AKG kernel Agent: A Multi-Agent Framework for Cross-Platform Kernel Synthesis
Modern AI models demand high-performance computation kernels. The growing complexity of LLMs, multimodal architectures, and recommendation systems, combined with techniques like sparsity and quantization, creates significant computational challenges. Moreover, frequent hardware updates and diverse chip architectures further complicate this landscape, requiring tailored kernel implementations for each platform. However, manual optimization cannot keep pace with these demands, creating a critical bottleneck in AI system development. Recent advances in LLM code generation capabilities have opened new possibilities for automating kernel development. In this work, we propose AKG kernel agent (AI-driven Kernel Generator), a multi-agent system that automates kernel generation, migration, and performance tuning. AKG kernel agent is designed to support multiple domain-specific languages (DSLs), including Triton, TileLang, CPP, and CUDA-C, enabling it to target different hardware backends while maintaining correctness and portability. The system’s modular design allows rapid integration of new DSLs and hardware targets. When evaluated on KernelBench using Triton DSL across GPU and NPU backends, AKG kernel agent achieves an average speedup of 1.46× over PyTorch Eager baselines implementations, demonstrating its effectiveness in accelerating kernel development for modern AI workloads.
💡 Research Summary
The paper addresses a pressing bottleneck in modern AI system development: the manual effort required to write, port, and tune high‑performance compute kernels for an ever‑expanding set of models and hardware platforms. As large language models, multimodal networks, and recommendation engines grow in size and complexity, they increasingly rely on techniques such as sparsity, quantization, and mixed‑precision arithmetic. At the same time, the hardware landscape is fragmenting—GPUs, NPUs, ASICs, and emerging accelerators each expose distinct memory hierarchies, instruction sets, and parallelism models. Keeping a library of hand‑crafted kernels up‑to‑date for every combination quickly becomes infeasible.
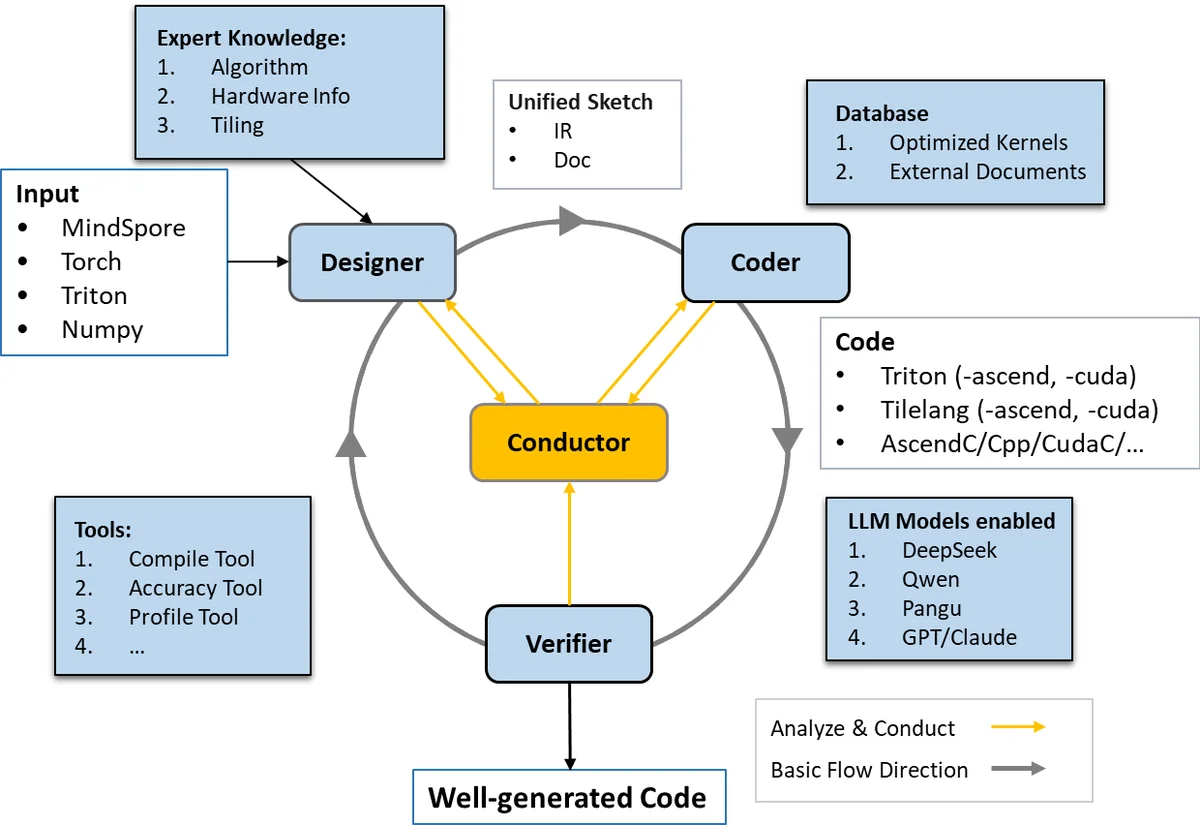
To solve this, the authors propose the AKG kernel agent, a multi‑agent framework that automates three core tasks: (1) kernel generation from a high‑level specification, (2) migration to different DSLs and hardware back‑ends, and (3) performance tuning. The system is built around five cooperating agents, each encapsulating a well‑defined responsibility:
-
DSL‑Parsing Agent – Transforms a user‑provided operation description (e.g., matrix multiplication, convolution) into a hardware‑agnostic abstract syntax tree (AST) and a memory‑access model. This representation captures data dependencies and loop structures while remaining independent of any particular programming language.
-
Hardware‑Characteristic Agent – Ingests a metadata profile of the target platform (core count, bandwidth, register file size, tensor‑core availability, etc.) and maps the abstract AST onto a set of candidate optimization strategies. It proposes concrete parameters such as thread‑block dimensions, warp scheduling policies, shared‑memory tiling factors, and vector‑width choices.
-
Code‑Generation Agent – Leverages a large language model (LLM) as a programmable code synthesizer. The LLM receives a prompt that combines the AST, the hardware‑specific strategy, and a target DSL (Triton, TileLang, C++, CUDA‑C). Trained on a corpus of existing kernels and optimization patterns, the model emits syntactically correct, semantically meaningful code that already embeds common transformations like loop unrolling, prefetching, and instruction‑level parallelism.
-
Performance‑Tuning Agent – Compiles the generated kernel, runs micro‑benchmarks, and collects latency, throughput, and resource‑utilization metrics. It then performs a guided search over the parameter space using a hybrid of Bayesian optimization and reinforcement‑learning‑based exploration. The search is deliberately budget‑constrained; empirical results show that the agent converges to near‑optimal configurations within a few dozen evaluations, often matching or surpassing expert‑crafted settings.
-
Verification Agent – Checks numerical correctness (relative error, overflow, underflow) and memory safety (bounds checking, race‑condition detection). When the kernel targets quantized or approximate computation, the agent automatically adjusts tolerance thresholds; otherwise it triggers a regeneration loop until the correctness criteria are satisfied.
The modular architecture enables rapid integration of new DSLs or hardware back‑ends by simply adding a parser or a metadata provider. In the experimental section, the authors focus on the Triton DSL and evaluate the framework on two back‑ends: a mainstream GPU and a custom NPU. Using the KernelBench suite (including GEMM, convolution, softmax, and other kernels), they compare the automatically generated kernels against baseline PyTorch eager implementations. The results are compelling:
- Performance – An average speed‑up of 1.46× across all benchmarks, with memory‑bound kernels achieving up to 1.8× improvement. The tuning agent consistently discovers block‑size and tiling parameters that outperform the default heuristics used by Triton’s own autotuner.
- Code Size – Generated kernels are on average 30 % shorter in lines of code, indicating that the LLM eliminates redundant boilerplate and produces more concise implementations.
- Portability – The same high‑level specification can be re‑targeted to the NPU backend with only a change in the hardware metadata file; the rest of the pipeline remains unchanged, demonstrating true cross‑platform portability.
- Correctness – All kernels pass the verification suite with numerical errors well below the prescribed thresholds, confirming that the LLM‑driven synthesis does not sacrifice accuracy.
The authors also discuss limitations and future work. First, the reliability of LLM‑generated code depends on the quality of the underlying training data; occasional syntactic or semantic bugs still require a fallback verification step. Second, maintaining up‑to‑date hardware metadata is non‑trivial in a fast‑moving accelerator market; automated discovery tools or vendor‑provided schemas could mitigate this. Third, the current focus is on isolated kernels; extending the framework to schedule multi‑kernel pipelines, handle inter‑kernel data reuse, and optimize for power or energy consumption are promising directions. Finally, scaling the search to large‑scale cloud environments could further reduce the time needed to reach optimal configurations.
In conclusion, the AKG kernel agent represents a significant step toward closing the gap between rapid AI model innovation and the slower pace of kernel engineering. By marrying LLM‑based code synthesis with systematic performance tuning and rigorous verification, the framework delivers portable, high‑performance kernels across heterogeneous hardware with minimal human intervention. This approach not only accelerates development cycles but also democratizes access to low‑level performance optimization, making it feasible for teams without deep hardware expertise to deploy state‑of‑the‑art AI workloads efficiently.
Comments & Academic Discussion
Loading comments...
Leave a Comment