📝 Original Info
- Title: Comparative Analysis of Deep Learning Models for Perception in Autonomous Vehicles
- ArXiv ID: 2512.21673
- Date: 2025-12-25
- Authors: Researchers from original ArXiv paper
📝 Abstract
Recently, a plethora of machine learning (ML) and deep learning (DL) algorithms have been proposed to achieve the efficiency, safety, and reliability of autonomous vehicles (AVs). The AVs use a perception system to detect, localize, and identify other vehicles, pedestrians, and road signs to perform safe navigation and decision-making. In this paper, we compare the performance of DL models, including YOLO-NAS and YOLOv8, for a detection-based perception task. We capture a custom dataset and experiment with both DL models using our custom dataset. Our analysis reveals that the YOLOv8s model saves 75% of training time compared to the YOLO-NAS model. In addition, the YOLOv8s model (83%) outperforms the YOLO-NAS model (81%) when the target is to achieve the highest object detection accuracy. These comparative analyses of these new emerging DL models will allow the relevant research community to understand the models' performance under real-world use case scenarios.
💡 Deep Analysis
Deep Dive into Comparative Analysis of Deep Learning Models for Perception in Autonomous Vehicles.
Recently, a plethora of machine learning (ML) and deep learning (DL) algorithms have been proposed to achieve the efficiency, safety, and reliability of autonomous vehicles (AVs). The AVs use a perception system to detect, localize, and identify other vehicles, pedestrians, and road signs to perform safe navigation and decision-making. In this paper, we compare the performance of DL models, including YOLO-NAS and YOLOv8, for a detection-based perception task. We capture a custom dataset and experiment with both DL models using our custom dataset. Our analysis reveals that the YOLOv8s model saves 75% of training time compared to the YOLO-NAS model. In addition, the YOLOv8s model (83%) outperforms the YOLO-NAS model (81%) when the target is to achieve the highest object detection accuracy. These comparative analyses of these new emerging DL models will allow the relevant research community to understand the models’ performance under real-world use case scenarios.
📄 Full Content
Comparative Analysis of Deep Learning Models
for Perception in Autonomous Vehicles
Jalal Khan
College of Information Technology, United Arab Emirates University,
United Arab Emirates, Al Ain, UAE.
Contributing authors: mjalal@uaeu.ac.ae;
Abstract
Recently, a plethora of machine learning (ML) and deep learning (DL) algo-
rithms have been proposed to achieve the efficiency, safety, and reliability of
autonomous vehicles (AVs). The AVs use a perception system to detect, localize,
and identify other vehicles, pedestrians, and road signs to perform safe navi-
gation and decision-making. In this paper, we compare the performance of DL
models, including YOLO-NAS and YOLOv8, for a detection-based perception
task. We capture a custom dataset and experiment with both DL models using
our custom dataset. Our analysis reveals that the YOLOv8s model saves 75%
of training time compared to the YOLO-NAS model. In addition, the YOLOv8s
model (83%) outperforms the YOLO-NAS model (81%) when the target is to
achieve the highest object detection accuracy. These comparative analyses of
these new emerging DL models will allow the relevant research community to
understand the models’ performance under real-world use case scenarios.
Keywords: Deep learning; YOLO-NAS; YOLOv8; Perception; Autonomous vehicles.
1 Introduction
The United States (DARPA Agency) and Europe (EUREKA Prometheus Project)
made significant contributions to enhance the necessary technologies, research, and
1
arXiv:2512.21673v1 [cs.CV] 25 Dec 2025
development for autonomous driving (AD) technology [1–3]. In addition, the suc-
cess of deep neural networks in ImageNet allowed relevant research communities
to propose significant deep learning (DL) models to detect objects for the percep-
tion system of autonomous vehicles (AVs) [4–6]. For instance, Sparse4D-v3, Far3D,
HoP, Li, StreamPETR-Large, VCD-A, UniM2AE, SparseBEV, and VideoBEV tech-
niques are proposed for object detection based on nuScenes dataset during the year
2023 [7]. These models introduce various unique approaches to perception tasks and
are designed to improve accuracy and speed in challenging environments. For object
detection, the newly available DL-based architectures, i.e., the YOLOv8 and YOLO-
NAS models, are compared on the COCO dataset using NVIDIA T4 [8]. However,
these models have not yet been extensively compared and evaluated for performance
analysis using a custom road dataset. In this study, we investigate the impact of
DL models on object-detection-based perception tasks for AVs. In this connection,
we consider a custom road dataset from [9]. We compared and evaluated YOLOv8s
and YOLO-NAS using well-known performance metrics, such as mean average preci-
sion (mAP), and confusion matrix values. The contributions of this research work are
comparing the performance of DL models used by AVs for object detection tasks.
2 Methodology
The perception system of AVs perceives road objects using state-of-the-art (SOTA)
DL-based models. Since the YOLOv8s and YOLO-NAS-based DL models have not
been explored extensively, we select them for experimental work considering object
detection-based perception tasks of AVs. For object detection tasks, we use a camera
as the primary capturing device to capture data (video clips) on complex urban road
segments. We record a total of 15,100 images during the data-capturing phase. Next,
we reduce the initial capture dataset to 1000 images using different pre-processing
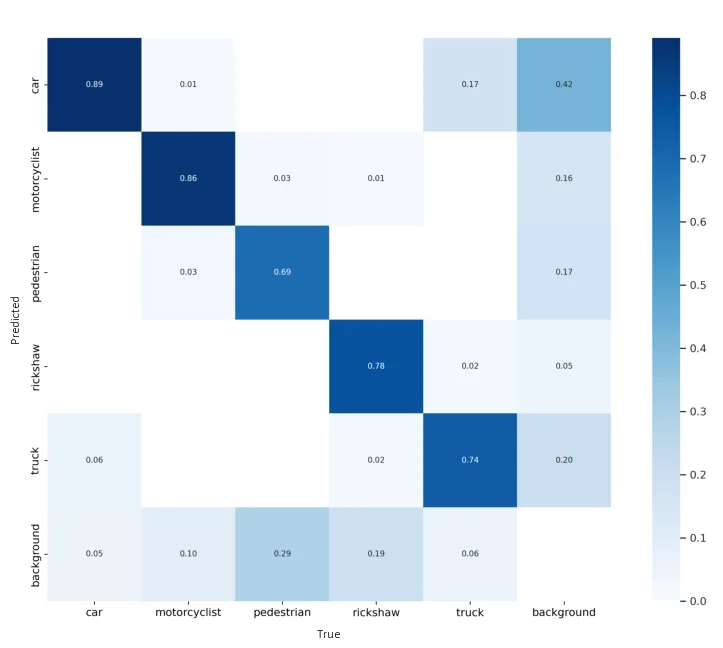
techniques. We manually label our final dataset, which contains five different classes
i.e., cars, pedestrians, motorcyclists, trucks, and rickshaws. In addition, we split the
dataset into a train set (70%), a validation set (20%), and a test set (10%). The ratio-
nale behind the YOLOv8s and YOLO-NAS is that the selection of a single DL model
depends on the underlying use case scenarios [5]. Now that we have our pre-processed
dataset and DL-based models, we start to perform the training, validation, and testing
of our models. It should be highlighted that we use the basic hyperparameters (i.e.,
100 epochs, 16 batch size, etc.) to get a fair performance comparison of both DL mod-
els. Now that we have our custom-trained DL-based models, we start investigating the
performance of each model.
3 Experiments
The experiments were conducted using the NVIDIA Tesla V100 GPU model, 16.0GB
of GPU RAM, 12.7GB of System RAM, etc., using Google Colab Pro platform.
The NVIDIA Tesla V100 GPU was accessed through Google Chrome (version 117.0)
installed in a physical machine of Intel Quad-Core i7@ 3.4GHz with 32GB NVIDIA
GeForce GTX 680MX Graphics and a 27-inch (2560x1440) build-in Display. The soft-
ware stack includes Python v.3.11.4 (the newest major release), and its rich family of
2
Fig. 1: Comparison of mAP@0.5 Performance Metrics.
libraries e.g., PyTorch, glob, etc. The YOLOv8s and YOLO-NAS based DL models
were implemented through their respective packages using the latest version of Python
programming language
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.