How Much Data Is Enough? Uniform Convergence Bounds for Generative & Vision-Language Models under Low-Dimensional Structure
Modern generative and vision-language models (VLMs) are increasingly used to support decisions in scientific and medical settings, where predictive probabilities must be not only accurate but also well calibrated. While such models often achieve strong empirical performance with moderate data, it remains unclear when their predictions can be expected to generalize uniformly across inputs, classes, or subpopulations, rather than only on average. This distinction is particularly important in biomedical applications, where rare conditions or specific subgroups may exhibit systematically larger errors despite low overall loss. We study this question from a finite-sample perspective and ask: under what structural assumptions can generative and vision-language models achieve uniformly accurate and calibrated behavior with practical sample sizes? Rather than analyzing general model parameterizations, we focus on induced families of classifiers obtained by varying prompts or semantic embeddings within a restricted representation space. We show that when model outputs depend smoothly on a low-dimensional semantic representation-an assumption empirically supported by the spectral structure of text and joint image-text embeddings-classical uniform convergence arguments yield meaningful, non-asymptotic guarantees. Our main results establish finite-sample uniform convergence bounds for accuracy and calibration functionals of VLM-induced classifiers under Lipschitz stability with respect to prompt embeddings. The resulting sample complexity depends on the intrinsic or effective dimension of the embedding space, rather than its ambient dimensionality. We further derive spectrum-dependent bounds that make explicit how eigenvalue decay in the embedding covariance governs data requirements. These results help explain why VLMs can generalize reliably with far fewer samples than would be predicted by parameter count alone. Finally, we discuss practical implications for training and evaluating generative and vision-language models in data-limited biomedical settings. In particular, our analysis clarifies when current dataset sizes are sufficient to support uniformly reliable predictions, and why commonly used average calibration metrics may fail to detect worst-case miscalibration. Together, these results provide a principled framework to reason about data sufficiency, calibration, and reliability in modern generative and multimodal models.
💡 Research Summary
The paper tackles a pressing issue in the deployment of large generative and vision‑language models (VLMs) for scientific and medical decision‑making: while average performance metrics often look impressive, they do not guarantee that the model will behave reliably on every possible input, class, or sub‑population. In high‑stakes domains such as healthcare, rare diseases or under‑represented demographic groups can suffer from systematic errors that are invisible to aggregate statistics. To address this, the authors adopt a finite‑sample, uniform‑convergence perspective, asking under what structural conditions a family of classifiers induced by a VLM can be guaranteed to generalize uniformly—both in terms of accuracy and probability calibration—using realistic dataset sizes.
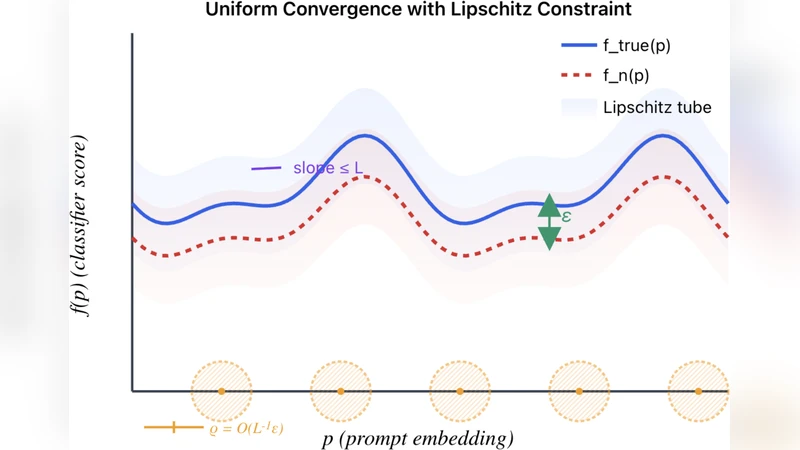
The key insight is to shift focus from the massive raw parameter space of the model to the low‑dimensional semantic representation space that the model actually manipulates when a user varies prompts or semantic embeddings. Empirically, embeddings produced by state‑of‑the‑art text encoders (e.g., CLIP, BLIP‑2) exhibit a rapidly decaying eigen‑spectrum, meaning that most of the variance is captured by a handful of principal components. The authors formalize this observation by assuming that the model’s output distribution is Lipschitz‑continuous with respect to the embedding vector: for any two embeddings (z_1, z_2) the change in the output distribution is bounded by a constant (L) times the Euclidean distance (|z_1 - z_2|_2). This smoothness assumption is well‑supported by empirical studies of VLMs and is central to the theoretical development.
Under the Lipschitz condition, the paper derives uniform‑convergence bounds for two functionals: (1) the standard 0‑1 loss (accuracy) and (2) calibration loss (e.g., Brier score or Expected Calibration Error). By covering the embedding space with an (\varepsilon)-net whose size depends on the effective dimension (d_{\text{eff}}) of the covariance matrix of the embeddings, the authors show that with probability at least (1-\delta),
\
Comments & Academic Discussion
Loading comments...
Leave a Comment