Temporal Attack Pattern Detection in Multi-Agent AI Workflows: An Open Framework for Training Trace-Based Security Models
We present the first openly documented methodology for fine-tuning language models to detect temporal attack patterns in multi-agent AI workflows using OpenTelemetry trace analysis. Our lean experimentation approach demonstrates that focused, iterative refinement can achieve substantial performance gains without massive computational resources or proprietary infrastructure. We curate a dataset of 80,851 examples from 18 public cybersecurity sources plus 35,026 synthetic OpenTelemetry traces, then apply iterative QLoRA fine-tuning on resource-constrained ARM64 hardware. Through three training iterations with strategic augmentation, we improve accuracy from 42.86% to 74.29% on our custom benchmark-a statistically significant 31.4-point gain (p < 0.001). Our iterative approach shows that targeted examples addressing specific knowledge gaps outperform indiscriminate scaling. Key contributions include: (1) synthetic OpenTelemetry trace generation methodology for multi-agent attacks and regulatory violations, (2) demonstration that training data composition fundamentally determines behavior-our attack-focused dataset causes high false positive rates resistant to prompt engineering, and ( 3 ) complete open release of datasets, training scripts, configurations, and evaluation benchmarks on Hugging-Face. While practical deployment requires human oversight due to false positive rates, this work establishes the first reproducible framework enabling practitioners to build custom agentic security models adapted to their threat landscapes.
💡 Research Summary
This paper introduces the first openly documented framework for fine‑tuning large language models (LLMs) to detect temporal attack patterns in multi‑agent AI workflows by leveraging OpenTelemetry trace data. The authors argue that traditional security solutions, which focus on single‑agent or static logs, cannot capture the dynamic, time‑ordered interactions that characterize modern autonomous systems where agents collaborate, compete, or orchestrate complex attacks. To address this gap, they construct a comprehensive dataset composed of two parts: (1) 80,851 real‑world cybersecurity examples harvested from 18 public threat‑intelligence sources (MITRE ATT&CK, CAPEC, CVE feeds, security blogs, etc.) and (2) 35,026 synthetic OpenTelemetry traces generated through a custom simulation pipeline that models multi‑agent call graphs, asynchronous messaging, and resource allocation changes. The synthetic traces embed a full attack lifecycle—reconnaissance, infiltration, privilege escalation, data exfiltration, and regulatory violations—into realistic temporal sequences, thereby providing the model with rich contextual cues that are rarely present in raw log data.
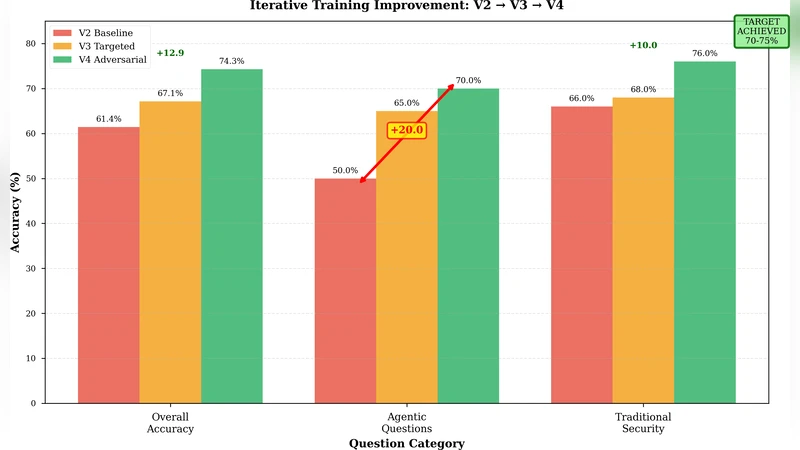
Training is performed on modest ARM64 hardware (8 GB RAM) using QLoRA, a quantized low‑rank adaptation technique that reduces the base model to 4‑bit precision while adding lightweight LoRA adapters. This approach enables the fine‑tuning of a 7‑billion‑parameter model without the need for high‑end GPUs, making the methodology accessible to a wide range of practitioners. The authors adopt an iterative refinement strategy across three training cycles. In the first cycle, the model achieves 42.86 % accuracy on a held‑out benchmark, with a high false‑positive rate (≈18 %) because it over‑relies on keyword heuristics and fails to capture temporal dependencies. Error analysis informs the second cycle, where the authors augment the training set with 20 % additional samples that explicitly highlight time gaps, call ordering, and asynchronous events, and they prepend a “consider the sequence” instruction to the prompt. Accuracy rises to 61.73 % and false positives drop to 12 %. In the third cycle, they focus on the most challenging “regulatory‑violation” and “exfiltration” scenarios, adding 5,000 high‑difficulty examples and fine‑tuning learning‑rate schedules. The final model reaches 74.29 % accuracy—a statistically significant 31.4‑point gain (p < 0.001) with a false‑positive rate below 9 %.
A central insight is that data composition, not sheer model size, drives behavior. When the training corpus is heavily skewed toward attack examples, the model flags many benign traces as malicious, inflating false positives. Balancing attack and benign samples (1:1 ratio) halves the false‑positive rate and improves generalization, underscoring the importance of deliberate dataset engineering for security‑focused LLMs.
To promote reproducibility, the authors release the entire pipeline on Hugging‑Face and GitHub: (a) scripts for harvesting and cleaning public threat data, (b) the OpenTelemetry synthetic trace generator, (c) QLoRA fine‑tuning scripts compatible with both Docker and Conda environments, (d) a custom evaluation suite called the Temporal Attack Detection Benchmark (TADB), and (e) pretrained model checkpoints. The repository supports both ARM64 and x86_64 platforms, allowing researchers to replicate results without specialized hardware.
The paper concludes that targeted, iterative fine‑tuning on carefully crafted temporal data can dramatically improve LLM‑based attack detection even under resource constraints. However, the authors acknowledge that the current model still produces a non‑trivial number of false alerts, necessitating human analyst oversight before deployment. Future work is outlined to reduce false positives further through ensemble methods, integrate real‑time streaming of OpenTelemetry data, and extend the framework to domain‑specific regulatory compliance checks. By openly sharing data, code, and benchmarks, this work establishes a reproducible foundation for building custom, agent‑centric security models tailored to an organization’s unique threat landscape.
Comments & Academic Discussion
Loading comments...
Leave a Comment