📝 Original Info
- Title: LLM Swiss Round: Aggregating Multi-Benchmark Performance via Competitive Swiss-System Dynamics
- ArXiv ID: 2512.21010
- Date: 2025-12-24
- Authors: Researchers from original ArXiv paper
📝 Abstract
The rapid proliferation of Large Language Models (LLMs) and diverse specialized benchmarks necessitates a shift from fragmented, task-specific metrics to a holistic, competitive ranking system that effectively aggregates performance across multiple ability dimensions. Primarily using static scoring, current evaluation methods are fundamentally limited. They struggle to determine the proper mix ratio across diverse benchmarks, and critically, they fail to capture a model's dynamic competitive fitness or its vulnerability when confronted with sequential, high-stakes tasks. To address this, we introduce the novel Competitive Swiss-System Dynamics (CSD) framework. CSD simulates a multi-round, sequential contest where models are dynamically paired across a curated sequence of benchmarks based on their accumulated win-loss record. And Monte Carlo Simulation ($N=100,000$ iterations) is used to approximate the statistically robust Expected Win Score ($E[S_m]$), which eliminates the noise of random pairing and early-round luck. Furthermore, we implement a Failure Sensitivity Analysis by parameterizing the per-round elimination quantity ($T_k$), which allows us to profile models based on their risk appetite--distinguishing between robust generalists and aggressive specialists. We demonstrate that CSD provides a more nuanced and context-aware ranking than traditional aggregate scoring and static pairwise models, representing a vital step towards risk-informed, next-generation LLM evaluation.
💡 Deep Analysis
Deep Dive into LLM Swiss Round: Aggregating Multi-Benchmark Performance via Competitive Swiss-System Dynamics.
The rapid proliferation of Large Language Models (LLMs) and diverse specialized benchmarks necessitates a shift from fragmented, task-specific metrics to a holistic, competitive ranking system that effectively aggregates performance across multiple ability dimensions. Primarily using static scoring, current evaluation methods are fundamentally limited. They struggle to determine the proper mix ratio across diverse benchmarks, and critically, they fail to capture a model’s dynamic competitive fitness or its vulnerability when confronted with sequential, high-stakes tasks. To address this, we introduce the novel Competitive Swiss-System Dynamics (CSD) framework. CSD simulates a multi-round, sequential contest where models are dynamically paired across a curated sequence of benchmarks based on their accumulated win-loss record. And Monte Carlo Simulation ($N=100,000$ iterations) is used to approximate the statistically robust Expected Win Score ($E[S_m]$), which eliminates the noise of ra
📄 Full Content
LLM Swiss Round: Aggregating Multi-Benchmark
Performance via Competitive Swiss-System Dynamics
Jiashuo Liu1,†, Jiayun Wu1,2,⋆, Chunjie Wu1, Jingkai Liu1, Zaiyuan Wang1, Huan Zhou1,
Wenhao Huang1,†, Hongseok Namkoong3
1ByteDance Seed, 2Carnegie Mellon University, 3Columbia University
†Corresponding author, ⋆Intern at ByteDance Seed
Abstract
The rapid proliferation of Large Language Models (LLMs) and diverse specialized benchmarks
necessitates a shift from fragmented, task-specific metrics to a holistic, competitive ranking system
that effectively aggregates performance across multiple ability dimensions. Primarily using static
scoring, current evaluation methods are fundamentally limited. They struggle to determine the
proper mix ratio across diverse benchmarks, and critically, they fail to capture a model’s dynamic
competitive fitness or its vulnerability when confronted with sequential, high-stakes tasks. To
address this, we introduce the novel Competitive Swiss-System Dynamics (CSD) framework. CSD
simulates a multi-round, sequential contest where models are dynamically paired across a curated
sequence of benchmarks based on their accumulated win-loss record. And Monte Carlo Simulation
(N = 100, 000 iterations) is used to approximate the statistically robust Expected Win Score
(E[Sm]), which eliminates the noise of random pairing and early-round luck. Furthermore, we
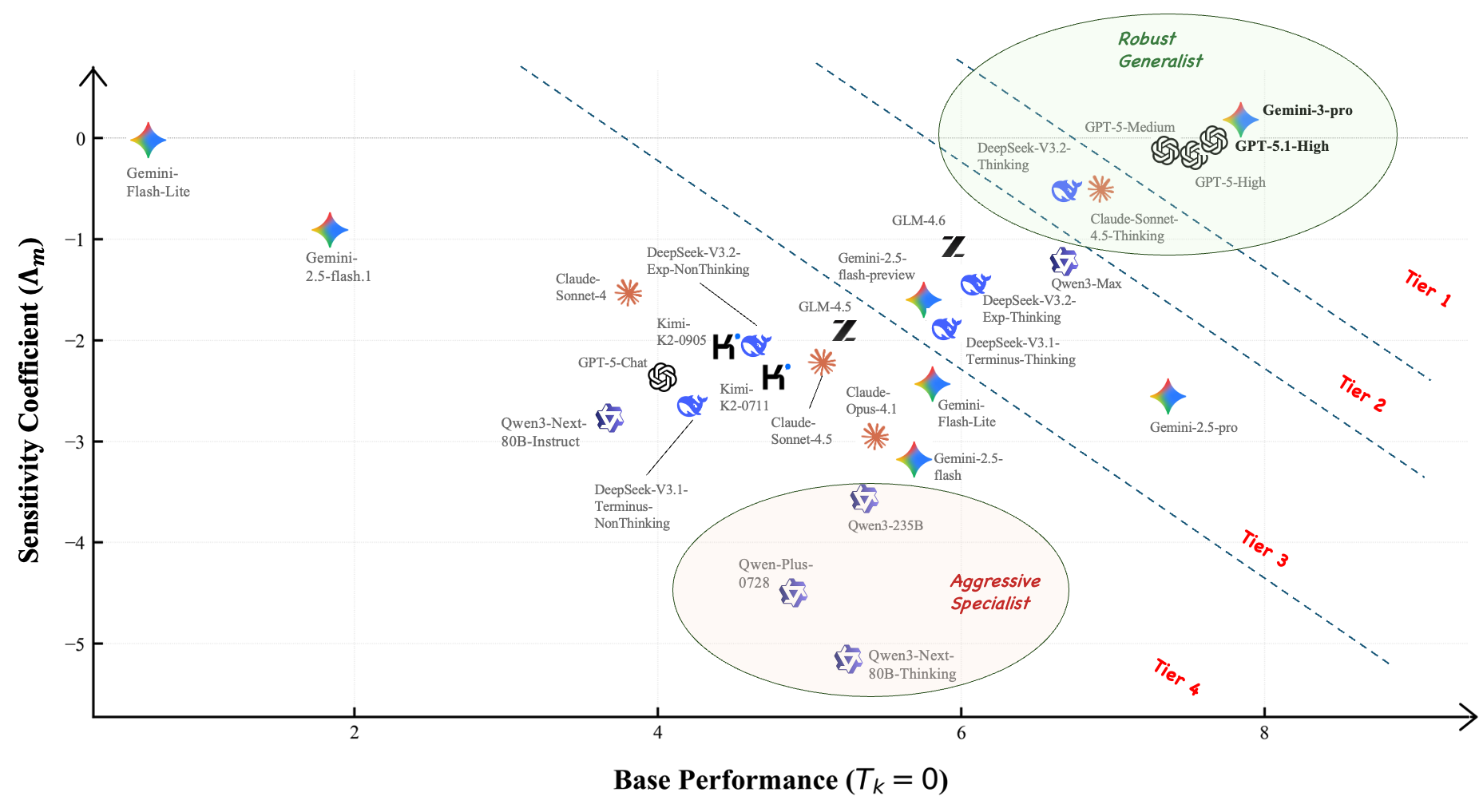
implement a Failure Sensitivity Analysis by parameterizing the per-round elimination quantity
(Tk), which allows us to profile models based on their risk appetite—distinguishing between robust
generalists and aggressive specialists. We demonstrate that CSD provides a more nuanced and
context-aware ranking than traditional aggregate scoring and static pairwise models, representing
a vital step towards risk-informed, next-generation LLM evaluation.
Correspondence: Jiashuo Liu, Wenhao Huang at {liujiashuo.77, huang.wenhao}@bytedance.com
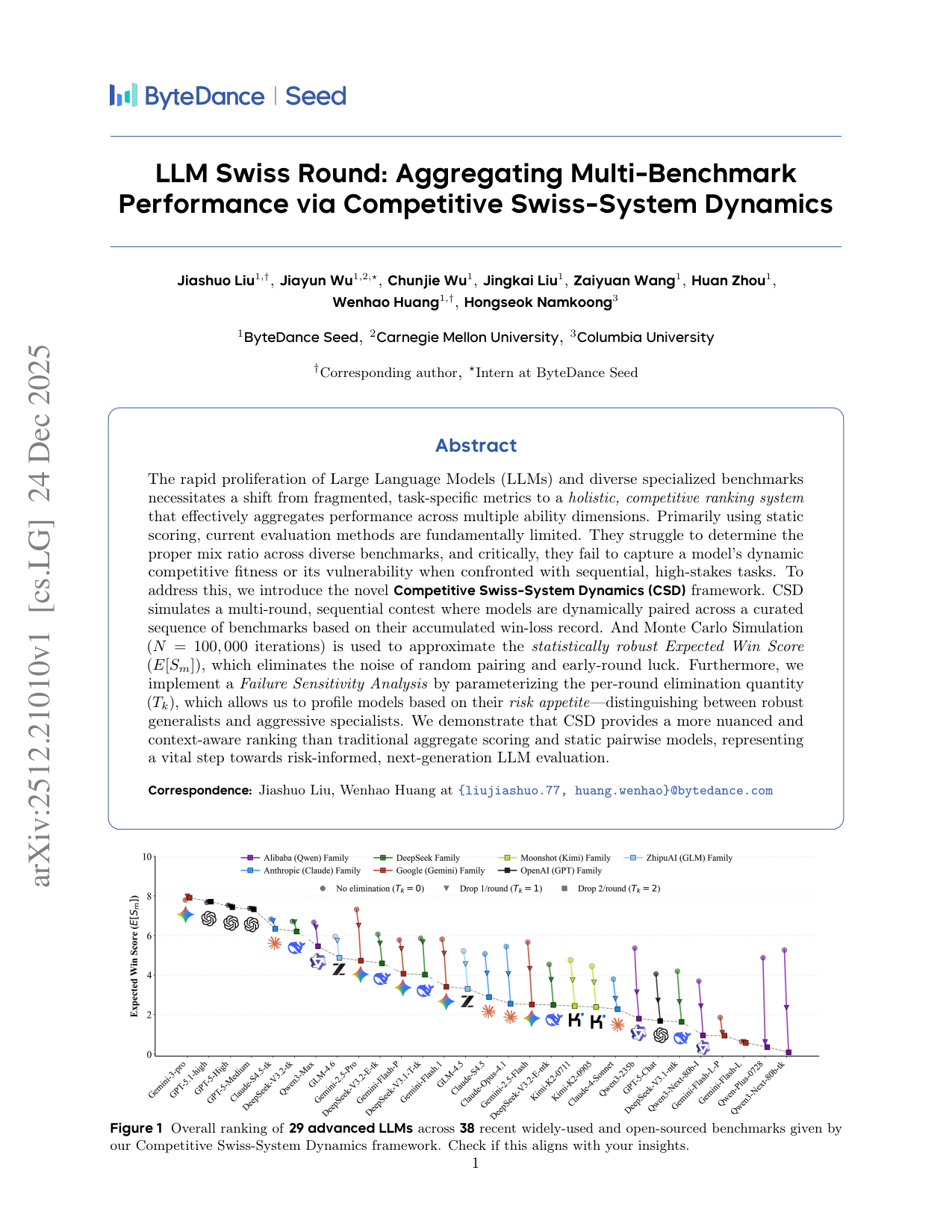
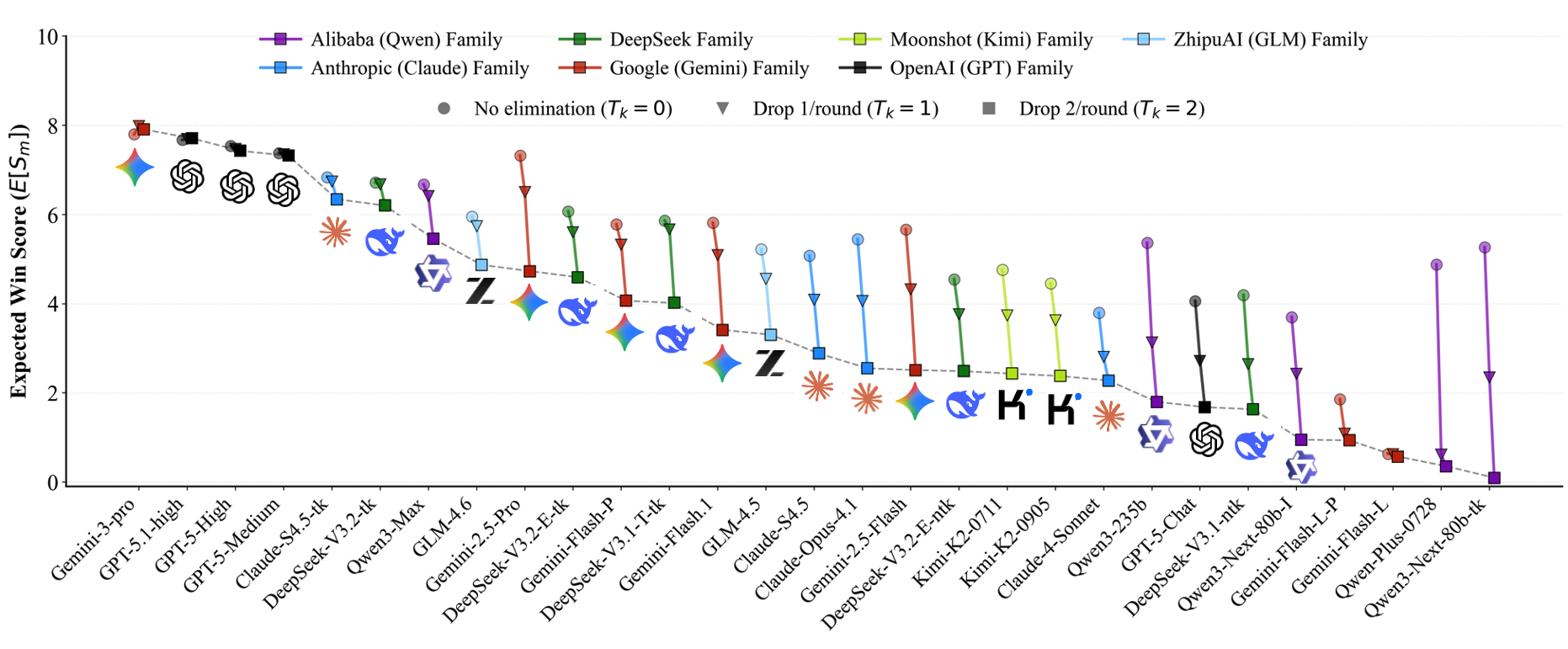
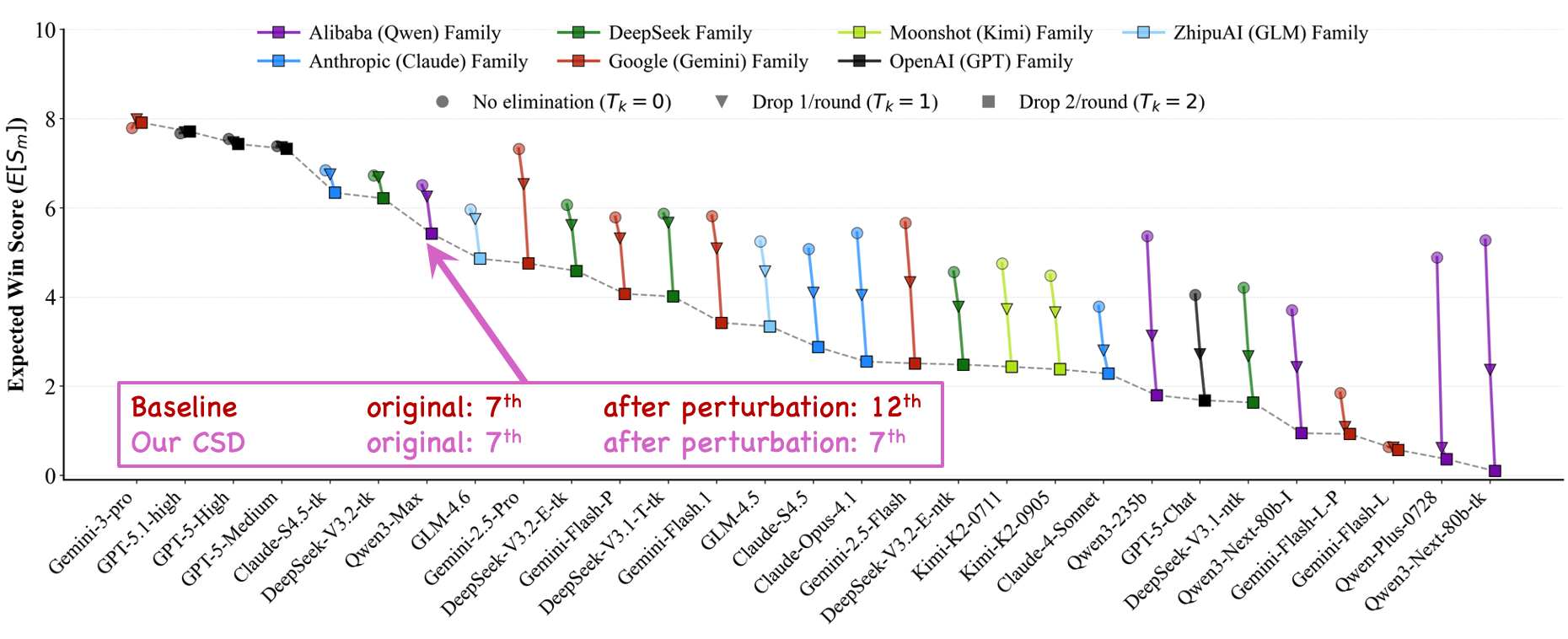
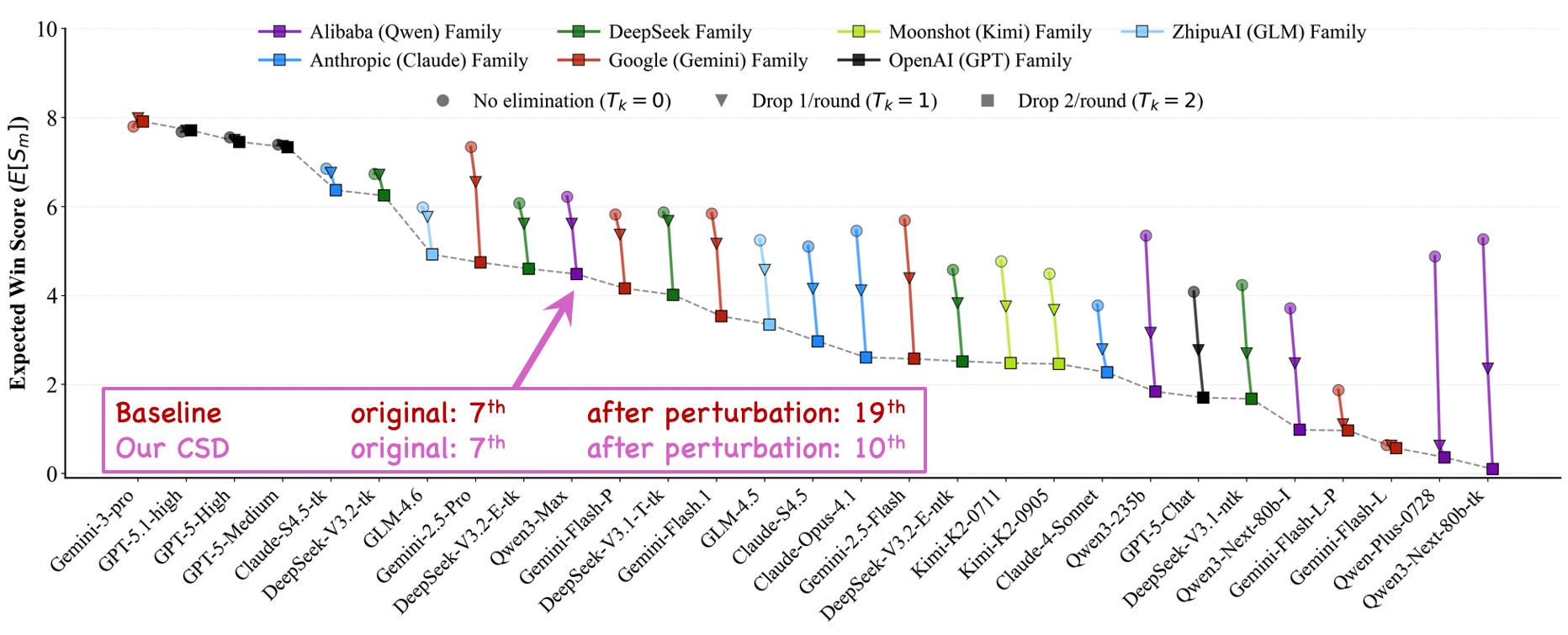
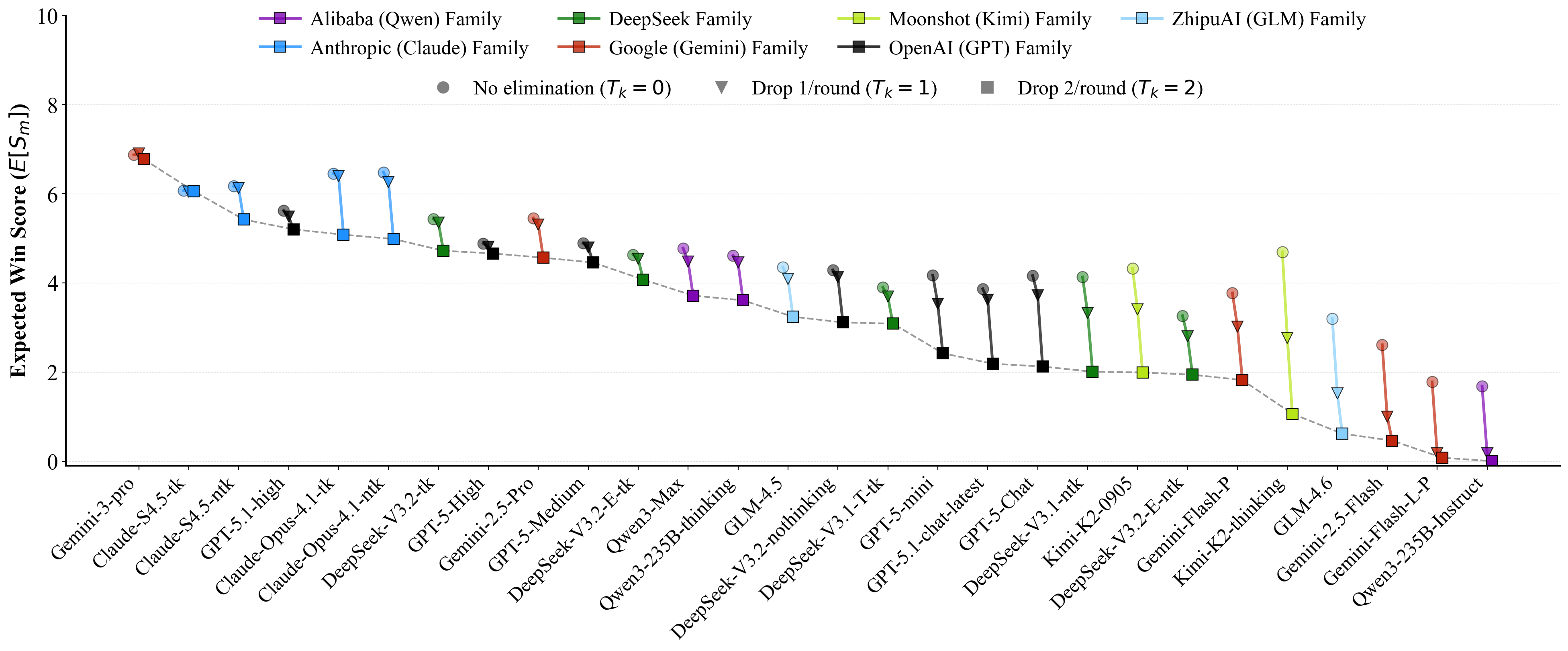
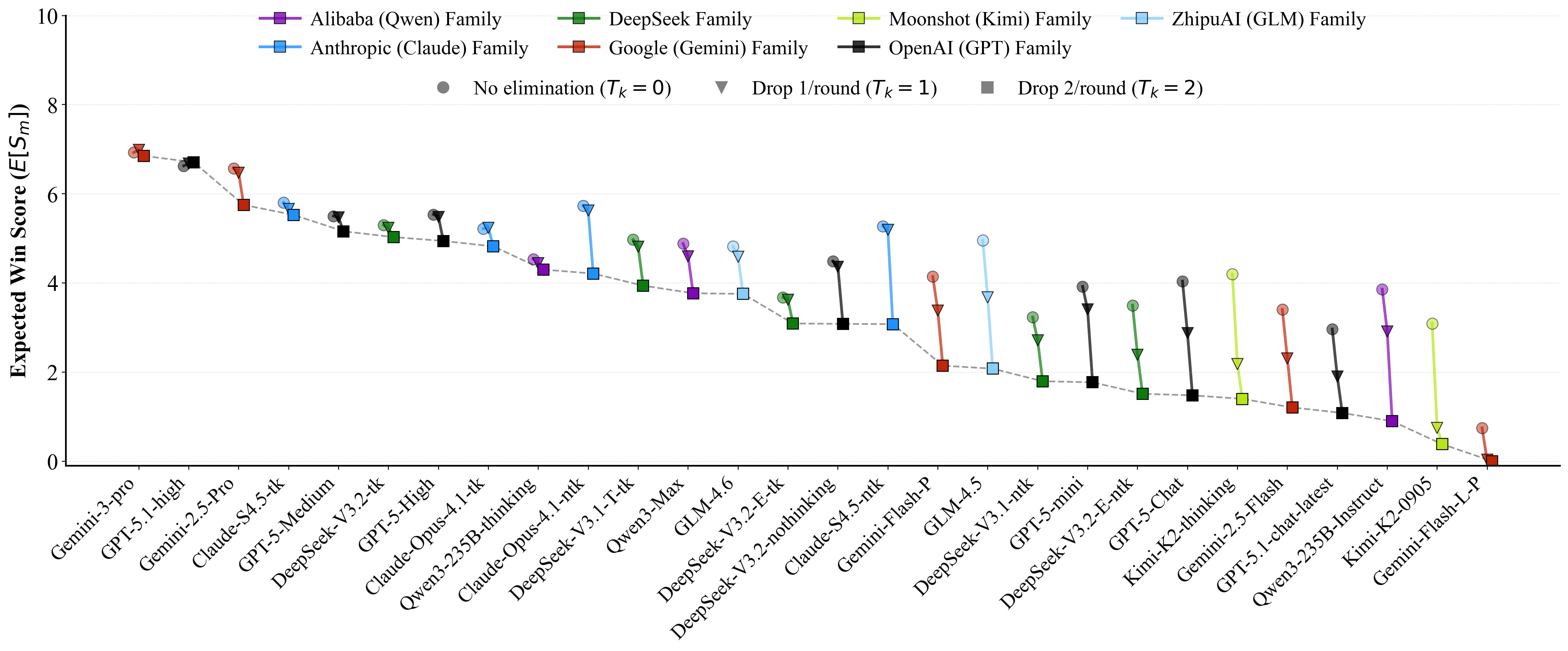
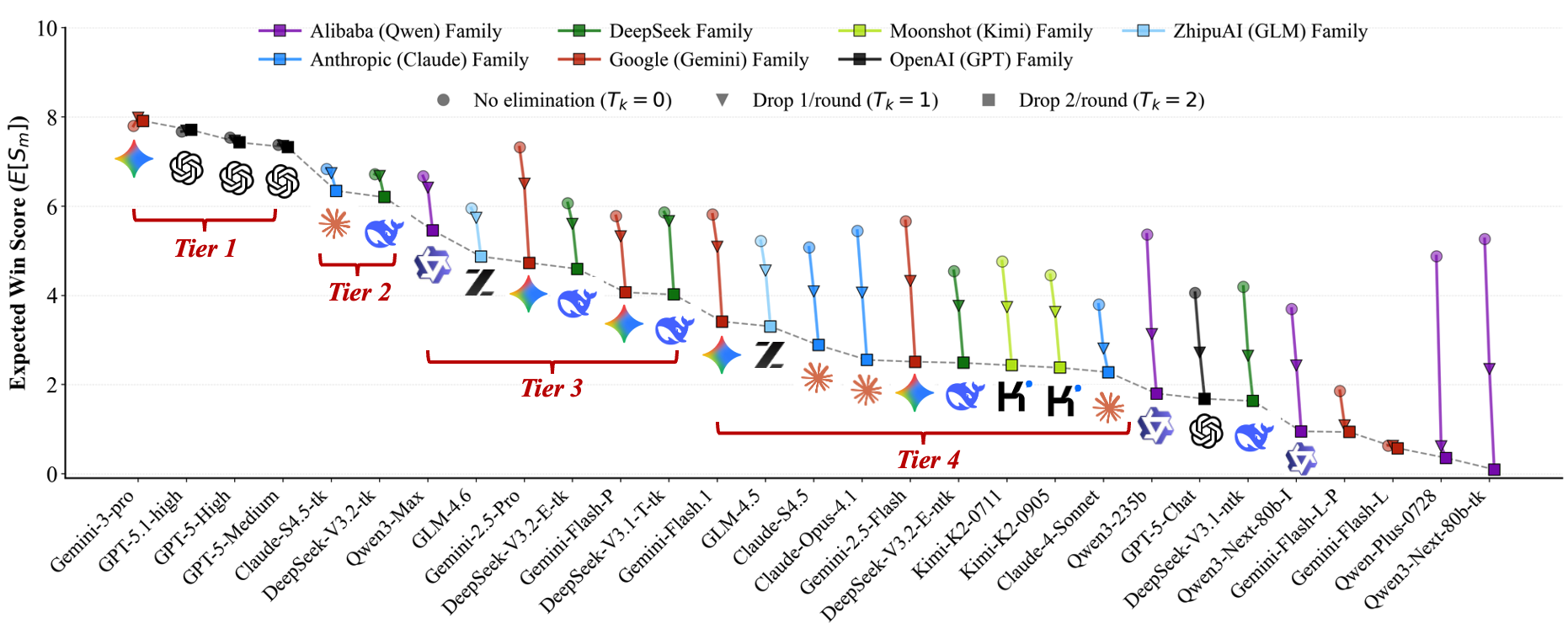
Figure 1 Overall ranking of 29 advanced LLMs across 38 recent widely-used and open-sourced benchmarks given by
our Competitive Swiss-System Dynamics framework. Check if this aligns with your insights.
1
arXiv:2512.21010v1 [cs.LG] 24 Dec 2025
1
Introduction
The field of Artificial Intelligence has been rapidly transformed by the emergence and widespread deployment
of Large Language Models (LLMs). These models exhibit remarkable capabilities across a multitude of tasks,
spanning complex reasoning [1, 3, 4, 8, 17, 20], code generation [11, 12, 19, 23, 31, 32], and nuanced natural
language understanding [21, 25]. Consequently, the development of robust evaluation methodologies has
become paramount. However, the sheer diversity of benchmarks presents a challenge for practical model
selection. In many downstream applications—ranging from selecting a backbone for autonomous agents to
enterprise API procurement—practitioners face a singular decision: they must identify one model that is
sufficiently robust to handle diverse, unpredictable workflows. This challenge is exacerbated by the scale
of modern LLM evaluation pipelines, which typically comprise hundreds of internal benchmarks. In such
high-dimensional settings, manual inspection of individual metrics is practically infeasible. Therefore, deriving
a unified ranking from fragmented benchmarks is not merely a simplification, but a necessity for resource
allocation and deployment decisions. While standardized leaderboards attempt to provide this unified view
(e.g., the “Intelligence” Index on https://artificialanalysis.ai/), they typically rely on simple aggregate
scores. This approach often masks critical shortcomings, treating a model with high variance (excellent in
one area, poor in another) as equivalent to a consistently reliable model. A truly deployable model must
demonstrate uniformly high performance to be trusted in a multi-stage competitive environment. To address
the need for a reliable selection criterion, the key problem studied in this paper is:
Given results on various benchmarks, how to synthesize a unified ranking that accurately reflects a
model’s general utility and robustness?
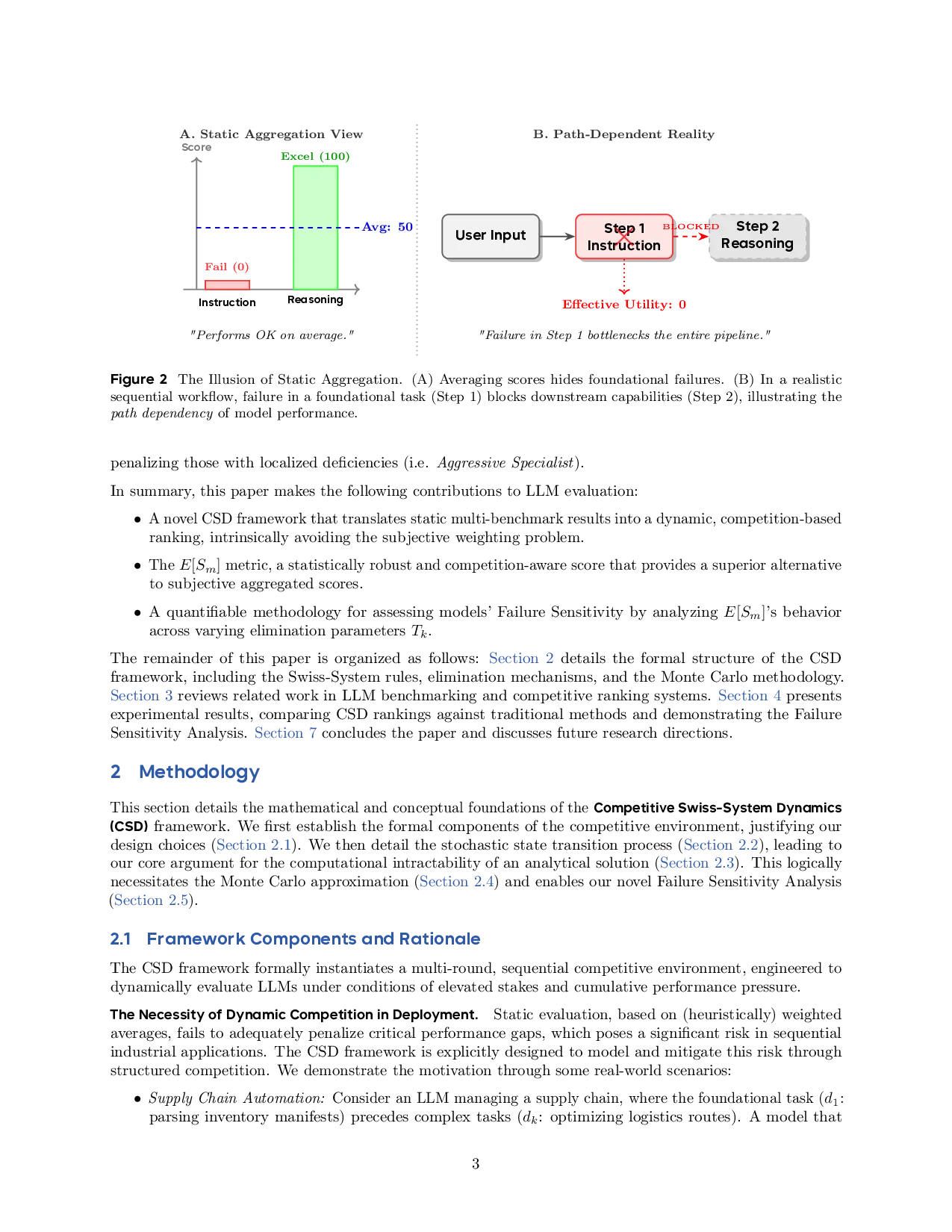
Current evaluation paradigms primarily rely on static aggregation, a method fundamentally challenged by the
lack of an objective ground truth for task importance. We refer to this as the problem of arbitrary weighting:
when combining results from disparate benchmarks (e.g., math, coding, and safety), researchers must assign
weights based on heuristics rather than data. Consequently, the final ranking becomes highly sensitive to
these manual choices. Furthermore, existing methods—whether based on simple averaging or static pairwise
models like Elo [5]—fail to capture the path-dependent nature of real-world model utility. In a static average,
a failure in a foundational capability can be mathematically compensated by excellence in an advanced task.
However, in practical deployment, capabilities are often sequential and interdependent. Consider a typical
agentic workflow illu
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.