📝 Original Info
- Title: One Tool Is Enough: Reinforcement Learning for Repository-Level LLM Agents
- ArXiv ID: 2512.20957
- Date: 2025-12-24
- Authors: Researchers from original ArXiv paper
📝 Abstract
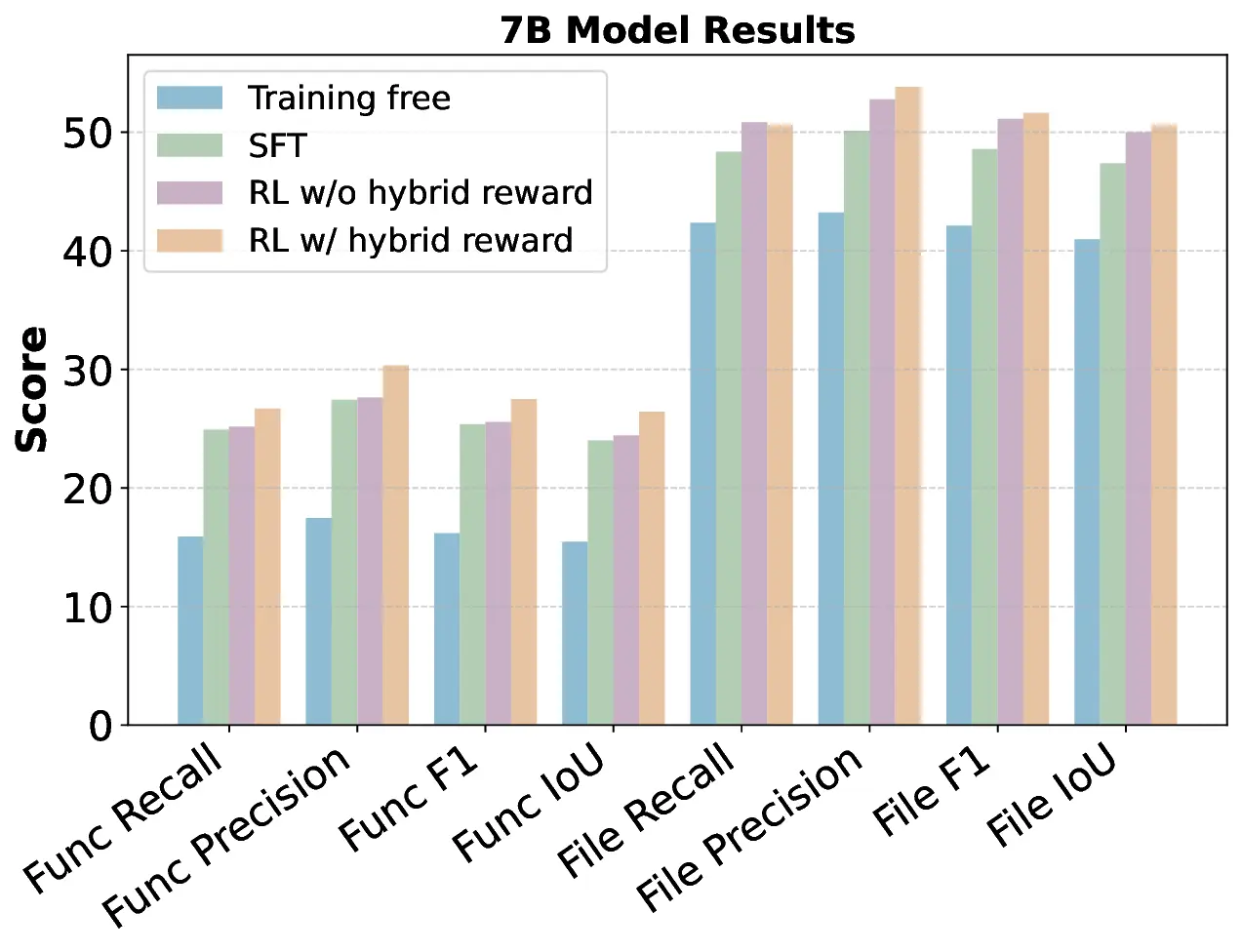
Locating files and functions requiring modification in large software repositories is challenging due to their scale and structural complexity. Existing LLM-based methods typically treat this as a repository-level retrieval task and rely on multiple auxiliary tools, which often overlook code execution logic and complicate model control. We propose RepoNavigator, an LLM agent equipped with a single execution-aware tool: jumping to the definition of an invoked symbol. This unified design reflects the actual flow of code execution while simplifying tool manipulation. RepoNavigator is trained end-to-end via Reinforcement Learning (RL) directly from a base pretrained model, without relying on closed-source distillation. Experiments demonstrate that RL-trained RepoNavigator achieves state-of-the-art performance, with the 7B model outperforming 14B baselines, the 14B model surpassing 32B competitors, and the 32B model exceeding closed-source models such as GPT-5 on most metrics. These results confirm that integrating a single, structurally grounded tool with RL training provides an efficient and scalable solution for repository-level issue localization.
💡 Deep Analysis
Deep Dive into One Tool Is Enough: Reinforcement Learning for Repository-Level LLM Agents.
Locating files and functions requiring modification in large software repositories is challenging due to their scale and structural complexity. Existing LLM-based methods typically treat this as a repository-level retrieval task and rely on multiple auxiliary tools, which often overlook code execution logic and complicate model control. We propose RepoNavigator, an LLM agent equipped with a single execution-aware tool: jumping to the definition of an invoked symbol. This unified design reflects the actual flow of code execution while simplifying tool manipulation. RepoNavigator is trained end-to-end via Reinforcement Learning (RL) directly from a base pretrained model, without relying on closed-source distillation. Experiments demonstrate that RL-trained RepoNavigator achieves state-of-the-art performance, with the 7B model outperforming 14B baselines, the 14B model surpassing 32B competitors, and the 32B model exceeding closed-source models such as GPT-5 on most metrics. These results
📄 Full Content
One Tool Is Enough: Reinforcement Learning of LLM Agents for
Repository-Level Code Navigation
Zhaoxi Zhang 1 Yitong Duan 2 Yanzhi Zhang 2 Yiming Xu 1 Zhixiang Wang 1 Kun Liang 1 Yang Li 3
Jiahui Liang 3 Deguo Xia 3 Jizhou Huang 3 Jiyan He 2 Yunfang Wu 1
Abstract
Locating files and functions requiring modifica-
tion in large software repositories is challenging
due to their scale and structural complexity. Exist-
ing LLM-based methods typically treat this as a
repository-level retrieval task and rely on multiple
auxiliary tools, which often overlook code exe-
cution logic and complicate model control. We
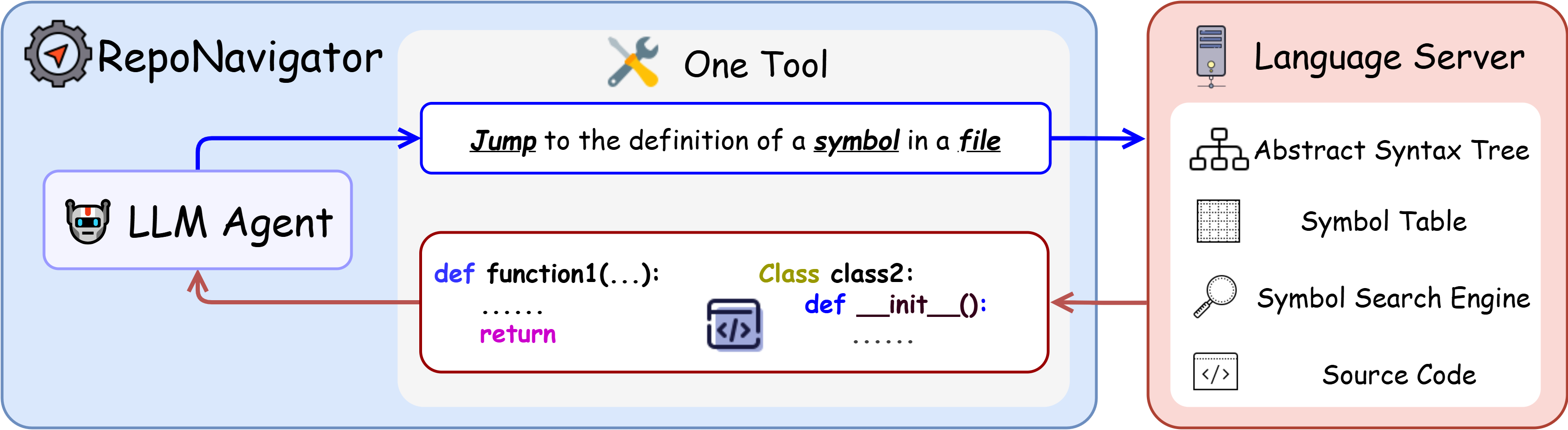
propose RepoNavigator, an LLM agent equipped
with a single execution-aware tool: jumping to
the definition of an invoked symbol. This unified
design reflects the actual flow of code execution
while simplifying tool manipulation. RepoNavi-
gator is trained end-to-end via Reinforcement
Learning (RL) directly from a base pretrained
model, without relying on closed-source distilla-
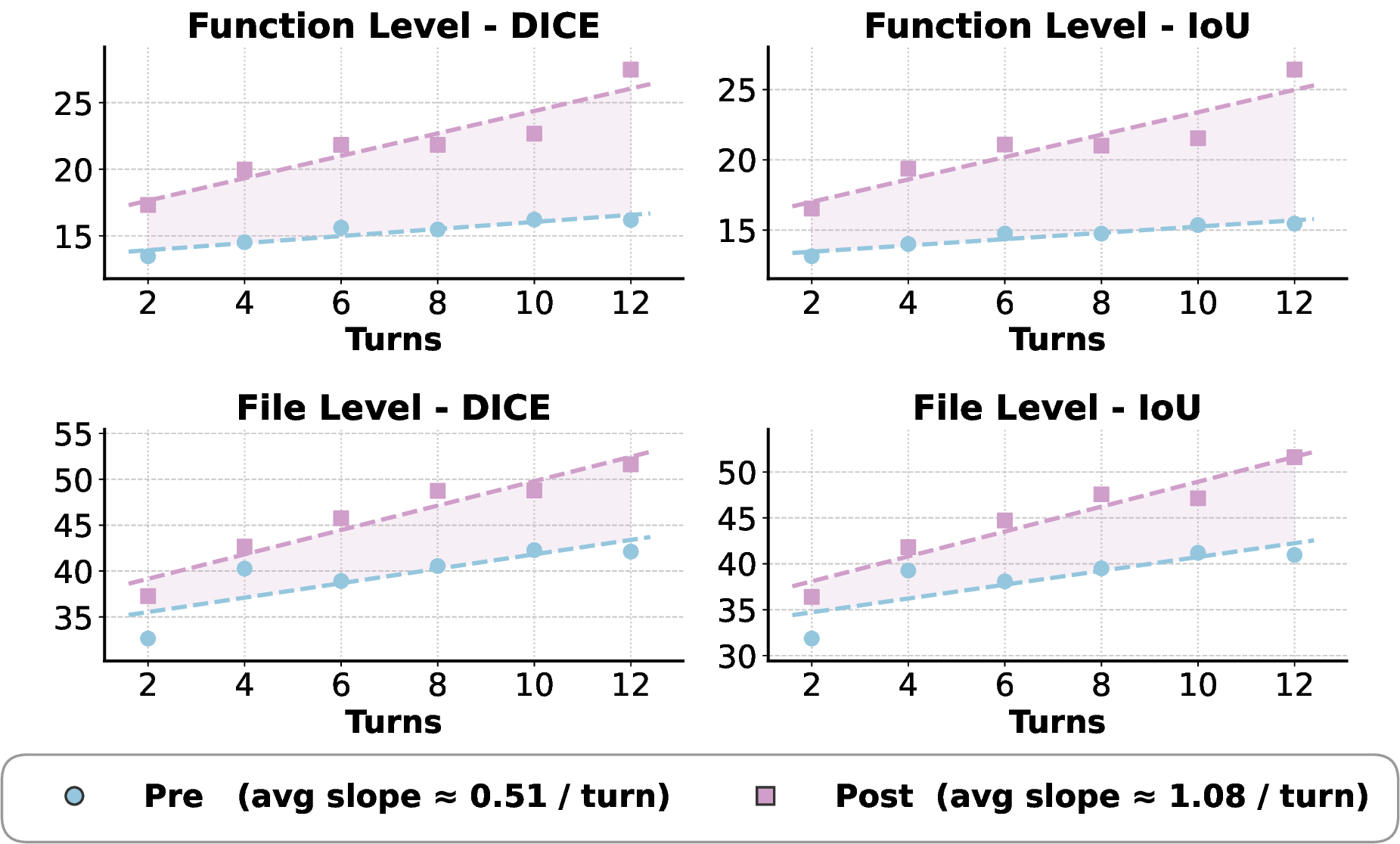
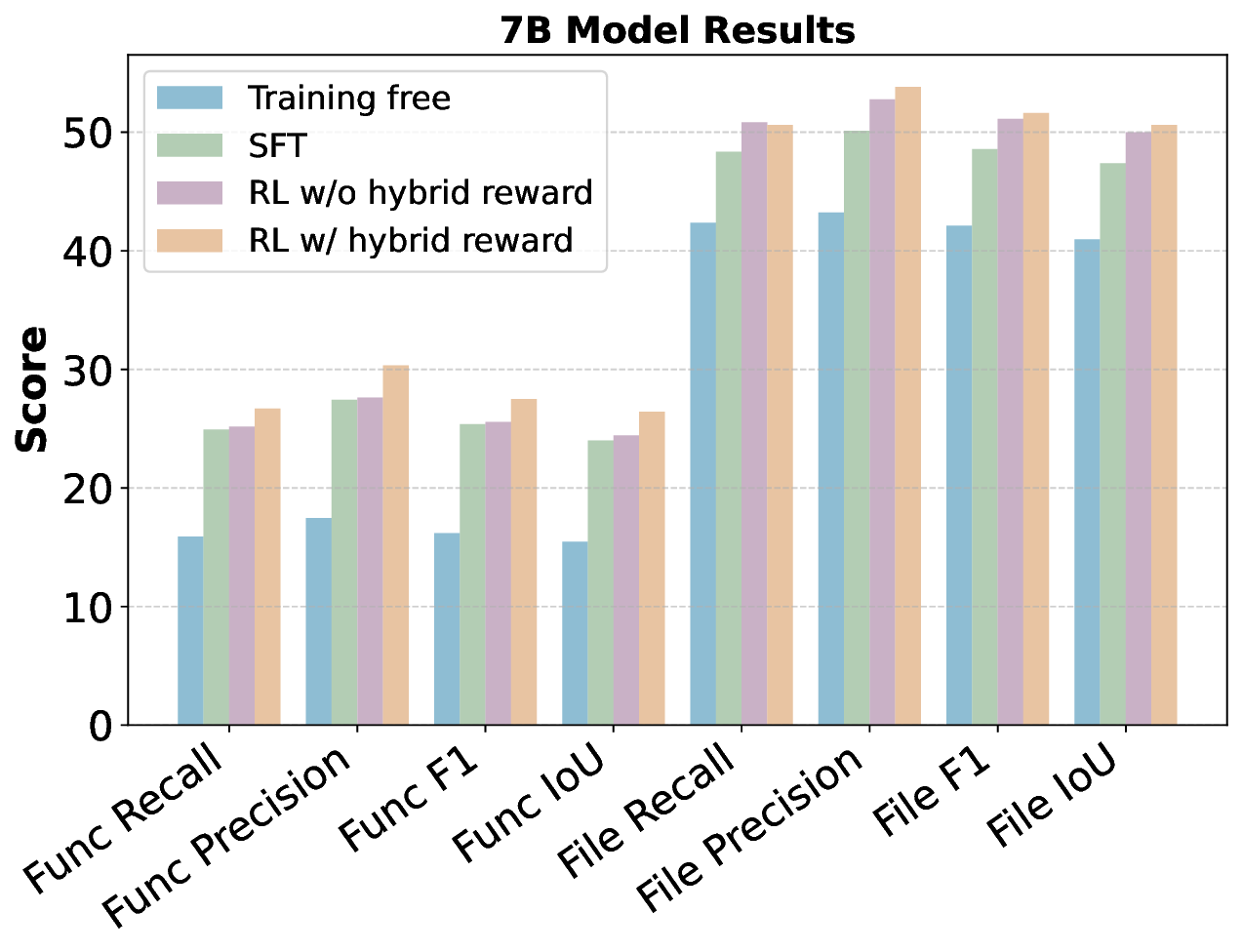
tion. Experiments demonstrate that RL-trained
RepoNavigator achieves state-of-the-art perfor-
mance, with the 7B model outperforming 14B
baselines, the 14B model surpassing 32B com-
petitors, and the 32B model exceeding closed-
source models such as GPT-5 on most metrics.
These results confirm that integrating a single,
structurally grounded tool with RL training
provides an efficient and scalable solution for
repository-level issue localization.
1. Introduction
With the rapid advancement of Large Language Models
(LLMs) (Liu et al., 2024a; Team, 2024; Yang et al., 2025a),
equipping LLMs with pre-built tools to form LLM agents
has become a common paradigm for expanding their capa-
bilities (Shen, 2024; Yuan et al., 2024; Lu et al., 2024). In
the domain of software engineering (SWE), although LLM
agents can effectively handle simple programming tasks
1School
of
Computer
Science,
Peking
University
2Zhongguancun Academy
3Baidu Inc.
Correspondence to:
Yitong Duan
, Yunfang Wu .
Figure 1: Illustration of a LLM navigating through a code
repository. The LLM is equipped with a single yet powerful
tool: jump, which is realized through a language server.
(Hui et al., 2024; Guo et al., 2024a), their ability to operate
on large-scale software repositories remains limited. SWE-
BENCH (Jimenez et al., 2023) currently serves as the most
comprehensive benchmark for evaluating whether LLMs
can resolve real-world GitHub issues. All pretrained LLMs
cannot process the whole repository directly due to context
limits (Yang et al., 2024b). While SWE-AGENT (Jimenez
et al., 2023) provides moderate gains, it remains far from
enabling robust repository-level reasoning.
Most existing agents rely on test-time scaling applied di-
rectly to pretrained LLMs (Liu et al., 2023; Chen et al.,
2025; Schmidgall et al., 2025). In SWE tasks, tools are
essential rather than optional: real-world repositories are far
larger than the context window of current LLMs, making it
impossible to process an entire codebase in a single forward
pass. Agents must therefore iteratively invoke tools to re-
trieve partial information from the repository and interleave
natural-language reasoning with tool calls.
Mainstream LLM agents (Chen et al., 2025; Liu et al., 2025;
Xiang et al., 2025; Wang et al., 2023; Chen et al., 2024) are
rarely exposed to such agentic interaction patterns during
pretraining and typically acquire tool usage only through
few-shot prompting which is insufficient for learning com-
plex multi-step tool-chaining behaviors. Moreover, because
tool definition spaces are effectively unbounded, pretrained
models cannot fully internalize their semantics without post-
training. To mitigate these issues, post-training paradigms
such as Supervised Finetuning (SFT) (Ma et al., 2025) and
Reinforcement Learning with Verifiable Rewards (RLVR)
(Yu et al., 2025a; Yue et al., 2025) have been applied, with
promising results in domains including retrieval agents (Jin
1
arXiv:2512.20957v5 [cs.SE] 24 Jan 2026
One Tool Is Enough: Reinforcement Learning of LLM Agents for Repository-Level Code Navigation
et al., 2025a), GUI agents (Hong et al., 2024), and math
agents (Yan et al., 2025).
Directly training an agent to fix software issues, however,
remains difficult. A single bug often admits multiple valid
patches, making string-level evaluation unreliable. The
only precise evaluation method requires executing candi-
date patches inside a dedicated Docker environment for each
repository (Luo et al., 2025), which is prohibitively expen-
sive CPU resource for supervised training. To make training
more tractable, we adopt a simplified yet widely general-
izable assignment: issue localization. Prior work shows
that a software issue becomes substantially easier to resolve
once the relevant functions and files are correctly identified
(Chen et al., 2025; Ma et al., 2025; Xia et al., 2024; Jiang
et al., 2025). Since modern software repositories contain
a signif…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.