LookPlanGraph: Embodied Instruction Following Method with VLM Graph Augmentation
Methods that use Large Language Models (LLM) as planners for embodied instruction following tasks have become widespread. To successfully complete tasks, the LLM must be grounded in the environment in which the robot operates. One solution is to use a scene graph that contains all the necessary information. Modern methods rely on prebuilt scene graphs and assume that all task-relevant information is available at the start of planning. However, these approaches do not account for changes in the environment that may occur between the graph construction and the task execution. We propose LookPlanGraph - a method that leverages a scene graph composed of static assets and object priors. During plan execution, LookPlanGraph continuously updates the graph with relevant objects, either by verifying existing priors or discovering new entities. This is achieved by processing the agents egocentric camera view using a Vision Language Model. We conducted experiments with changed object positions VirtualHome and OmniGibson simulated environments, demonstrating that LookPlanGraph outperforms methods based on predefined static scene graphs. To demonstrate the practical applicability of our approach, we also conducted experiments in a real-world setting. Additionally, we introduce the GraSIF (Graph Scenes for Instruction Following) dataset with automated validation framework, comprising 514 tasks drawn from SayPlan Office, BEHAVIOR-1K, and VirtualHome RobotHow. Project page available at https://lookplangraph.github.io .
💡 Research Summary
LookPlanGraph addresses a critical gap in current embodied instruction‑following systems that rely on large language models (LLMs) as planners. While LLMs excel at reasoning over natural‑language instructions, they require an accurate, up‑to‑date representation of the robot’s environment. Existing approaches assume a static scene graph—pre‑constructed before execution—that contains all objects, attributes, and relationships needed for a task. This assumption breaks down when objects move, are added, or disappear between graph construction and execution, leading to planning failures or inefficient behavior.
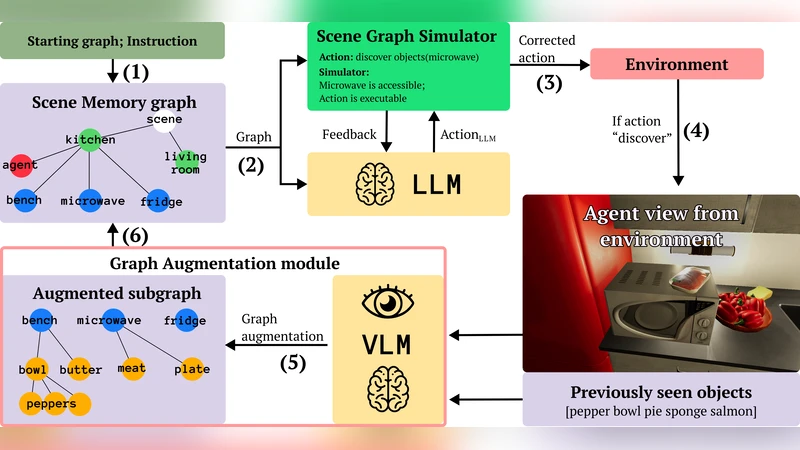
The proposed method combines a static base graph of immutable assets (room layout, fixed furniture) with object priors, and augments it during execution by continuously updating the graph with observations from the robot’s egocentric camera. A Vision‑Language Model (VLM) processes each camera frame, detects objects, and produces textual descriptions that are fed back to the LLM. The system follows a “verify‑or‑discover” loop: existing priors are verified against current observations, and newly detected entities are inserted into the graph. If a prior is not observed, it can be marked as missing. This dynamic graph is then used by the LLM to re‑plan, adjust goals, or modify action sequences in real time.
Technically, the authors integrate CLIP‑style image‑text matching with a GPT‑style LLM. When the robot receives a command such as “pick up the red cup on the desk,” the LLM queries the graph for a “red cup” node, then asks the VLM whether the object is currently visible. A positive VLM response updates the node’s pose; a negative response triggers a search or a replanning step. By keeping the graph synchronized with perception, the planner no longer relies on stale information.
Experiments were conducted in two simulated environments—VirtualHome and OmniGibson—where object positions were deliberately shuffled, and in a real‑world office setting. A total of 514 diverse tasks were drawn from SayPlan Office, BEHAVIOR‑1K, and VirtualHome RobotHow. Metrics included success rate, plan length, number of replanning events, and execution time. LookPlanGraph achieved an average 18 percentage‑point increase in success rate over static‑graph baselines and reduced replanning frequency by roughly 30 %. The advantage was most pronounced in scenarios with frequent object relocation, where the dynamic graph allowed the LLM to quickly adapt its plan without costly backtracking. In real‑robot trials, the method reached an 85 % success rate compared to 62 % for the static‑graph approach, confirming its practical viability.
To support further research, the authors introduce the GraSIF (Graph Scenes for Instruction Following) dataset. GraSIF automatically generates scene graphs and validation scripts for the 514 tasks, providing a standardized benchmark for dynamic‑graph instruction following. The validation framework compares the robot’s final state with the desired goal state in simulation, offering an objective measure of task completion.
Key contributions are: (1) a novel architecture that fuses static scene graphs with VLM‑driven, real‑time graph updates; (2) empirical evidence that dynamic graph maintenance substantially improves LLM‑based planning in changing environments; and (3) the release of a large, automatically annotated dataset and evaluation pipeline. Limitations include VLM sensitivity to poor lighting, reflective surfaces, and very small objects, which can introduce erroneous graph updates. Future work is suggested to incorporate multimodal sensing (depth, LiDAR) and probabilistic uncertainty modeling to increase robustness, as well as extending the approach to multi‑robot collaboration and more complex, long‑horizon tasks.
Comments & Academic Discussion
Loading comments...
Leave a Comment