Large language models (LLMs) rely on self-attention for contextual understanding, demanding high-throughput inference and large-scale token parallelism (LTPP). Existing dynamic sparsity accelerators falter under LTPP scenarios due to stage-isolated optimizations. Revisiting the end-to-end sparsity acceleration flow, we identify an overlooked opportunity: cross-stage coordination can substantially reduce redundant computation and memory access. We propose STAR, a cross-stage compute- and memory-efficient algorithm-hardware co-design tailored for Transformer inference under LTPP. STAR introduces a leading-zero-based sparsity prediction using log-domain add-only operations to minimize prediction overhead. It further employs distributed sorting and a sorted updating FlashAttention mechanism, guided by a coordinated tiling strategy that enables fine-grained stage interaction for improved memory efficiency and latency. These optimizations are supported by a dedicated STAR accelerator architecture, achieving up to 9.2$\times$ speedup and 71.2$\times$ energy efficiency over A100, and surpassing SOTA accelerators by up to 16.1$\times$ energy and 27.1$\times$ area efficiency gains. Further, we deploy STAR onto a multi-core spatial architecture, optimizing dataflow and execution orchestration for ultra-long sequence processing. Architectural evaluation shows that, compared to the baseline design, Spatial-STAR achieves a 20.1$\times$ throughput improvement.
Deep Dive into Designing Spatial Architectures for Sparse Attention: STAR Accelerator via Cross-Stage Tiling.
Large language models (LLMs) rely on self-attention for contextual understanding, demanding high-throughput inference and large-scale token parallelism (LTPP). Existing dynamic sparsity accelerators falter under LTPP scenarios due to stage-isolated optimizations. Revisiting the end-to-end sparsity acceleration flow, we identify an overlooked opportunity: cross-stage coordination can substantially reduce redundant computation and memory access. We propose STAR, a cross-stage compute- and memory-efficient algorithm-hardware co-design tailored for Transformer inference under LTPP. STAR introduces a leading-zero-based sparsity prediction using log-domain add-only operations to minimize prediction overhead. It further employs distributed sorting and a sorted updating FlashAttention mechanism, guided by a coordinated tiling strategy that enables fine-grained stage interaction for improved memory efficiency and latency. These optimizations are supported by a dedicated STAR accelerator archite
1
Designing Spatial Architectures for Sparse
Attention: STAR Accelerator via Cross-Stage Tiling
Huizheng Wang, Taiquan Wei, Hongbin Wang, Zichuan Wang, Xinru Tang, Zhiheng Yue, Student Member, IEEE,
Shaojun Wei, Fellow, IEEE, Yang Hu, Senior Member, IEEE, Shouyi Yin, Fellow, IEEE
Abstract—Large language models (LLMs) rely on self-attention
for contextual understanding, demanding high-throughput in-
ference and large-scale token parallelism (LTPP). Existing dy-
namic sparsity accelerators falter under LTPP scenarios due to
stage-isolated optimizations. Revisiting the end-to-end sparsity
acceleration flow, we identify an overlooked opportunity: cross-
stage coordination can substantially reduce redundant compu-
tation and memory access. We propose STAR, a cross-stage
compute- and memory-efficient algorithm–hardware co-design
tailored for Transformer inference under LTPP. STAR introduces
a leading-zero-based sparsity prediction using log-domain add-
only operations to minimize prediction overhead. It further
employs distributed sorting and a sorted updating FlashAttention
mechanism, guided by a coordinated tiling strategy that enables
fine-grained stage interaction for improved memory efficiency
and latency. These optimizations are supported by a dedicated
STAR accelerator architecture, achieving up to 9.2× speedup
and 71.2× energy efficiency over A100, and surpassing SOTA
accelerators by up to 16.1× energy and 27.1× area efficiency
gains. Further, we deploy STAR onto a multi-core spatial ar-
chitecture, optimizing dataflow and execution orchestration for
ultra-long sequence processing. Architectural evaluation shows
that, compared to the baseline design, Spatial-STAR achieves a
20.1× throughput improvement.
Index Terms—Transformer, attention sparsity, FlashAttention,
top-k, tiling, distributed attention, spatial architecture.
I. INTRODUCTION
E
MPOWERED by self-attention, large language models
(LLMs) have revolutionized fields such as chatbots [1]
and code generation [2]. The self-attention processes three
matrices: Q (query), K (key) and V (value). First, the at-
tention matrix A∈RS×S is computed by Q×KT , where S
denotes the sequence length. The resulting matrix A is then
passed through a softmax function for normalization before
being multiplied by V to generate the final output.
This work was supported in part by the National Science and Technology
Major Project under Grant 2022ZD0115200; in part by the NSFC under Grant
62125403, Grant U24A20234, Grant 92464302 and Grant U24B20164; in part
by the Beijing S&T Project Z251100008425010; in part by Shanghai Munici-
pal Science and Technology Major Project; the Natural Science Foundation of
Jiangsu Province Basic Research Program under Grant BK20243042; in part
by the Beijing National Research Center for Information Science and Tech-
nology; in part by the Northern IC Technology Innovation Center (Beijing)
Co., Ltd under Grant QYJS20232801B; and in part by the Beijing Advanced
Innovation Center for Integrated Circuits. An earlier version of this paper was
presented at the IEEE 57th Annual IEEE/ACM International Symposium on
Microarchitecture (MICRO), 2024 [DOI: 10.1109/MICRO61859.2024.00093].
(Corresponding author: Yang Hu, email: hu yang@tsinghua.edu.cn).
Huizheng Wang, Taiquan Wei, Hongbin Wang, Zichuan Wang, Xinru Tang,
Zhiheng Yue, Shaojun Wei, and Yang Hu are with the School of Integrated
Circuits, Tsinghua University, Beijing, 100084, China.
Shouyi Yin is with the School of Integrated Circuits, Tsinghua University,
Beijing, 100084, China, and Shanghai AI Lab, Shanghai, 200232, China.
Sequence length
increases
0
20
40
60
80
100
2048
4096
8192
16384
32768
65536
131072
262144
Normalized
Complexity (%)
Prompt Sequence Length
QKV
Atten
FFN
(b) Computation breakdown for Llama 13B
13x
BERT-B
BERT-L
GPT-2
Bloom-3B
Llama-13B
LLama4-Ma
verick
1
2
4
35
46
2198
(a) Normalized Memory Requirement for Attention
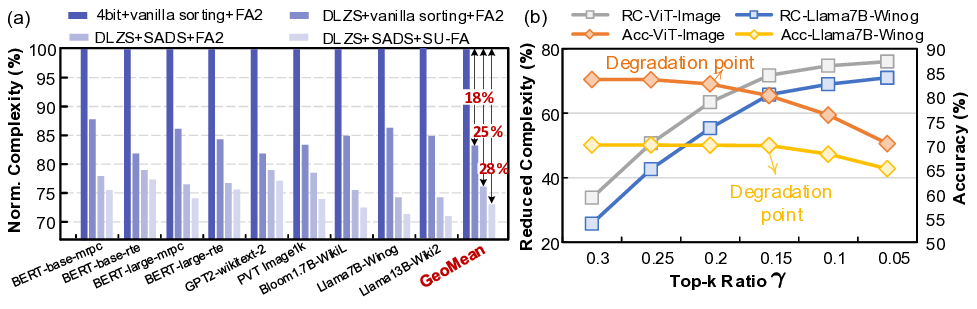
Fig. 1: (a) Normalized memory requirement for attention. (b)
Computation breakdown for the Llama 13B.
LLMs increasingly demand faster inference and higher
throughput, particularly for long-context tasks. However, un-
like the linear complexity of O(SH2) in the feed-forward net-
work (FFN), where H is the hidden dimension, the quadratic
complexity O(S2H) of self-attention severely hinders the
efficiency of LLMs on long sequences. From early models
such as BERT [3] to recent ones like LLaMA 4-Maverick [4],
the maximum sequence length has expanded over 32× (512
to 16k), whereas the hidden dimension H has increased only
10× (768 to 8k). This dramatic growth of sequence length
results in more than a 2000× increase in attention memory
footprint, as depicted in Fig.1 (a), creating significant barriers
to deploying LLMs across both cloud and edge environments.
Moreover,
the
quadratic
computation
of
self-attention
emerges as a critical bottleneck for fast inference. As shown
in Fig.1 (b), when the sequence length reaches 16k tokens,
attention surpasses the FFN as the mo
…(Full text truncated)…
This content is AI-processed based on ArXiv data.