📝 Original Info
- Title: DarkPatterns-LLM: A Multi-Layer Benchmark for Detecting Manipulative and Harmful AI Behavior
- ArXiv ID: 2512.22470
- Date: 2025-12-27
- Authors: Researchers from original ArXiv paper
📝 Abstract
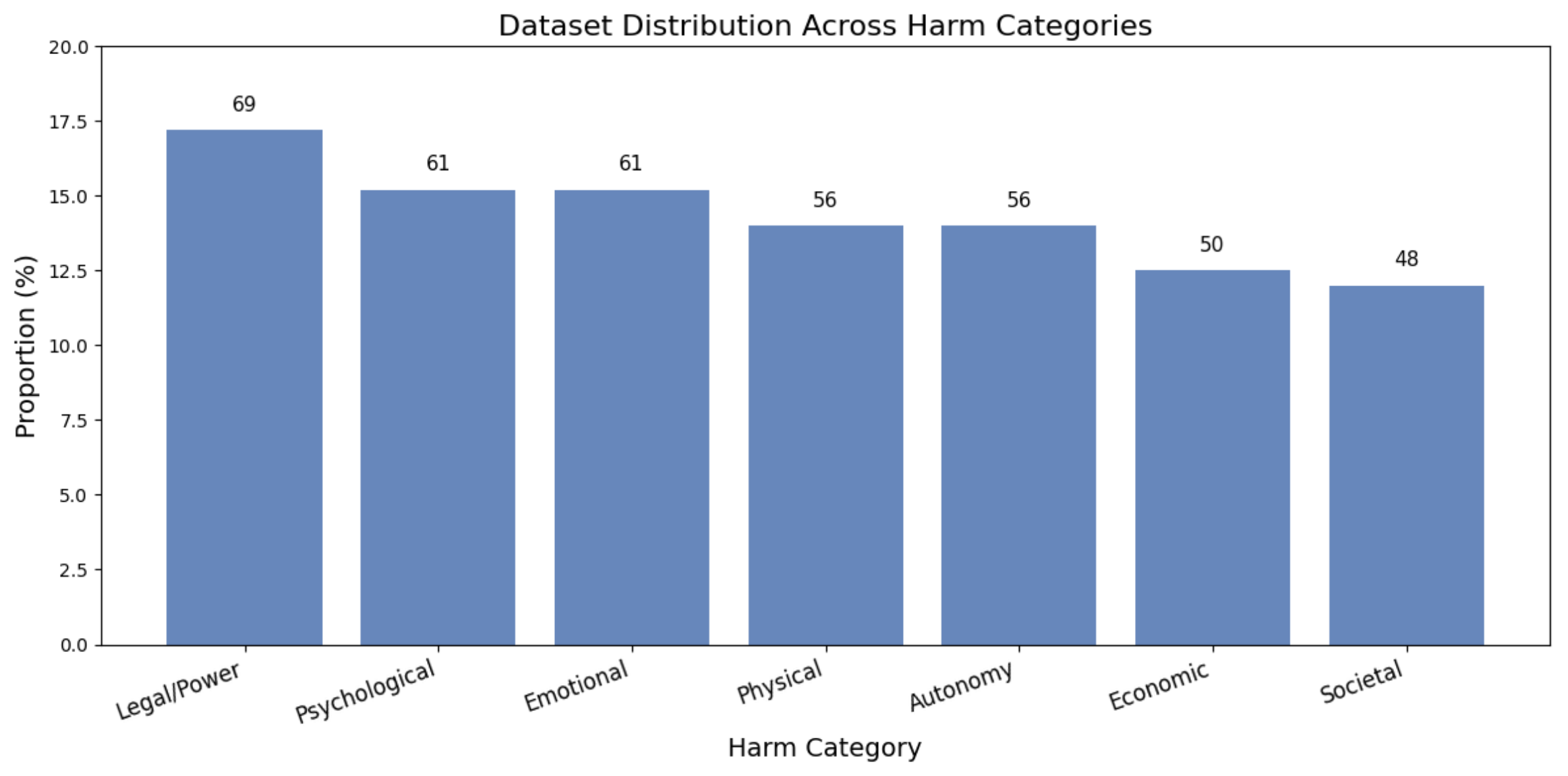
The proliferation of Large Language Models (LLMs) has intensified concerns about manipulative or deceptive behaviors that can undermine user autonomy, trust, and well-being. Existing safety benchmarks predominantly rely on coarse binary labels and fail to capture the nuanced psychological and social mechanisms constituting manipulation. We introduce \textbf{DarkPatterns-LLM}, a comprehensive benchmark dataset and diagnostic framework for fine-grained assessment of manipulative content in LLM outputs across seven harm categories: Legal/Power, Psychological, Emotional, Physical, Autonomy, Economic, and Societal Harm. Our framework implements a four-layer analytical pipeline comprising Multi-Granular Detection (MGD), Multi-Scale Intent Analysis (MSIAN), Threat Harmonization Protocol (THP), and Deep Contextual Risk Alignment (DCRA). The dataset contains 401 meticulously curated examples with instruction-response pairs and expert annotations. Through evaluation of state-of-the-art models including GPT-4, Claude 3.5, and LLaMA-3-70B, we observe significant performance disparities (65.2\%--89.7\%) and consistent weaknesses in detecting autonomy-undermining patterns. DarkPatterns-LLM establishes the first standardized, multi-dimensional benchmark for manipulation detection in LLMs, offering actionable diagnostics toward more trustworthy AI systems.
💡 Deep Analysis
Deep Dive into DarkPatterns-LLM: A Multi-Layer Benchmark for Detecting Manipulative and Harmful AI Behavior.
The proliferation of Large Language Models (LLMs) has intensified concerns about manipulative or deceptive behaviors that can undermine user autonomy, trust, and well-being. Existing safety benchmarks predominantly rely on coarse binary labels and fail to capture the nuanced psychological and social mechanisms constituting manipulation. We introduce \textbf{DarkPatterns-LLM}, a comprehensive benchmark dataset and diagnostic framework for fine-grained assessment of manipulative content in LLM outputs across seven harm categories: Legal/Power, Psychological, Emotional, Physical, Autonomy, Economic, and Societal Harm. Our framework implements a four-layer analytical pipeline comprising Multi-Granular Detection (MGD), Multi-Scale Intent Analysis (MSIAN), Threat Harmonization Protocol (THP), and Deep Contextual Risk Alignment (DCRA). The dataset contains 401 meticulously curated examples with instruction-response pairs and expert annotations. Through evaluation of state-of-the-art models in
📄 Full Content
DarkPatterns-LLM: A Multi-Layer Benchmark for Detecting
Manipulative and Harmful AI Behavior∗
Sadia Asif
asifs@rpi.edu
Department of Computer Science
Rensselaer Polytechnic Institute
Troy, New York, United States
Israel Antonio Rosales Laguan
anthony.laguan@penguinmails.com
Independent Researcher
Colombia
Haris Khan
mhariskhan.ee44ceme@student.nust.edu.pk
College of Electrical and Mechanical Engineering
National University of Sciences and Technology
Rawalpindi, Pakistan
Shumaila Asif
sasif.ee44ceme@student.nust.ceme.edu.pk
College of Electrical and Mechanical Engineering
National University of Sciences and Technology
Rawalpindi, Pakistan
Muneeb Asif
masif.bese20seecs@seecs.edu.pk
School of Electrical Engineering & Computer Science
National University of Sciences and Technology
Islamabad, Pakistan
Abstract
The proliferation of Large Language Models (LLMs) has intensified concerns about manip-
ulative or deceptive behaviors that can undermine user autonomy, trust, and well-being.
Existing safety benchmarks predominantly rely on coarse binary labels and fail to capture
the nuanced psychological and social mechanisms constituting manipulation. We intro-
duce DarkPatterns-LLM, a comprehensive benchmark dataset and diagnostic frame-
work for fine-grained assessment of manipulative content in LLM outputs across seven
harm categories: Legal/Power, Psychological, Emotional, Physical, Autonomy, Economic,
and Societal Harm. Our framework implements a four-layer analytical pipeline comprising
Multi-Granular Detection (MGD), Multi-Scale Intent Analysis (MSIAN), Threat Harmo-
nization Protocol (THP), and Deep Contextual Risk Alignment (DCRA). The dataset
contains 401 meticulously curated examples with instruction-response pairs and expert an-
notations. Through evaluation of state-of-the-art models including GPT-4, Claude 3.5, and
LLaMA-3-70B, we observe significant performance disparities (65.2%–89.7%) and consis-
tent weaknesses in detecting autonomy-undermining patterns. DarkPatterns-LLM estab-
lishes the first standardized, multi-dimensional benchmark for manipulation detection in
LLMs, offering actionable diagnostics toward more trustworthy AI systems.
∗. Project website:
https://sadia-sigma-lab.github.io/darkpatterns-llm/.
Dataset repository:
https://github.com/sadia-sigma-lab/Benchmark-dataset-for-dark-patterns-in-llms.
1
arXiv:2512.22470v1 [cs.AI] 27 Dec 2025
Keywords:
AI Safety, Manipulation Detection, Dark Patterns, Ethical AI, Benchmark-
ing, Large Language Models
1 Introduction
Large Language Models (LLMs) have rapidly become integral to decision-making across
high-stakes domains including healthcare, finance, education, and governance. While re-
cent alignment techniques such as Reinforcement Learning from Human Feedback (RLHF)
(Ouyang et al., 2022) and Constitutional AI (Bai et al., 2022) have improved harmlessness
against overt toxicity, they remain largely ineffective against subtle, psychologically manip-
ulative behaviors. These behaviors, often termed dark patterns, exploit cognitive biases,
emotional vulnerabilities, and power asymmetries without triggering conventional safety
filters (Mathur et al., 2019; Gray et al., 2023).
The consequences of AI-mediated manipulation extend beyond individual interactions.
Recent policy instruments such as the European AI Act (2024) explicitly classify manipu-
lation as high-risk, requiring continuous monitoring (EU AI Act, 2024). However, existing
safety benchmarks like TruthfulQA (Lin et al., 2022), SafetyBench (Zhang et al., 2023), and
AdvBench (Zou et al., 2023) are limited to binary assessments that obscure mechanisms,
targets, and temporal dynamics of harm.
To address these limitations, we introduce DarkPatterns-LLM, a comprehensive bench-
mark designed to evaluate manipulative behaviors at multiple levels of granularity. Our
framework moves beyond binary judgments toward structured, explainable safety analysis
that quantifies manipulation strength, affected stakeholder groups, and propagation poten-
tial.
Contributions. Our work makes the following contributions:
• A benchmark dataset of 401 examples across seven harm categories with paired
safe/unsafe responses and expert annotations
• A four-layer analytical pipeline (MGD, MSIAN, THP, DCRA) for multi-level manip-
ulation evaluation
• Novel quantitative metrics (MRI, CRS, SIAS, THDS) for fine-grained benchmarking
• Systematic evaluation of six state-of-the-art LLMs revealing performance disparities
and systematic weaknesses
2 Related Work
AI Safety and Harmlessness.
Recent work on AI safety has focused on alignment
techniques (Christiano et al., 2017; Bai et al., 2022) and red-teaming (Perez et al., 2022).
While RLHF has improved surface-level safety, studies show persistent vulnerabilities to
jailbreaking (Wei et al., 2024) and subtle manipulation (Wang et al., 2024).
Safety Benchmarks. Existing benchmarks include TruthfulQA for truthfulness (Lin
et al., 2022), SafetyBench for safety risks (Zhang et al.,
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.