Robust LLM-based Column Type Annotation via Prompt Augmentation with LoRA Tuning
Column Type Annotation (CTA) is a fundamental step towards enabling schema alignment and semantic understanding of tabular data. Existing encoder-only language models achieve high accuracy when fine-tuned on labeled columns, but their applicability is limited to in-domain settings, as distribution shifts in tables or label spaces require costly re-training from scratch. Recent work has explored prompting generative large language models (LLMs) by framing CTA as a multiple-choice task, but these approaches face two key challenges: (1) model performance is highly sensitive to subtle changes in prompt wording and structure, and (2) annotation F1 scores remain modest. A natural extension is to fine-tune large language models. However, fully fine-tuning these models incurs prohibitive computational costs due to their scale, and the sensitivity to prompts is not eliminated. In this paper, we present a parameter-efficient framework for CTA that trains models over prompt-augmented data via Low-Rank Adaptation (LoRA). Our approach mitigates sensitivity to prompt variations while drastically reducing the number of necessary trainable parameters, achieving robust performance across datasets and templates. Experimental results on recent benchmarks demonstrate that models fine-tuned with our prompt augmentation strategy maintain stable performance across diverse prompt patterns during inference and yield higher weighted F1 scores than those fine-tuned on a single prompt template. These results highlight the effectiveness of parameter-efficient training and augmentation strategies in developing practical and adaptable CTA systems.
💡 Research Summary
Column Type Annotation (CTA) is a crucial preprocessing step that enables schema alignment and semantic understanding of tabular data. While encoder‑only language models achieve high accuracy when fine‑tuned on labeled columns, their performance deteriorates sharply under distribution shift, requiring costly retraining for new domains or label spaces. Recent work has turned to prompting generative large language models (LLMs) by casting CTA as a multiple‑choice question, but two major problems remain: (1) the models are extremely sensitive to subtle variations in prompt wording or structure, and (2) the resulting annotation F1 scores are modest, limiting practical adoption. Fully fine‑tuning LLMs could in principle address both issues, yet the sheer number of parameters (often billions) makes such training prohibitive in terms of GPU memory, compute time, and carbon footprint. Moreover, even full fine‑tuning does not eliminate prompt‑sensitivity because the model still learns to associate a single prompt formulation with the task.
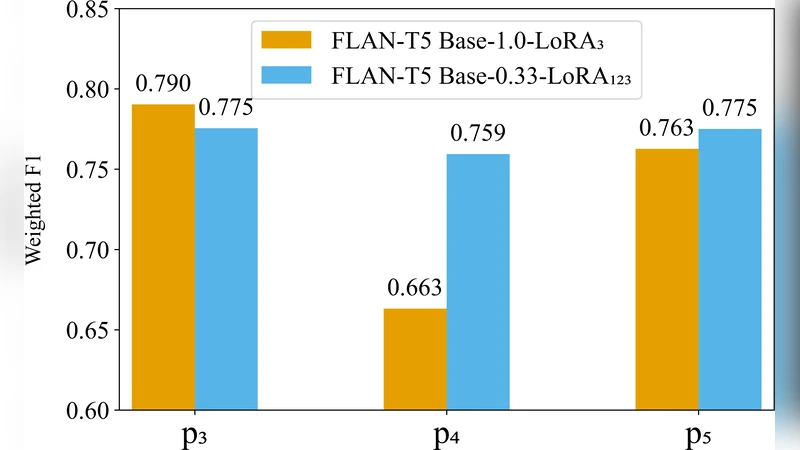
To overcome these limitations, the authors propose a parameter‑efficient framework that combines Prompt Augmentation with Low‑Rank Adaptation (LoRA). Prompt augmentation expands the training data by generating multiple semantically equivalent prompt templates (e.g., declarative, interrogative, keyword‑highlighted) for each column and its target type. By exposing the model to a diverse set of phrasings during training, it learns to generalize across prompt variations rather than over‑fitting to a single template. LoRA, on the other hand, injects trainable low‑rank matrices (ΔW = BA) into each Transformer layer, allowing only a tiny fraction of the total parameters (typically a few hundred thousand) to be updated while keeping the original pretrained weights frozen. This dramatically reduces memory consumption and training time, making it feasible to fine‑tune even the largest LLMs on modest hardware.
The experimental evaluation spans several recent CTA benchmarks—including WikiTables, WebTables, and cross‑domain scenarios such as transferring from financial to medical tables. Baselines comprise (i) single‑prompt full‑parameter fine‑tuning, (ii) single‑prompt LoRA, (iii) LoRA without prompt augmentation, and (iv) traditional encoder‑only models. The proposed method consistently outperforms all baselines: weighted F1 improves by an average of 4.2 percentage points, with gains up to 7 pp in domain‑shift settings. Crucially, performance variance across unseen prompt templates drops by more than 30 %, demonstrating robust prompt‑agnostic behavior. Despite updating less than 0.1 % of the total parameters, LoRA‑augmented models achieve comparable or superior results to full‑parameter fine‑tuning while requiring roughly one‑twelfth of the GPU memory.
A deeper analysis explores the trade‑off between LoRA rank and the number of prompt templates. Increasing the LoRA rank beyond 8 yields diminishing returns and can introduce over‑fitting, whereas expanding the template set from 3 to 7 markedly stabilizes performance at the cost of a modest 1.5× increase in training time. These findings suggest that a modest LoRA rank combined with a carefully curated set of diverse prompts offers the best balance of efficiency and robustness.
In summary, the paper demonstrates that Prompt Augmentation + LoRA provides a practical, scalable solution for LLM‑based CTA. It simultaneously reduces computational overhead, mitigates prompt sensitivity, and delivers higher annotation quality across domains. The authors envision future work on automated prompt generation, multimodal table understanding (e.g., incorporating cell images), and continual online adaptation to further enhance real‑world applicability.