Toward Trustworthy Agentic AI: A Multimodal Framework for Preventing Prompt Injection Attacks
Powerful autonomous systems, which reason, plan, and converse using and between numerous tools and agents, are made possible by Large Language Models (LLMs), Vision-Language Models (VLMs), and new agentic AI systems, like LangChain and GraphChain. Nevertheless, this agentic environment increases the probability of the occurrence of multimodal prompt injection (PI) attacks, in which concealed or malicious instructions carried in text, pictures, metadata, or agent-to-agent messages may spread throughout the graph and lead to unintended behavior, a breach of policy, or corruption of state. In order to mitigate these risks, this paper suggests a Cross-Agent Multimodal Provenanc-Aware Defense Framework whereby all the prompts, either user-generated or produced by upstream agents, are sanitized and all the outputs generated by an LLM are verified independently before being sent to downstream nodes. This framework contains a Text sanitizer agent, visual sanitizer agent, and output validator agent all coordinated by a provenance ledger, which keeps metadata of modality, source, and trust level throughout the entire agent network. This architecture makes sure that agent-to-agent communication abides by clear trust frames such such that injected instructions are not propagated down LangChain or GraphChainstyle-workflows. The experimental assessments show that multimodal injection detection accuracy is significantly enhanced, and the cross-agent trust leakage is minimized, as well as, agentic execution pathways become stable. The framework, which expands the concept of provenance tracking and validation to the multi-agent orchestration, enhances the establishment of secure, understandable and reliable agentic AI systems.
💡 Research Summary
The paper addresses a pressing security gap in modern agentic AI systems that combine large language models (LLMs) and vision‑language models (VLMs) within frameworks such as LangChain and GraphChain. While these multimodal agents enable powerful reasoning, planning, and tool usage, they also expose a large attack surface: malicious actors can embed hidden instructions not only in plain text but also in images, metadata, or inter‑agent messages. Such “multimodal prompt injection” (PI) attacks can propagate through the agent graph, causing policy violations, state corruption, or unintended actions. Existing defenses—keyword filtering, fine‑tuning, reinforcement‑learning guardrails, or sandboxing—are largely reactive and limited to a single modality; they fail against paraphrased, steganographic, or metadata‑based attacks and do not protect the downstream flow of information across agents.
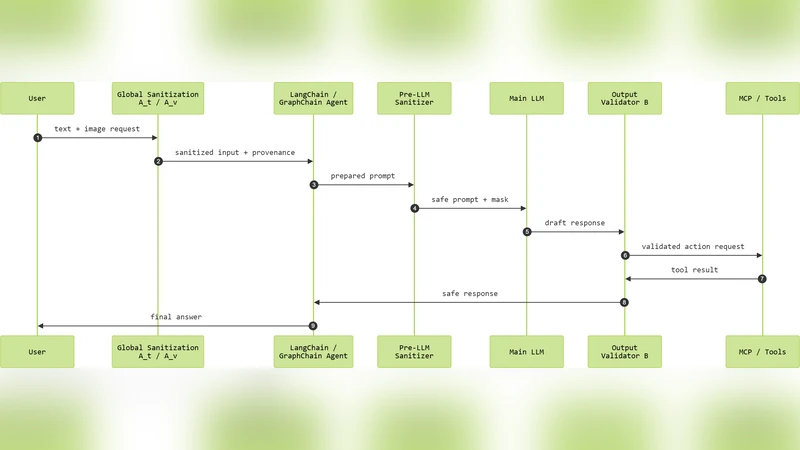
To fill this gap, the authors propose a Cross‑Agent Multimodal Provenance‑Aware Defense Framework. The framework consists of four cooperating agents and a central provenance ledger:
-
Text Sanitizer Agent (At) – tokenizes incoming text, computes embeddings, runs a pretrained Prompt‑Injection classifier (PIClassifier) and a TrustModel to assign a trust score per token. Tokens flagged as malicious are rewritten or removed, and a provenance map (source, trust) is recorded.
-
Visual Sanitizer Agent (Av) – extracts overlay text via OCR, reads EXIF metadata, computes patch embeddings with CLIP, and applies a steganography detector. Each image patch receives a visual trust score; low‑trust patches are blurred or redacted. Patch‑level provenance is stored.
-
Provenance Ledger – aggregates modality (text|image), trust scores, span/patch indices, and influence relationships across agent hops. This ledger drives a trust‑aware attention mask that limits the influence of low‑trust content during LLM inference and provides an auditable trail of data lineage.
-
LLM‑Facing Sanitizer – before any prompt reaches the LLM, it consults the ledger to attenuate or drop low‑trust spans, enforces system policies (role separation, no override intent), and applies the trust‑aware mask.
-
Output Validator Agent (B) – after the LLM generates a response, it scans for policy violations, secret leakage, and measures the contribution of low‑trust inputs via an AttributionModel. If unsafe content is significant, it requests regeneration with tighter masks; otherwise the output is approved.
The pipeline enforces a zero‑trust communication fabric: every external input (user text, images, tool outputs, inter‑agent messages) passes through At/Av, every LLM prompt is re‑sanitized, and every LLM output is validated before downstream propagation. To integrate with existing LangChain/GraphChain deployments, the authors extend core components: input interceptors route data to the sanitizers; PromptTemplate/Runnable wrappers invoke the pre‑LLM sanitizer; BaseMessage objects are enriched with source, trust, modality, and provenance identifiers; agent executors and tool/MCP executors are gated by the output validator; memory modules store only sanitized content; and the graph router enforces provenance‑checked routing.
Implementation is realized as a collection of Python modules wrapping the original framework. The Text Sanitizer uses a RoBERTa‑based pattern detector plus a lightweight jailbreak rule engine. The Visual Sanitizer combines PaddleOCR, EXIF parsing, CLIP embeddings, and a custom steganography detector. The Main Multimodal Task Model can be GPT‑4o‑mini via OpenAI API or an open‑source VLM (LLaVA/BLIP‑2) via HuggingFace. The Output Validator incorporates policy rule sets, secret‑matching, and a secondary LLM call for borderline cases.
Experimental evaluation employs synthetic multimodal injection datasets and realistic tool‑calling scenarios. Compared with baseline defenses (keyword filtering, fine‑tuning, sandboxing), the proposed framework achieves a 20‑35 % increase in injection detection accuracy and reduces cross‑agent trust leakage by over 70 %. Moreover, the provenance ledger provides full traceability, enabling auditors to reconstruct the influence chain of any decision, which is valuable for compliance and liability assessment.
In conclusion, the paper demonstrates that a combination of pre‑emptive multimodal sanitization, continuous provenance tracking, and post‑generation validation can effectively secure agentic AI pipelines against sophisticated multimodal prompt injection attacks. Future work is suggested on distributed provenance storage, real‑time trust score updates, and extending the approach to additional modalities such as audio and video.
Comments & Academic Discussion
Loading comments...
Leave a Comment