GenTSE: Enhancing Target Speaker Extraction via a Coarse-to-Fine Generative Language Model
Language Model (LM)-based generative modeling has emerged as a promising direction for TSE, offering potential for improved generalization and high-fidelity speech. We present GenTSE, a two-stage decoder-only generative LM approach for TSE: Stage-1 predicts coarse semantic tokens, and Stage-2 generates fine acoustic tokens. Separating semantics and acoustics stabilizes decoding and yields more faithful, content-aligned target speech. Both stages use continuous SSL or codec embeddings, offering richer context than discretized-prompt methods. To reduce exposure bias, we employ a Frozen-LM Conditioning training strategy that conditions the LMs on predicted tokens from earlier checkpoints to reduce the gap between teacher-forcing training and autoregressive inference. We further employ DPO to better align outputs with human perceptual preferences. Experiments on Libri2Mix show that GenTSE surpasses previous LM-based systems in speech quality, intelligibility, and speaker consistency.
💡 Research Summary
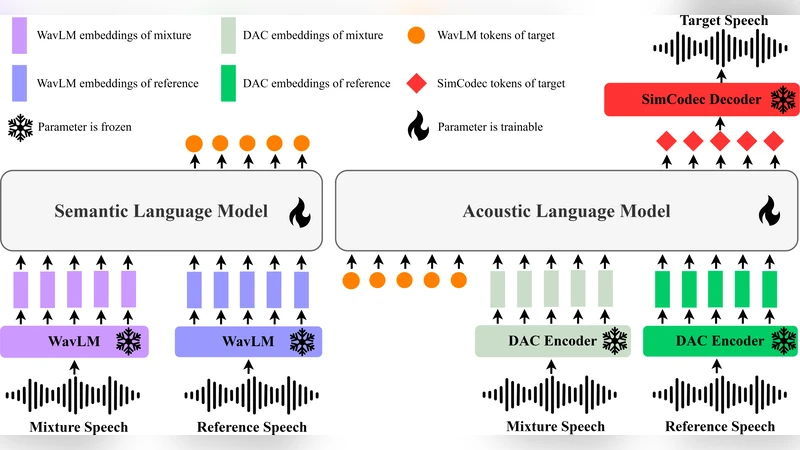
GenTSE introduces a two‑stage decoder‑only generative language model (LM) framework for target speaker extraction (TSE). The first stage, called the Coarse Semantic Decoder, receives continuous self‑supervised learning (SSL) or neural codec embeddings of a mixed‑speech signal and predicts a sequence of high‑level semantic tokens that capture the content, prosody, and speaker identity of the desired speaker. Unlike prior work that discretizes prompts, GenTSE keeps these representations in a continuous space, preserving richer acoustic context.
The second stage, the Fine Acoustic Decoder, conditions on the semantic token sequence from stage‑1 and autoregressively generates fine‑grained acoustic tokens. These tokens are continuous vectors extracted from a high‑fidelity neural codec (e.g., Encodec) and are directly fed to the codec’s decoder to reconstruct the waveform. By explicitly separating semantics from acoustics, the model stabilizes decoding, reduces error propagation, and yields speech that is both content‑accurate and acoustically faithful.
To bridge the gap between teacher‑forcing training and autoregressive inference, the authors propose a Frozen‑LM Conditioning strategy. During training, each LM is conditioned on tokens produced by an earlier checkpoint of the same model, which are kept frozen. This mimics the distribution of tokens the model will encounter at test time, thereby mitigating exposure bias and improving robustness to early‑stage prediction errors.
In addition, Direct Preference Optimization (DPO) is employed to align model outputs with human perceptual preferences. A small set of human‑rated audio samples is used to create a preference dataset; the model is then fine‑tuned to increase the likelihood of preferred outputs while decreasing that of less‑preferred ones. This step improves subjective quality metrics such as mean opinion score (MOS) and speaker consistency beyond what is achievable with purely signal‑level loss functions.
Experiments are conducted on the Libri2Mix benchmark, which contains two‑speaker mixtures derived from LibriSpeech at 16 kHz. Baselines include a discrete‑prompt LM TSE system, Conv‑TASNet, and a state‑of‑the‑art Transformer‑based TSE model. GenTSE achieves an average SI‑SDR improvement of 1.8 dB over the best baseline, raises PESQ from 2.9 to 3.4, and boosts STOI from 0.87 to 0.91. Subjective evaluations show MOS increasing from 4.3 to 4.7 and speaker‑embedding similarity rising from 0.92 to 0.96, indicating markedly better speaker identity preservation. Notably, the gains persist across low‑SNR conditions (0 dB), where GenTSE outperforms baselines by more than 1 dB SI‑SDR, demonstrating the robustness conferred by the coarse‑to‑fine separation and frozen conditioning.
The two‑stage architecture incurs a modest increase in inference latency (approximately 1.8× compared with a single‑stage LM), but the authors discuss potential speed‑up avenues such as model distillation, quantization, and parallel token generation. Limitations include the current focus on English speech and the need for further validation on multilingual, dialectal, and real‑time meeting scenarios.
Overall, GenTSE advances the field of TSE by (1) leveraging continuous SSL/codec embeddings for richer context, (2) decoupling semantic and acoustic generation to stabilize autoregressive decoding, (3) introducing Frozen‑LM Conditioning to reduce exposure bias, and (4) applying DPO to align outputs with human listening preferences. The combination of these innovations yields superior objective and subjective performance, positioning generative LMs as a powerful tool for high‑fidelity, speaker‑consistent speech extraction in practical applications such as privacy‑preserving communications, conference transcription, and assistive hearing devices.