📝 Original Info
- Title: Adversarial Lens: Exploiting Attention Layers to Generate Adversarial Examples for Evaluation
- ArXiv ID: 2512.23837
- Date: 2025-12-29
- Authors: Researchers from original ArXiv paper
📝 Abstract
Recent advances in mechanistic interpretability suggest that intermediate attention layers encode token-level hypotheses that are iteratively refined toward the final output. In this work, we exploit this property to generate adversarial examples directly from attention-layer token distributions. Unlike prompt-based or gradientbased attacks, our approach leverages modelinternal token predictions, producing perturbations that are both plausible and internally consistent with the model's own generation process. We evaluate whether tokens extracted from intermediate layers can serve as effective adversarial perturbations for downstream evaluation tasks. We conduct experiments on argument quality assessment using the ArgQuality dataset, with LLaMA-3.1-Instruct-8B serving as both the generator and evaluator. Our results show that attention-based adversarial examples lead to measurable drops in evaluation performance while remaining semantically similar to the original inputs. However, we also observe that substitutions drawn from certain layers and token positions can introduce grammatical degradation, limiting their practical effectiveness. Overall, our findings highlight both the promise and current limitations of using intermediate-layer representations as a principled source of adversarial examples for stress-testing LLM-based evaluation pipelines.
💡 Deep Analysis
Deep Dive into Adversarial Lens: Exploiting Attention Layers to Generate Adversarial Examples for Evaluation.
Recent advances in mechanistic interpretability suggest that intermediate attention layers encode token-level hypotheses that are iteratively refined toward the final output. In this work, we exploit this property to generate adversarial examples directly from attention-layer token distributions. Unlike prompt-based or gradientbased attacks, our approach leverages modelinternal token predictions, producing perturbations that are both plausible and internally consistent with the model’s own generation process. We evaluate whether tokens extracted from intermediate layers can serve as effective adversarial perturbations for downstream evaluation tasks. We conduct experiments on argument quality assessment using the ArgQuality dataset, with LLaMA-3.1-Instruct-8B serving as both the generator and evaluator. Our results show that attention-based adversarial examples lead to measurable drops in evaluation performance while remaining semantically similar to the original inputs. However, we al
📄 Full Content
Adversarial Lens: Exploiting Attention Layers to Generate Adversarial
Examples for Evaluation
Kaustubh Dhole
Department of Computer Science
Emory University
kdhole@emory.edu
Abstract
Recent advances in mechanistic interpretability
suggest that intermediate attention layers en-
code token-level hypotheses that are iteratively
refined toward the final output. In this work,
we exploit this property to generate adversarial
examples directly from attention-layer token
distributions. Unlike prompt-based or gradient-
based attacks, our approach leverages model-
internal token predictions, producing pertur-
bations that are both plausible and internally
consistent with the model’s own generation pro-
cess. We evaluate whether tokens extracted
from intermediate layers can serve as effective
adversarial perturbations for downstream eval-
uation tasks. We conduct experiments on ar-
gument quality assessment using the ArgQual-
ity dataset, with LLaMA-3.1-Instruct-8B serv-
ing as both the generator and evaluator. Our
results show that attention-based adversarial
examples lead to measurable drops in evalua-
tion performance while remaining semantically
similar to the original inputs. However, we
also observe that substitutions drawn from cer-
tain layers and token positions can introduce
grammatical degradation, limiting their prac-
tical effectiveness. Overall, our findings high-
light both the promise and current limitations
of using intermediate-layer representations as
a principled source of adversarial examples for
stress-testing LLM-based evaluation pipelines.
1
Introduction
Recent efforts in mechanistic interpretability have
highlighted the wealth of information encoded
within the layers of large language models
(LLMs) (Meng et al., 2022; Sharkey et al., 2025).
These layers, which are often overlooked in favor
of the final outputs, have been shown to act as iter-
ative predictors of the eventual response (Jastrzeb-
ski et al., 2018; nostalgebraist, 2020), providing
insights into the model’s generation process. While
most of these techniques have heavily focused on
interpretability, we argue that they could potentially
be adapted to generate paraphrastic and adversarial
examples for evaluation tasks – which generally
operate over model generated data.
Probing the attention layers has multiple advan-
tages – First, since the layers act as both iterative
indicators of the final output (Belrose et al., 2023),
and store related entities (Meng et al., 2022; Her-
nandez et al., 2024), they can provide natural lan-
guage variations by potentially treating LLMs as
knowledge bases. Second, these generations, can
be obtained early on without necessitating running
over all the layers (Din et al., 2024; Pal et al., 2023).
Third, these generations might provide cues for
model hallucinations (Yuksekgonul et al., 2024) as
gradual deviations from the original token are ob-
tained from the model itself. From an adversarial
point of view, tokens from intermediate layers are
valuable as they can act as perturbations to the orig-
inal input. Specifically, the outputs are iteratively
refined, since as the activations move towards the
last layer they tend to move towards the direction
of the negative gradient (Jastrzebski et al., 2018)
or each successive layer achieving lower perplex-
ity (Belrose et al., 2023). This is also precisely how
adversarial examples are constructed – perturbing
towards the direction of the positive gradient of the
loss (Goodfellow et al., 2015).
Hence, in this study, we explore whether such
fine-grained information extracted from the atten-
tion layers of large language models (LLMs) can
be leveraged to generate adversarial examples on
downstream natural language tasks, particularly
critical tasks such as evaluation.
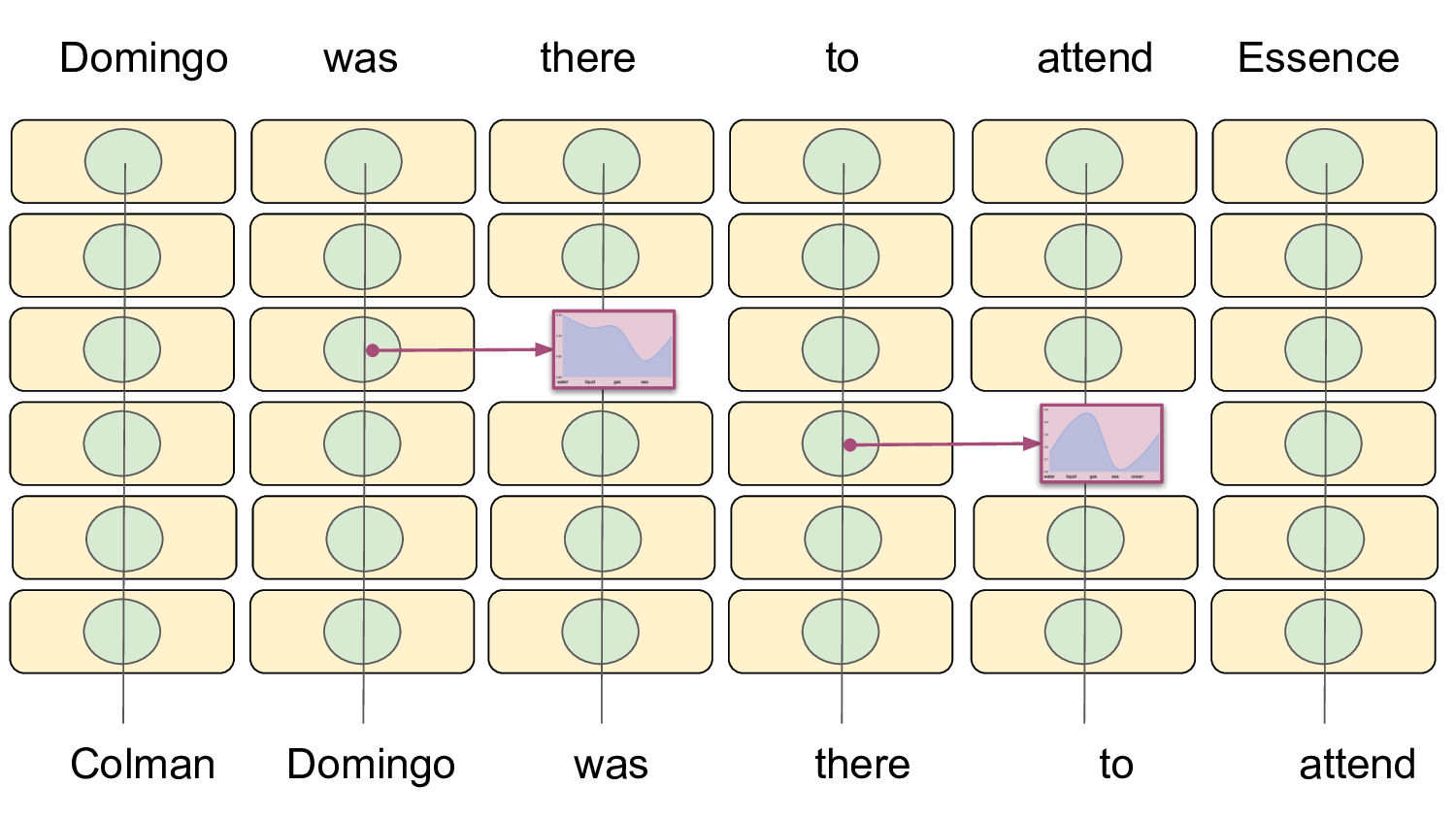
Specifically, in this work, we introduce two
attention-based adversarial generation methods:
attention-based token substitution and attention-
based conditional generation, both of which lever-
age intermediate-layer token predictions to con-
struct plausible yet adversarial inputs.
Our paper is organized as follows: §2 first dis-
cusses related work in interpretability and genera-
arXiv:2512.23837v1 [cs.CL] 29 Dec 2025
tion evaluation. §3 and §4 defines and implements
the two approaches for generating examples. §5
finally discusses the results and analysis.
2
Related Work
We now discuss some of the related work in mech-
anistic interpretability and LLM based evaluation
to place our work in context.
Recent interpretability studies have explored the
information encoded within the internal layers of
large language models (LLMs) to better understand
how models generate subsequent tokens. For in-
stance, LogitLens and TunedLens (nostalgebraist,
2020; Belrose et al., 2023) demonstrate that inter-
mediate layers can be made to predict tokens simi-
lar to those generated in the final layer, by attaching
a trained or untrained unembedding matrix to them.
Methods such as ROME (Meng et al., 2022) high-
li
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.