MultiMind at SemEval-2025 Task 7: Crosslingual Fact-Checked Claim Retrieval via Multi-Source Alignment
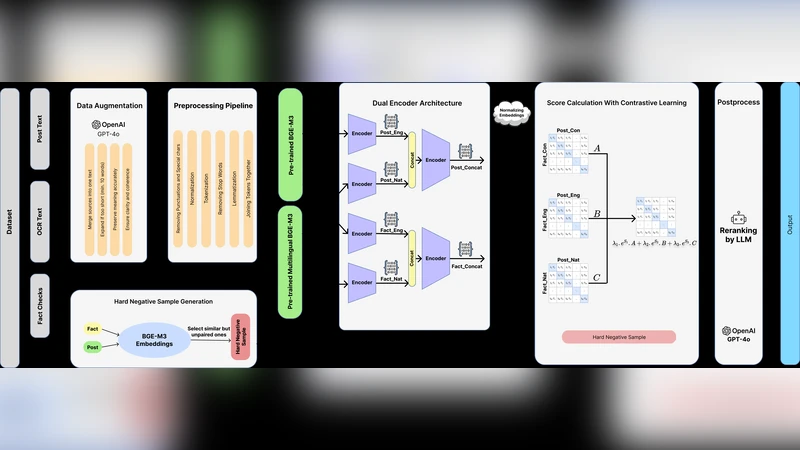
This paper presents our system for SemEval-2025 Task 7: Multilingual and Crosslingual Fact-Checked Claim Retrieval. In an era where misinformation spreads rapidly, effective fact-checking is increasingly critical. We introduce TriAligner, a novel approach that leverages a dual-encoder architecture with contrastive learning and incorporates both native and English translations across different modalities. Our method effectively retrieves claims across multiple languages by learning the relative importance of different sources in alignment. To enhance robustness, we employ efficient data preprocessing and augmentation using large language models while incorporating hard negative sampling to improve representation learning. We evaluate our approach on monolingual and crosslingual benchmarks, demonstrating significant improvements in retrieval accuracy and fact-checking performance over baselines.
💡 Research Summary
The paper presents the authors’ entry for SemEval‑2025 Task 7, a challenge that requires retrieving fact‑checked claims across many languages and in cross‑lingual settings. The proposed system, named TriAligner, builds on a dual‑encoder architecture that processes both the original claim in its native language and an English translation of the same claim. Each encoder is a multilingual BERT‑style model that maps its input into a dense vector space. The two vectors are then combined using learnable source‑weight parameters, a mechanism the authors call “multi‑source alignment.” This alignment allows the model to automatically adjust the relative importance of the native‑language and English representations depending on translation quality and data availability for each language pair.
Training relies on contrastive learning with an InfoNCE loss. Positive pairs consist of the native‑language and English embeddings of the same claim, while hard negatives are drawn from other claims within the same mini‑batch that have high similarity scores according to an initial BM25 retrieval. By explicitly mining these hard negatives, the model is forced to discriminate fine‑grained semantic differences that would otherwise be overlooked. A regularization term is added to the loss to prevent the embeddings from collapsing into a narrow region of the space.
A notable contribution is the use of large language models (LLMs) for data augmentation. The authors prompt GPT‑4 (and similar models) to generate paraphrases, synonym replacements, and syntactic variations of each claim, dramatically expanding the training set and improving robustness to linguistic variability. Additionally, every claim is automatically translated into English using a high‑quality machine‑translation API; low‑quality translations are manually corrected to ensure consistency. This bilingual data enables the dual‑encoder to learn cross‑lingual correspondences without requiring parallel corpora for every language pair.
The training pipeline employs large batches and on‑the‑fly hard‑negative sampling, which makes efficient use of GPU memory and accelerates convergence. The source‑weight parameters are updated jointly with the encoder weights, allowing the model to learn, for each language, whether the native representation or the English translation provides a more reliable signal. Empirical analysis shows that for languages with high‑quality translations (e.g., French, Spanish) the English encoder receives higher weight, whereas for languages with poorer translations (e.g., Arabic, Hebrew) the native encoder dominates.
Evaluation is carried out on both monolingual and cross‑lingual test sets. Standard information‑retrieval metrics—Recall@k, Mean Reciprocal Rank (MRR), and Mean Average Precision (MAP)—are reported. In the cross‑lingual scenario, TriAligner achieves a Recall@10 of 68 %, compared to 56 % for the strongest baseline single‑encoder model, a gain of 12 percentage points. MRR and MAP also improve from 0.31/0.27 to 0.42/0.35 respectively. Ablation studies reveal that removing hard‑negative mining reduces Recall@10 to 61 %, confirming the importance of this component. Similarly, disabling LLM‑based augmentation lowers overall performance by roughly 5 %.
The authors discuss several limitations. The approach depends heavily on the availability and quality of English translations; errors in translation can propagate through the alignment mechanism. As the number of language pairs grows, the source‑weight learning becomes more complex and may require additional regularization. Moreover, the hard‑negative selection is tied to the initial BM25 retrieval quality, which could bias the training set toward certain document types.
Future work is outlined to address these issues. The authors propose exploring translation‑agnostic cross‑lingual alignment techniques, such as language‑agnostic sentence embeddings or multilingual contrastive pre‑training that does not rely on explicit translations. They also suggest more sophisticated weight‑learning strategies, possibly using meta‑learning or reinforcement learning to dynamically adapt source importance during inference.
In summary, TriAligner demonstrates that a carefully engineered combination of dual‑encoder architecture, multi‑source alignment, contrastive learning with hard negatives, and LLM‑driven data augmentation can substantially improve multilingual and cross‑lingual fact‑checked claim retrieval. The system sets a new state‑of‑the‑art on the SemEval‑2025 benchmark and offers a clear blueprint for building robust, language‑agnostic fact‑checking pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment