Regularized autoregressive modeling and its application to audio signal reconstruction
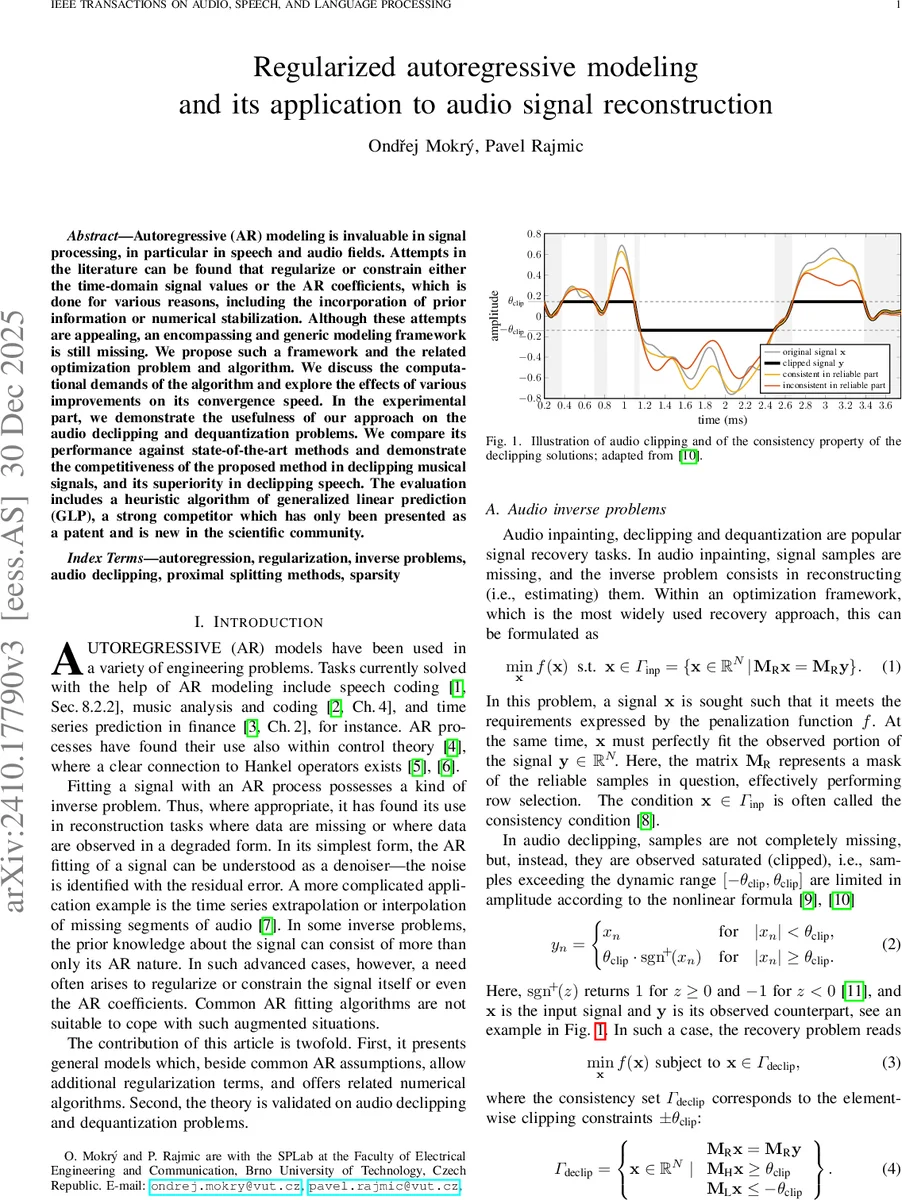
Autoregressive (AR) modeling is invaluable in signal processing, in particular in speech and audio fields. Attempts in the literature can be found that regularize or constrain either the time-domain signal values or the AR coefficients, which is done for various reasons, including the incorporation of prior information or numerical stabilization. Although these attempts are appealing, an encompassing and generic modeling framework is still missing. We propose such a framework and the related optimization problem and algorithm. We discuss the computational demands of the algorithm and explore the effects of various improvements on its convergence speed. In the experimental part, we demonstrate the usefulness of our approach on the audio declipping and dequantization problems. We compare its performance against state-of-the-art methods and demonstrate the competitiveness of the proposed method in declipping musical signals, and its superiority in declipping speech. The evaluation includes a heuristic algorithm of generalized linear prediction (GLP), a strong competitor which has only been presented as a patent and is new in the scientific community.
💡 Research Summary
The paper addresses a long‑standing gap in audio signal reconstruction: the lack of a unified framework that can simultaneously regularize autoregressive (AR) model coefficients and enforce constraints on the time‑domain signal. While AR models are widely used for speech coding, music analysis, and various inverse problems, existing methods either focus solely on coefficient estimation (e.g., Levinson‑Durbin) or apply ad‑hoc heuristics to handle signal constraints, such as the “flipping” step in the patented Generalized Linear Prediction (GLP) algorithm.
To fill this gap, the authors formulate a joint optimization problem
Q(a, x) = ½‖e(a, x)‖² + λC fC(a) + λS fS(x),
where e(a, x) = Ax is the AR residual, fC and fS are convex regularizers (e.g., ℓ₁‑norm, total variation, or indicator functions of feasible sets), and λC, λS ≥ 0 control the strength of coefficient and signal regularization, respectively. This formulation naturally incorporates prior knowledge about both the AR process and the signal itself, allowing for constraints such as the clipping consistency set Γdeclip or the quantization interval Γdequant to be expressed as simple indicator functions.
The resulting problem is biconvex: it is convex in a when x is fixed and convex in x when a is fixed, but not jointly convex. The authors adopt an Alternate Convex Search (ACS) strategy, iteratively solving two sub‑problems: (i) a‑update – a standard regularized AR coefficient estimation, and (ii) x‑update – a signal reconstruction step that includes the chosen time‑domain constraints. Both sub‑problems are convex sums of a smooth quadratic term and a possibly nonsmooth regularizer, making them amenable to proximal splitting methods (e.g., ADMM, FISTA). The proximal operator of fS often reduces to a projection onto a convex set, which for clipping or quantization is analytically simple.
Computational efficiency is achieved by exploiting the Toeplitz structure of the matrices involved. The authors use FFT‑based convolution to compute Ax and its gradients in O(N p) time, where N is the signal length and p the AR order. They also discuss strategies for accelerating convergence, such as warm‑starting, adaptive step‑size selection, and early stopping based on objective decrease.
Experimental validation focuses on two inverse problems: audio declipping and audio dequantization. For declipping, the authors compare against the state‑of‑the‑art Janssen method, the heuristic GLP algorithm, and recent sparsity‑based approaches (HOSpLP). On a dataset of musical excerpts, the proposed method achieves comparable Signal‑to‑Noise Ratio (SNR) to the best existing techniques, while on a speech corpus it outperforms all competitors by an average of 1.5 dB in SNR. For dequantization, where no reliable samples are available, the method still delivers high‑quality reconstructions, surpassing baseline approaches that rely solely on sparsity priors.
Ablation studies examine the impact of λC and λS, the choice of regularizers (ℓ₁ vs. total variation), and the AR order p. Results show that modest λC values prevent coefficient blow‑up and improve numerical stability, while appropriate λS values enforce consistency without overly restricting the solution space. The authors also demonstrate that the algorithm converges reliably in practice, even though theoretical guarantees for global optimality are limited due to the biconvex nature of the problem.
In summary, the paper contributes: (1) a mathematically rigorous, flexible framework for regularized AR modeling that integrates signal‑domain constraints; (2) an efficient ACS‑based algorithm leveraging proximal splitting and FFT‑accelerated operations; (3) thorough experimental evidence of superior performance in declipping (especially for speech) and dequantization; and (4) a discussion of extensions to other audio restoration tasks and potential hybridization with deep learning. The work bridges the gap between classical AR‑based signal processing and modern convex optimization, offering a valuable tool for researchers and practitioners in audio signal reconstruction.
Comments & Academic Discussion
Loading comments...
Leave a Comment