In recent years, the development of multimodal autoencoders has gained significant attention due to their potential to handle multimodal complex data types and improve model performance. Understanding the stability and robustness of these models is crucial for optimizing their training, architecture, and real-world applicability. This paper presents an analysis of Lipschitz properties in multimodal autoencoders, combining both theoretical insights and empirical validation to enhance the training stability of these models. We begin by deriving the theoretical Lipschitz constants for aggregation methods within the multimodal autoencoder framework. We then introduce a regularized attention-based fusion method, developed based on our theoretical analysis, which demonstrates improved stability and performance during training. Through a series of experiments, we empirically validate our theoretical findings by estimating the Lipschitz constants across multiple trials and fusion strategies. Our results demonstrate that our proposed fusion function not only aligns with theoretical predictions but also outperforms existing strategies in terms of consistency, convergence speed, and accuracy. This work provides a solid theoretical foundation for understanding fusion in multimodal autoencoders and contributes a solution for enhancing their performance.
Deep Dive into 멀티모달 오토인코더의 리프시츠 특성 분석과 주의 기반 융합 안정화 기법.
In recent years, the development of multimodal autoencoders has gained significant attention due to their potential to handle multimodal complex data types and improve model performance. Understanding the stability and robustness of these models is crucial for optimizing their training, architecture, and real-world applicability. This paper presents an analysis of Lipschitz properties in multimodal autoencoders, combining both theoretical insights and empirical validation to enhance the training stability of these models. We begin by deriving the theoretical Lipschitz constants for aggregation methods within the multimodal autoencoder framework. We then introduce a regularized attention-based fusion method, developed based on our theoretical analysis, which demonstrates improved stability and performance during training. Through a series of experiments, we empirically validate our theoretical findings by estimating the Lipschitz constants across multiple trials and fusion strategies. O
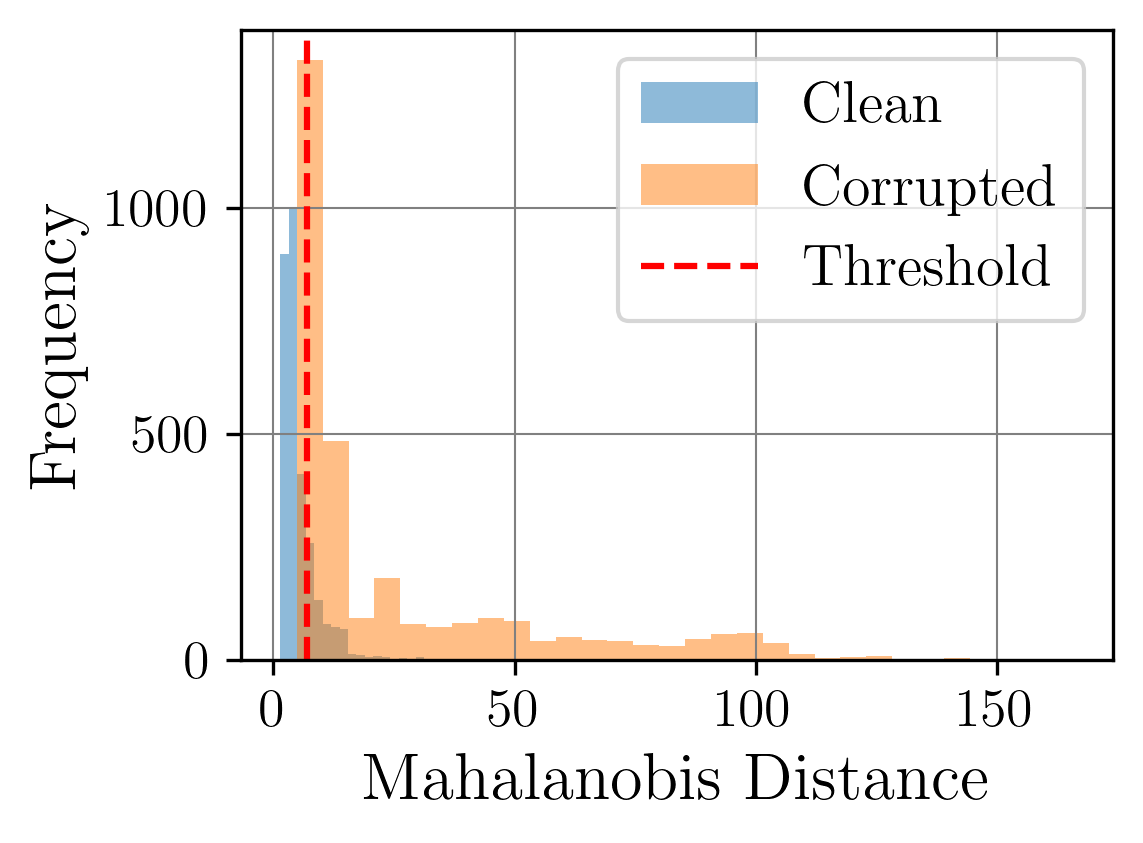
In industrial applications, trust and accuracy are paramount since even minor inaccuracies in high-volume production can lead to significant financial losses. In sectors like automotive, aerospace, and pharmaceuticals, for instance, the tolerance for error is minimal, as the cost of production defects or non-conforming products can lead to costly recalls, compliance issues, or even safety risks [1]. Hence, ensuring production quality requires rigorous quality control and precise testing methods with high standards of accuracy and stability [2].
To meet these high standards of accuracy and stability, there is an increasing reliance on machine-learning models capable of processing large volumes of data from various stages of production and environmental factors. These models facilitate real-time anomaly detection, predictive analytics, and automated decision-making in manufacturing processes, enabling faster responses to potential quality issues [3]. However, achieving such precision with machine learning requires overcoming several challenges. These include training the models on accurate, representative datasets to avoid bias and implementing robust systems [4]. Moreover, these machine-learning models must be deployed in environments that are often dynamic and noisy, where variations in temperature, humidity, and equipment wear can impact production consistency.
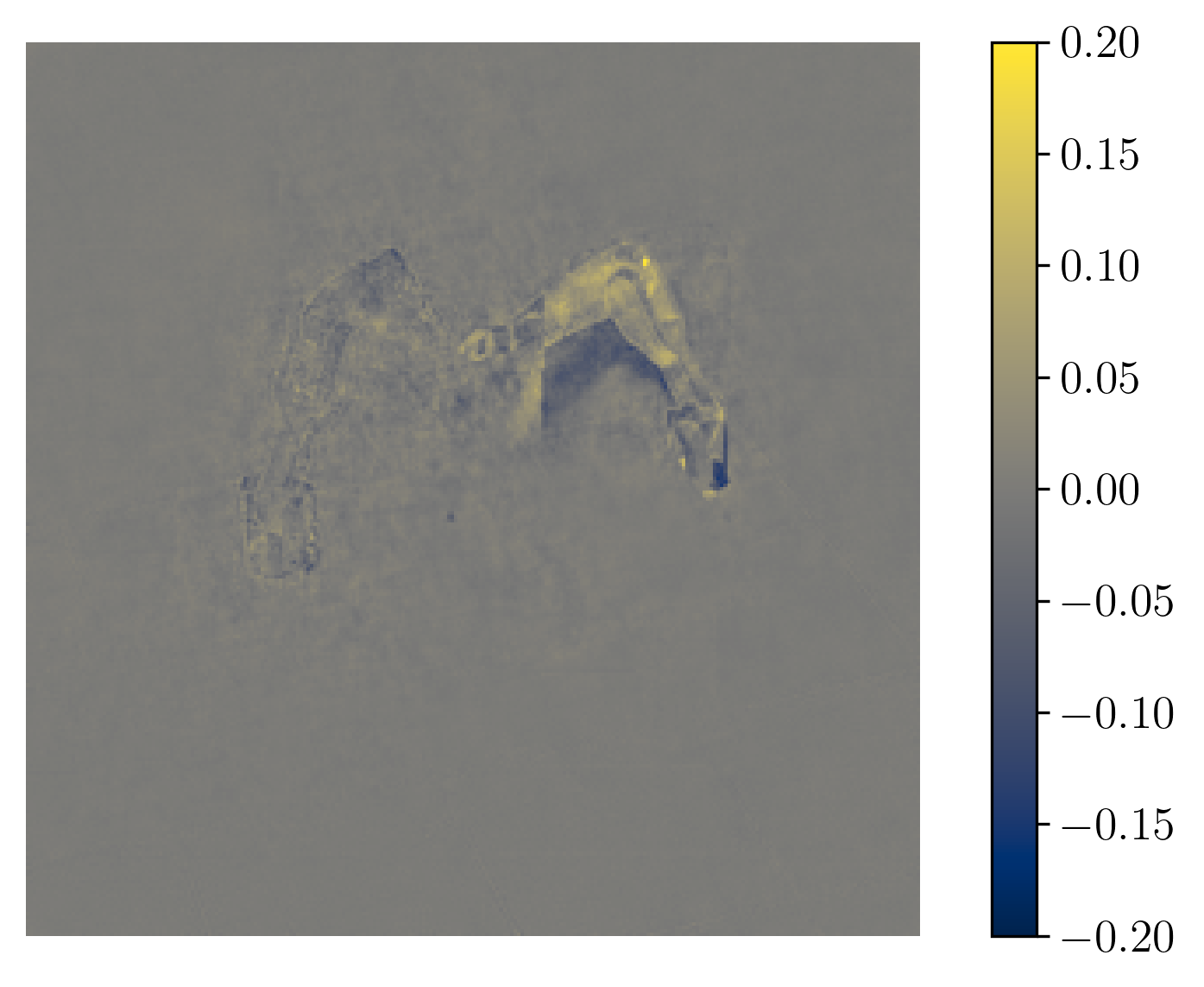
A promising approach to improve the cost-effectiveness and accuracy of machine learning in industrial settings is the use of multimodal data. Multimodal models integrate data from various sources, such as camera and time-series data, to capture complementary and marginal information that enables a more comprehensive view of the production environment. This combination of diverse data inputs allows the model to detect patterns and anomalies that might be missed when relying on a single data source. This diversity strengthens the model’s ability to make accurate arXiv:2512.20749v1 [cs.LG] 23 Dec 2025 Preprint predictions and adapt to varying conditions on the production floor, reducing the risk of errors and enhancing overall system reliability. Consequently, multimodal approaches are particularly beneficial in complex industrial processes where the integration of multiple data sources leads to improved fault detection, predictive maintenance, or quality control capabilities [5].
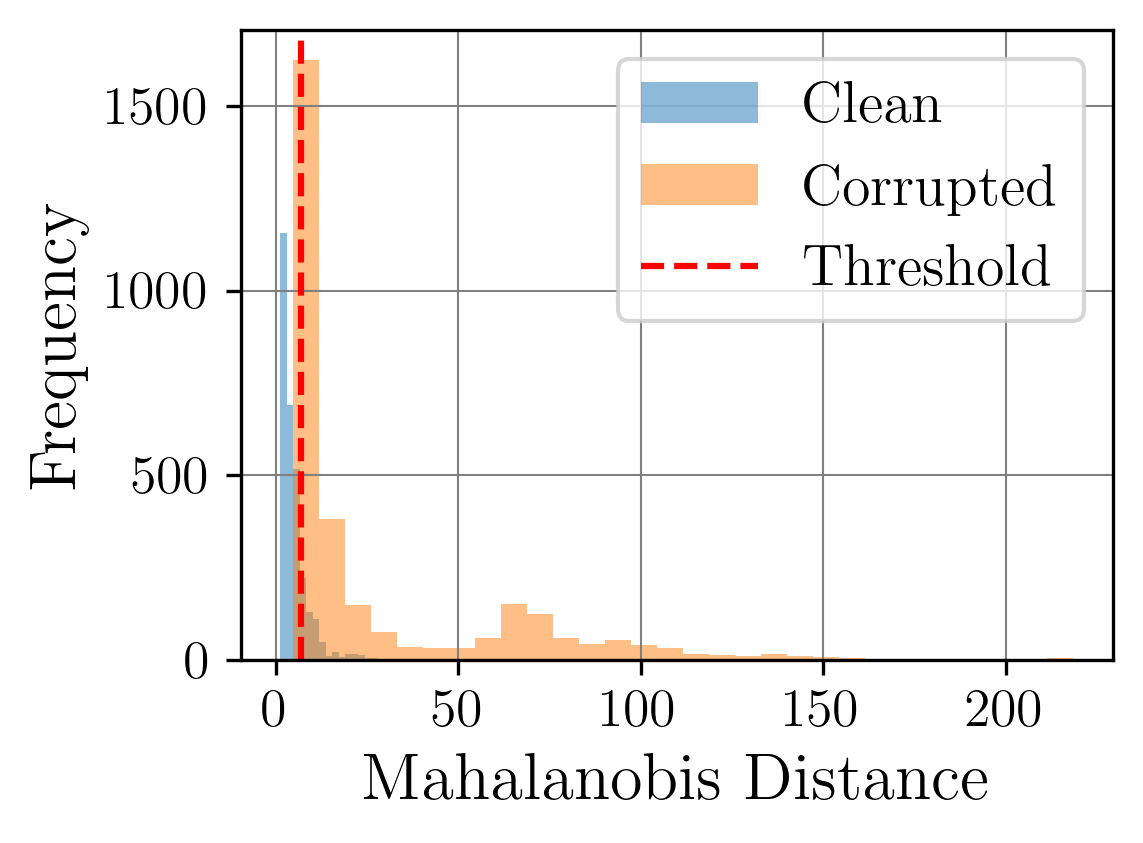
While researchers are increasingly utilizing multimodal data in machine learning, the datasets they often label as multimodal typically originate from sensors with similar data formats and structures. In real-world applications, however, data sources are far more diverse and require complex heterogeneous data integration techniques. This diversity introduces a need for specialized methods to combine information from varied sensors, each with distinct data types and structures. As a result, datasets featuring heterogeneous data must undergo feature extraction and preprocessing to ensure effective analysis and compatibility. This step is crucial for transforming raw, varied data into formats that models can interpret accurately, thereby enhancing robustness in real-world applications [6].
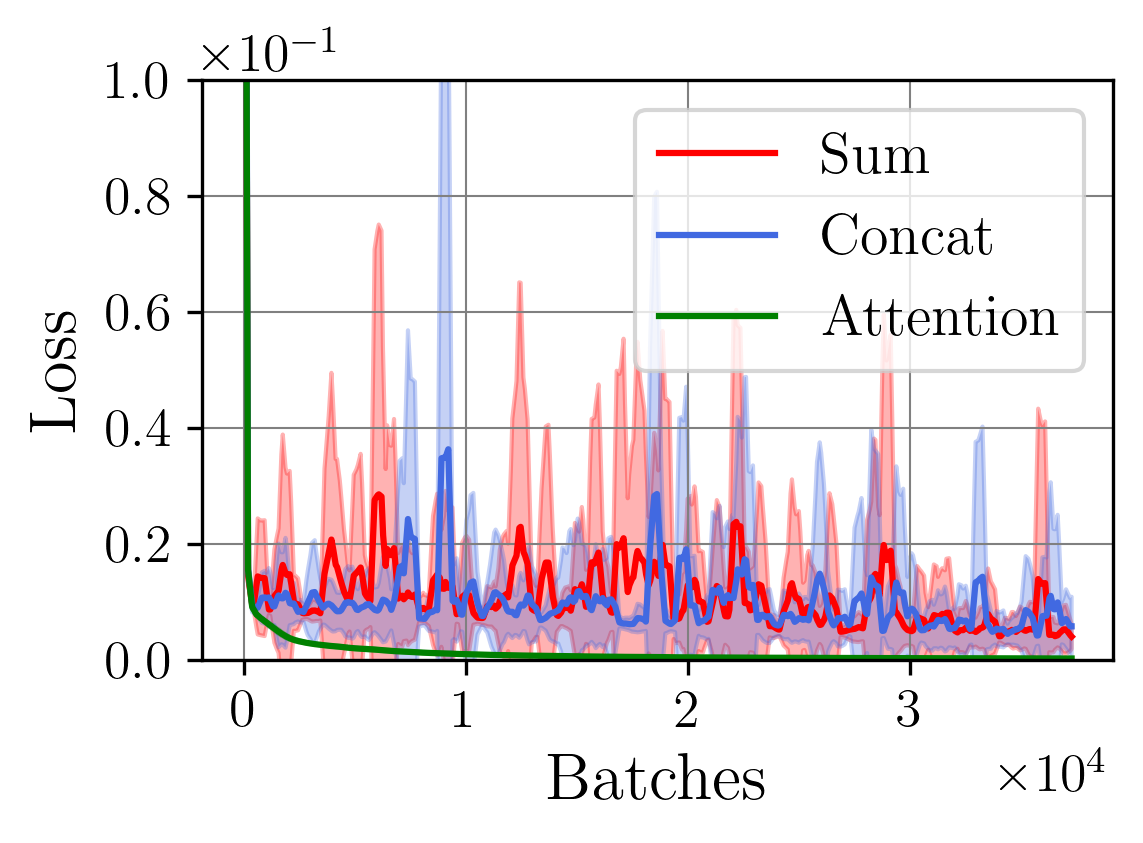
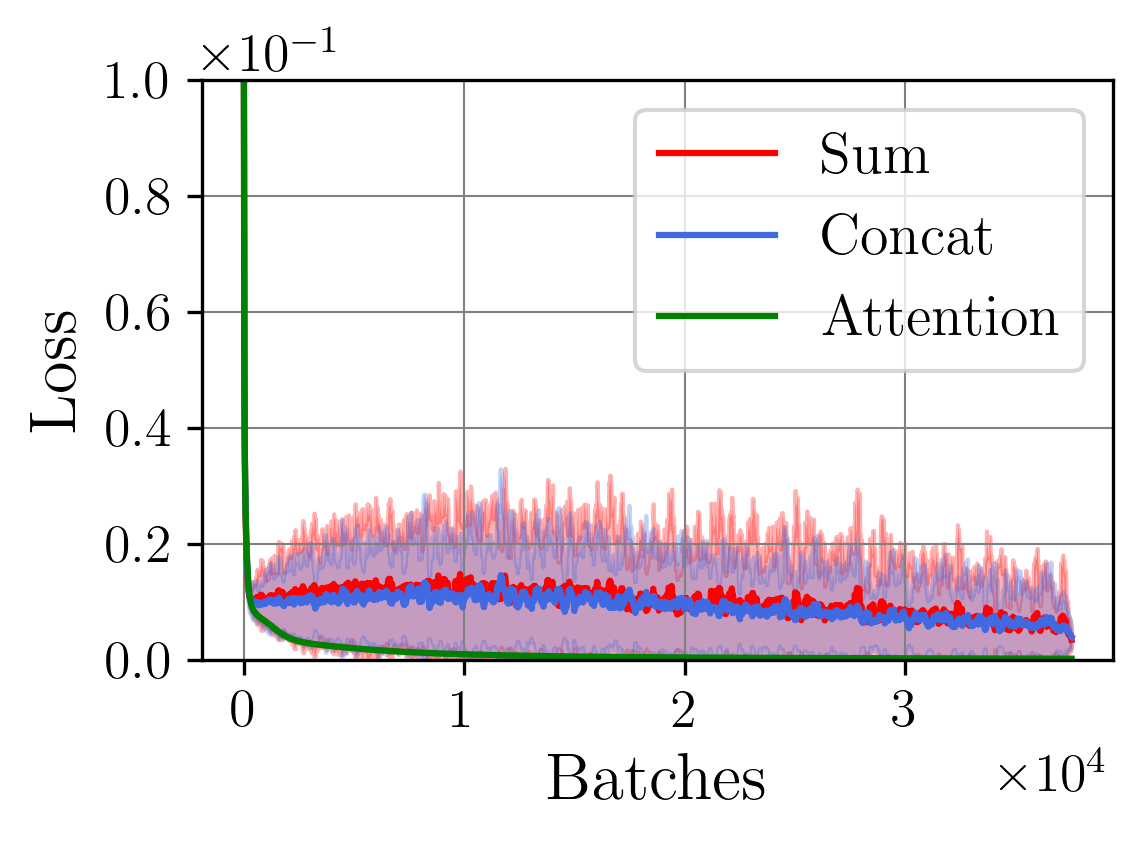
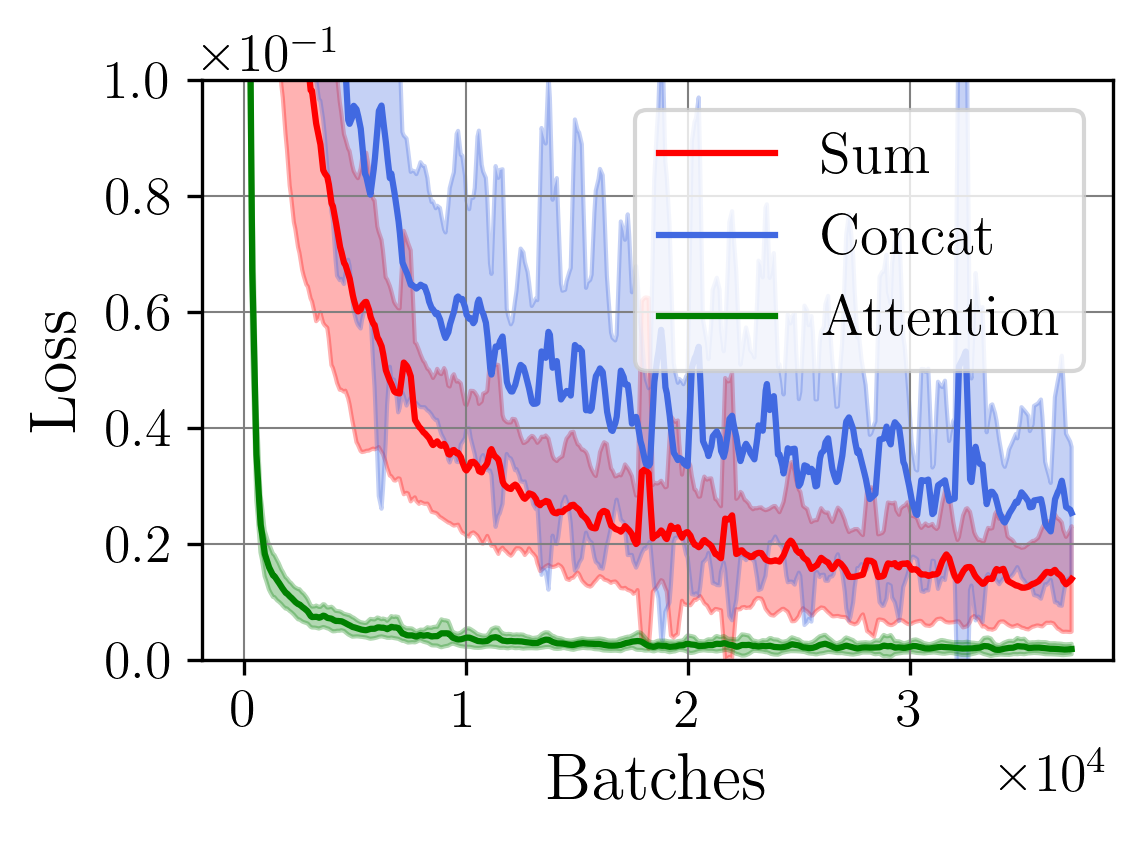
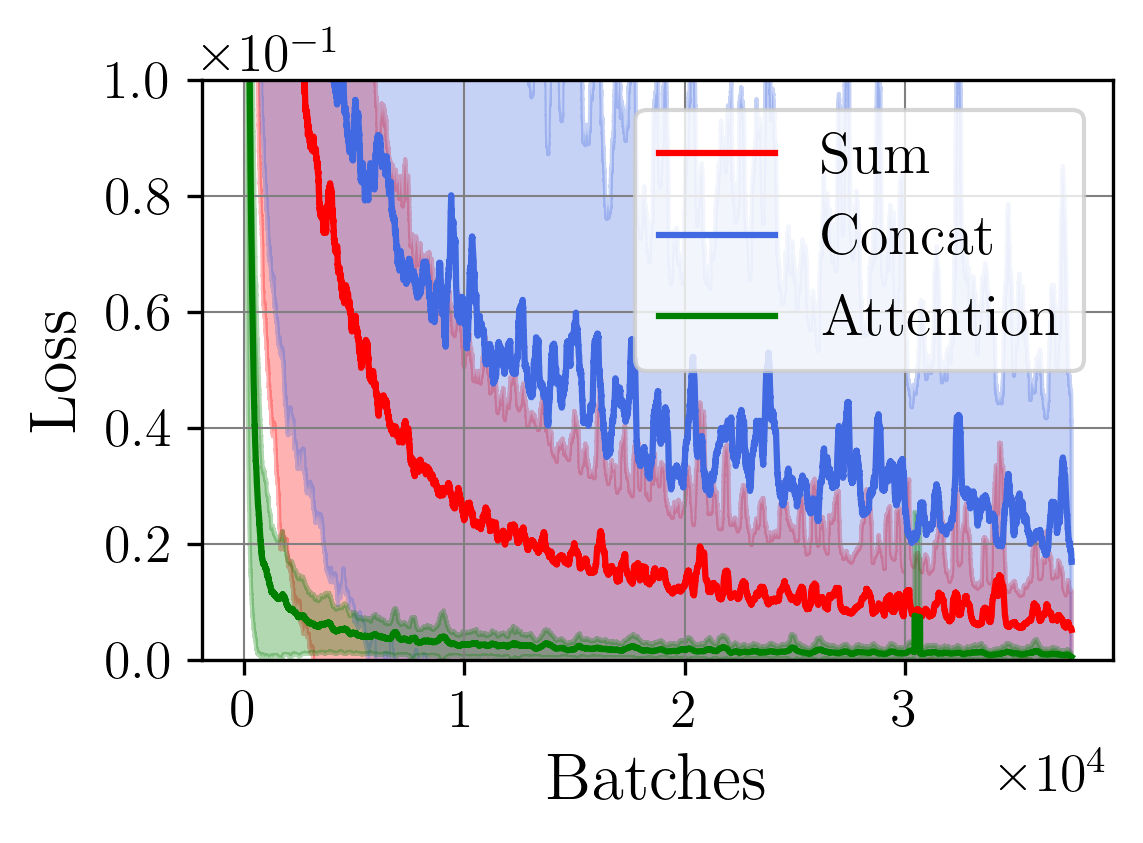
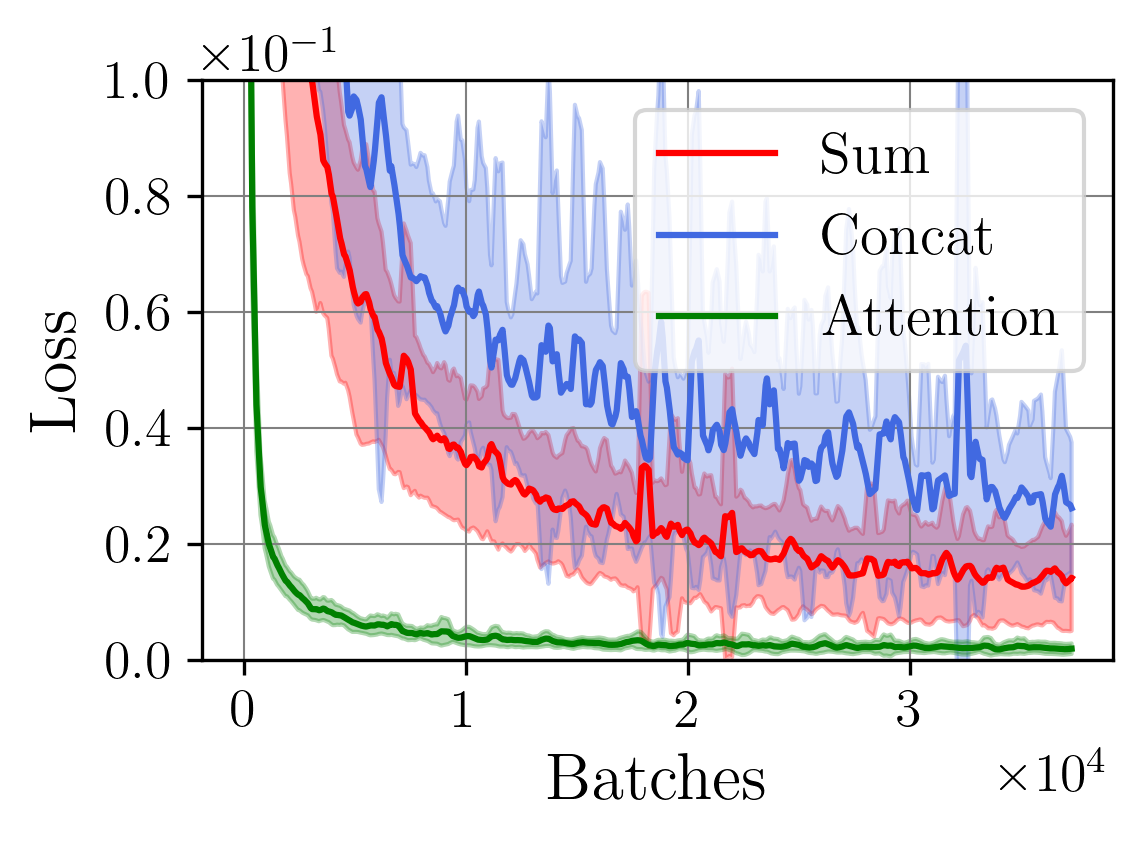
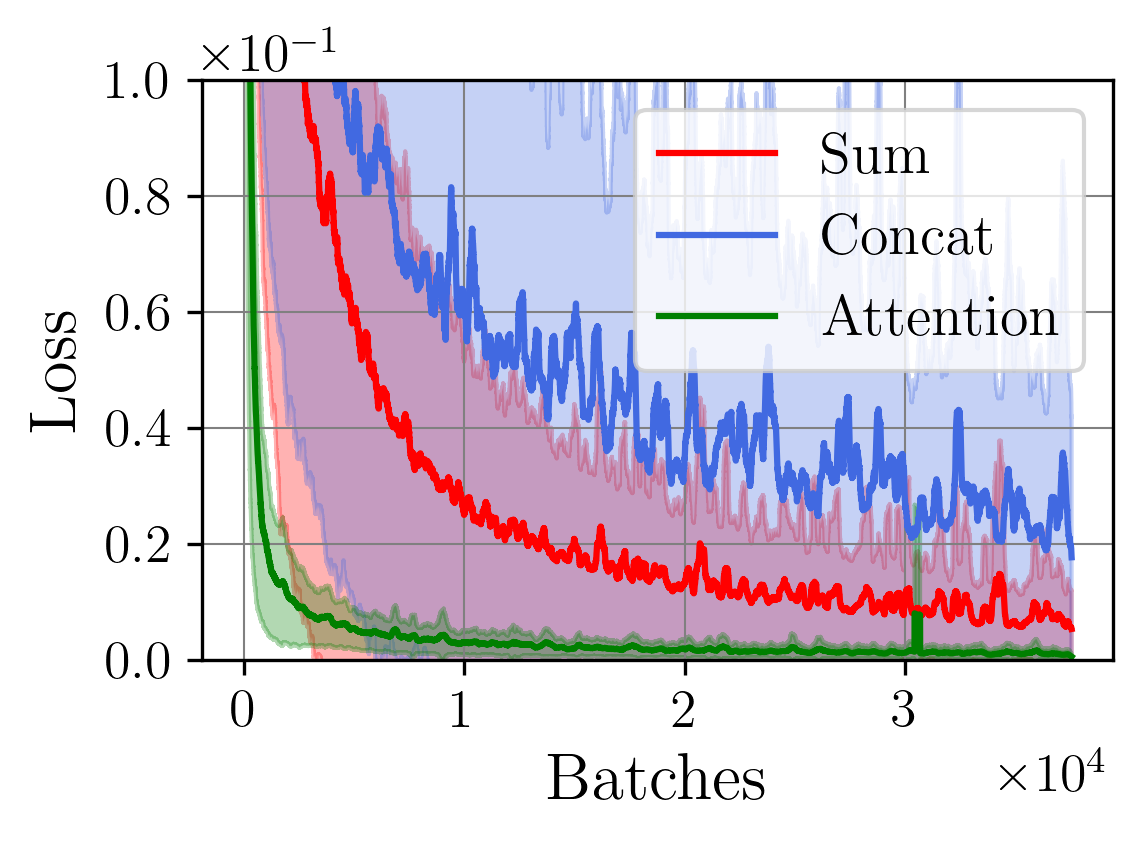
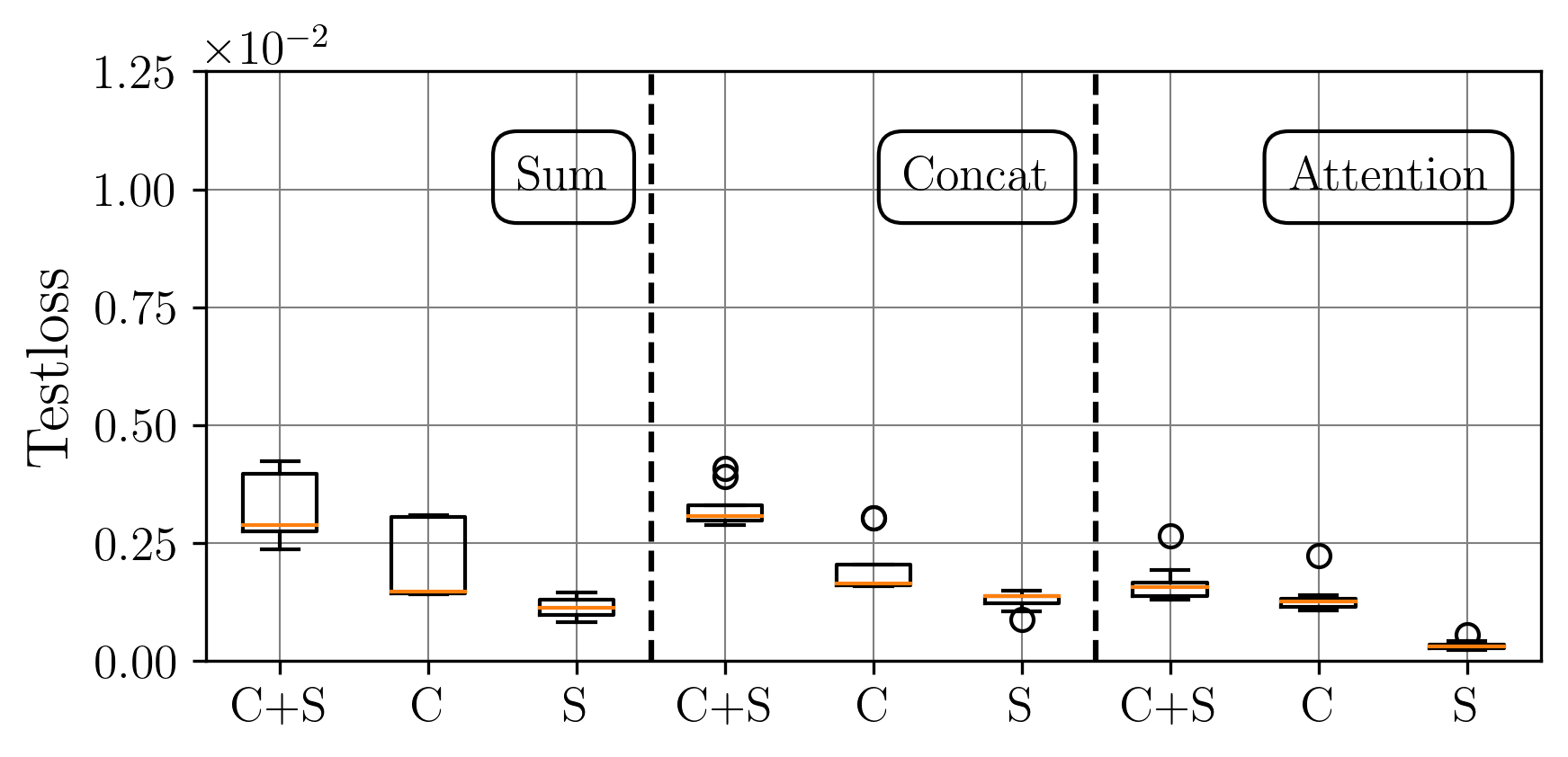
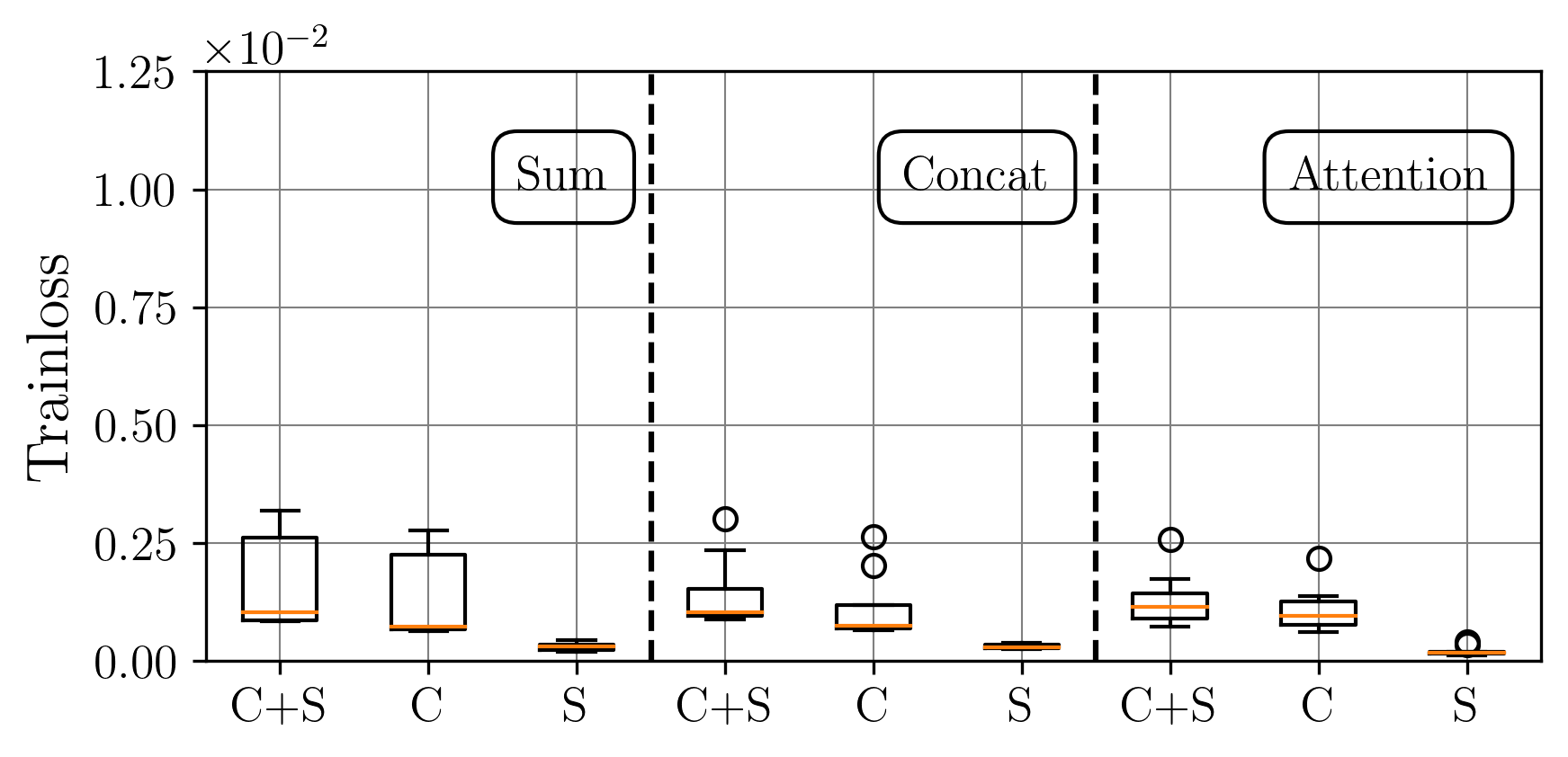
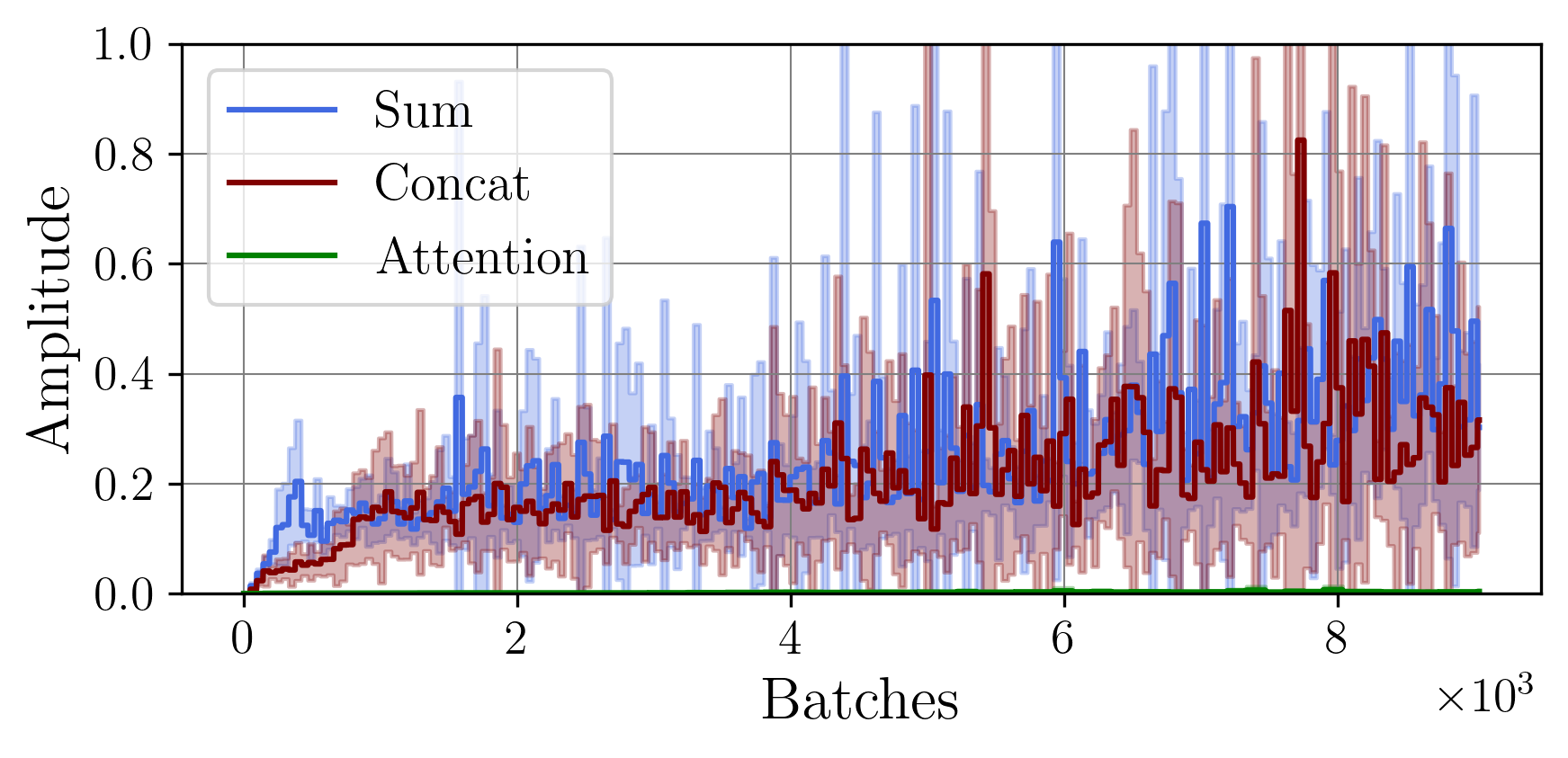
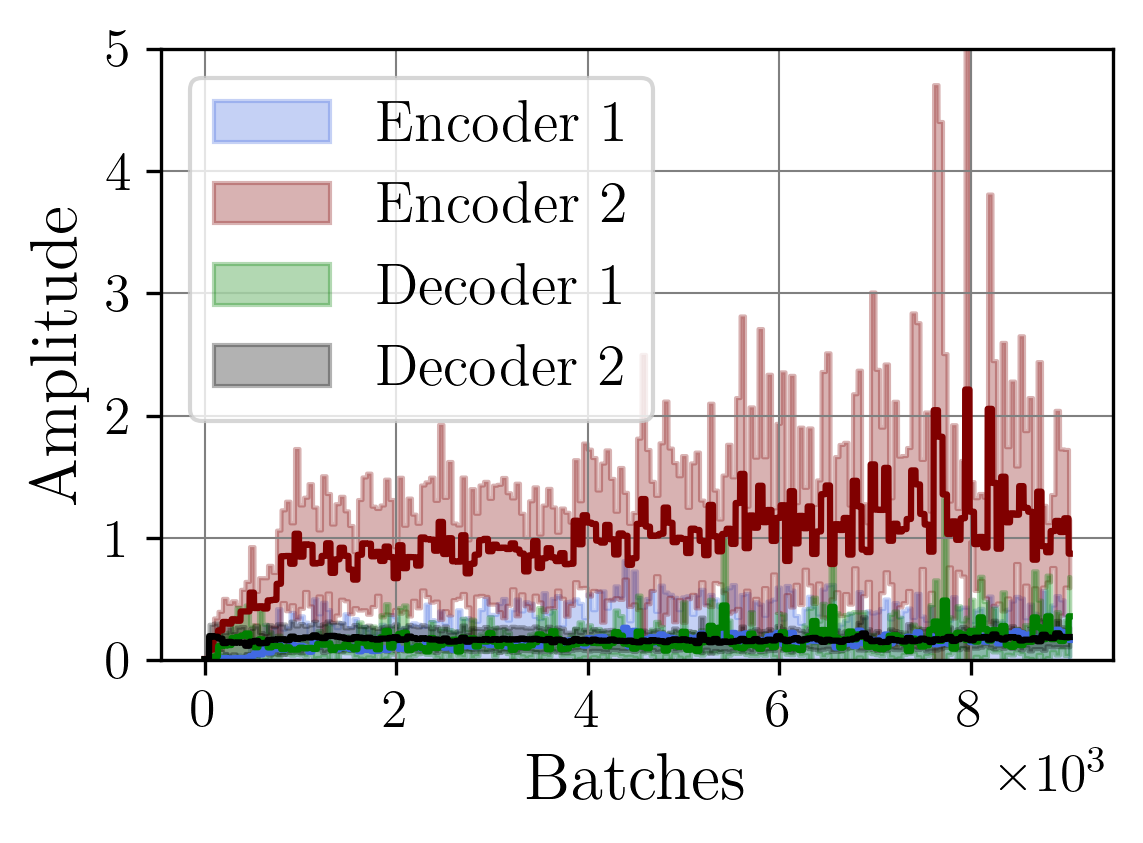
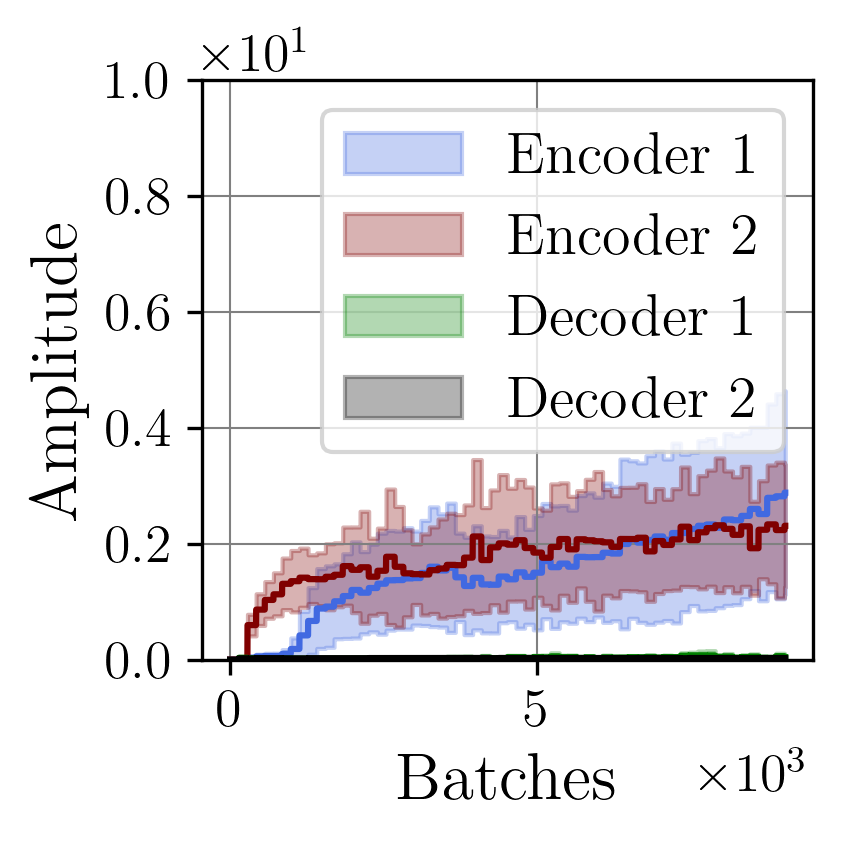
A central challenge arises in the effective fusion of different modalities. Many researchers employ straightforward concatenation to retain information from both data sources and to prevent the loss of critical details [7,8], while others sum data values for a more simplified fusion approach [9]. Some researchers have proposed advanced fusion strategies, leveraging neural-based approaches to capture inter-modal dependencies dynamically [10]. Despite the growing use of multimodal data fusion in industrial machine learning, no study has yet performed a detailed mathematical analysis of fusion methods to understand the behavior and properties of fused latent representations in these applications. In this paper, we aim to bridge this gap by conducting a rigorous mathematical investigation of the Lipschitz properties of fusion methods for multimodal machine learning. Our approach leverages a multimodal autoencoder-based model for feature extraction, which allows us to systematically analyze and evaluate how different fusion strategies affect latent space representations. Additionally, we propose a novel regularized attention-based fusion mechanism that maintains the desired Lipschitz properties. We empirically underline our theoretical results on three multimodal industrial datasets of varying complexity, designed to simulate real-world production conditions with diverse data types. These datasets provide insights into the stability, accuracy, and robustness of each fusion method in different scenarios. Our contributions can be summarized as follows:
(i) We investigate the gradient dynamics of the multimodal autoencoder architecture, emphasizing the Lipschitz constant across fusion setups implemented through concatenation and summation techniques while exploring their broader implications.
(i
…(Full text truncated)…
This content is AI-processed based on ArXiv data.