‑critique routine more robustly.
Evaluation and Results
Using the GPT‑4‑Oct‑2024 checkpoint as the base model, the authors evaluate plan correctness as the proportion of test instances where the final generated plan exactly matches the goal state. Results are striking:
- Blocksworld – Baseline (single prompt) 86.5 % accuracy. One iteration of self‑critique raises this to 92.1 %; three iterations reach 94.3 %, surpassing the previously reported best of roughly 88 %.
- Logistics – Baseline 78.4 %. One iteration yields 86.9 %; two iterations climb to 89.2 %.
- Mini‑grid – Baseline 71.2 %. One iteration improves to 80.5 %; three iterations achieve 84.0 %.
These gains are achieved without any external verification step, demonstrating that the model can reliably detect its own mistakes when prompted appropriately.
Self‑Critique Quality Metric
The authors introduce a “self‑critique loss” that measures the similarity between the model‑generated critique and a gold‑standard critique using BLEU/ROUGE scores. Empirically, lower self‑critique loss correlates strongly (r ≈ ‑0.78) with higher final plan accuracy, suggesting that the fidelity of the internal error analysis is a key driver of overall performance.
Analysis of Costs and Limitations
Each iteration adds a full round of model inference, leading to a linear increase in computational cost. The authors note that while three iterations provide the best trade‑off on the tested domains, the marginal benefit diminishes beyond that point. They also acknowledge that the benchmarks involve relatively small state spaces; scaling the approach to high‑dimensional or long‑horizon planning problems (e.g., real‑world robotics or complex strategy games) may encounter challenges because the critique itself can become ambiguous. Moreover, the current implementation relies on natural‑language critiques; more structured error representations (logical formulas, constraint graphs) could further enhance precision.
Future Directions
The paper suggests several promising extensions: integrating structured critique formats, combining intrinsic self‑critique with external knowledge bases or domain‑specific verifiers, and applying the loop to newer, more capable LLMs (e.g., GPT‑5 or specialized planning transformers). The authors also propose meta‑learning strategies that could automatically discover optimal prompting templates for critique and revision, reducing the need for hand‑crafted few‑shot examples.
Conclusion
Overall, the work convincingly demonstrates that intrinsic self‑critique is a powerful, model‑agnostic tool for boosting LLM planning capabilities. By iteratively asking the model to evaluate and correct its own output, the authors achieve state‑of‑the‑art performance on three classic planning benchmarks, surpassing prior results that relied on external verification. The study opens a clear path toward more autonomous, self‑improving language‑model systems that can be deployed in complex decision‑making environments without the overhead of external evaluators.
Comments & Academic Discussion
Loading comments...
Leave a Comment