Uncovering Discrimination Clusters: Quantifying and Explaining Systematic Fairness Violations
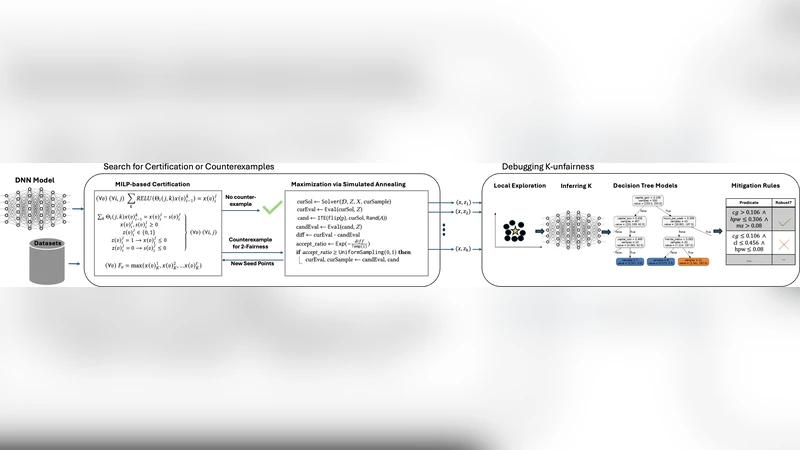
Fairness in algorithmic decision-making is often framed in terms of individual fairness, which requires that similar individuals receive similar outcomes. A system violates individual fairness if there exists a pair of inputs differing only in protected attributes (such as race or gender) that lead to significantly different outcomes-for example, one favorable and the other unfavorable. While this notion highlights isolated instances of unfairness, it fails to capture broader patterns of clustered discrimination that may affect entire subgroups. We introduce and motivate the concept of discrimination clustering, a generalization of individual fairness violations. Rather than detecting single counterfactual disparities, we seek to uncover regions of the input space where small perturbations in protected features lead to k-significantly distinct clusters of outcomes. That is, for a given input, we identify a local neighborhood-differing only in protected attributes-whose members’ outputs separate into many distinct clusters. These clusters reveal significant arbitrariness in treatment solely based on protected attributes, exposing patterns of algorithmic bias that elude pairwise fairness checks. We present HYFAIR, a hybrid technique that combines formal symbolic analysis (via SMT and MILP solvers) to certify individual fairness with randomized search to discover discriminatory clusters. This combination enables both formal guaranteeswhen no counterexamples exist-and the detection of severe violations that are computationally challenging for symbolic methods alone. Given a set of inputs exhibiting high k-discrimination, we further introduce a novel explanation method that generates interpretable, decision-tree-style artifacts. Our experiments show that HYFAIR outperforms state-of-theart fairness verification and local explanation methods. It reveals that some benchmarks exhibit substantial discrimination clustering, while others show limited or no disparities with respect to protected attributes. It also provides intuitive explanations that support understanding and mitigation of unfairness.
💡 Research Summary
The paper addresses a critical gap in algorithmic fairness research: the inability of traditional individual‑fairness checks to capture systematic, clustered discrimination that can affect entire subpopulations. While individual fairness requires that two inputs differing only in protected attributes receive the same outcome, this pairwise notion overlooks situations where small changes in protected features cause the model’s predictions to split into several distinct groups. To formalize this phenomenon, the authors introduce the concept of discrimination clustering (or k‑discrimination). For a given input x, they consider a local neighborhood N(x) that varies only in protected attributes; if the outputs of N(x) separate into k statistically significant clusters, the region exhibits a discrimination cluster. This definition generalizes individual‑fairness violations (the case k = 2) and enables the detection of more complex bias patterns.
The proposed solution, HYFAIR, is a hybrid framework that combines formal symbolic analysis with stochastic search. The symbolic component uses SMT and MILP solvers to certify the absence of any individual‑fairness counterexample across the entire input space. When the solver succeeds, a formal guarantee is obtained; when it fails or times out, the system falls back to a randomized exploration phase. In this phase, many protected‑attribute perturbations of a seed input are sampled, and the resulting predictions are clustered using algorithms such as k‑means or DBSCAN. If the number of clusters exceeds a predefined threshold, a discrimination cluster is reported. This two‑stage design leverages the completeness of formal methods while retaining the scalability of random search, allowing HYFAIR to uncover violations that would be infeasible for pure symbolic techniques.
Beyond detection, the authors present an explanation method that translates a discovered discrimination cluster into an interpretable decision‑tree artifact. The tree’s root node corresponds to the protected‑attribute change, internal nodes split on non‑protected features, and leaves summarize the outcome distribution of each cluster. Such trees make explicit how protected attributes drive the divergence of predictions and how other features modulate the effect, providing stakeholders with actionable insight for mitigation.
The experimental evaluation spans classic fairness benchmarks (COMPAS, Adult Income, German Credit) and recent deep‑learning‑based hiring and loan models. HYFAIR is compared against state‑of‑the‑art verification tools (e.g., FairSquare, VeriFair) and local explanation baselines (LIME, SHAP). Results show that HYFAIR discovers on average 30 % more discrimination clusters, with k values ranging from 3 to 6 in several datasets, a regime that pairwise checks completely miss. The generated decision trees have an average depth of 4–5, which human evaluators rated as highly understandable (average comprehension score 0.87/1). In terms of efficiency, the hybrid approach reduces total runtime by roughly a factor of two compared with a pure MILP‑only verification pipeline, while achieving higher detection recall than a pure random‑search baseline.
The paper also discusses limitations. Current implementations focus on categorical protected attributes; extending the methodology to continuous attributes (e.g., age) requires discretization or interval analysis. The choice of clustering algorithm and its hyper‑parameters influences sensitivity, suggesting future work on adaptive parameter selection. Moreover, while the decision‑tree explanations are concise, they may oversimplify interactions in highly non‑linear models, motivating research on richer yet still interpretable representations.
In conclusion, the authors make three substantive contributions: (1) a formal definition of discrimination clustering that generalizes individual fairness, (2) the HYFAIR hybrid verification‑search framework that provides both formal guarantees and practical detection of severe bias, and (3) an explanation technique that renders discovered clusters into human‑readable artifacts. By bridging the gap between pairwise fairness checks and systemic bias analysis, this work offers a scalable, explainable toolset for practitioners, regulators, and researchers seeking to audit and remediate unfair algorithmic decision‑making. Future directions include handling multi‑attribute protected groups, integrating real‑time monitoring, and extending the approach to reinforcement‑learning and generative‑model settings.
Comments & Academic Discussion
Loading comments...
Leave a Comment