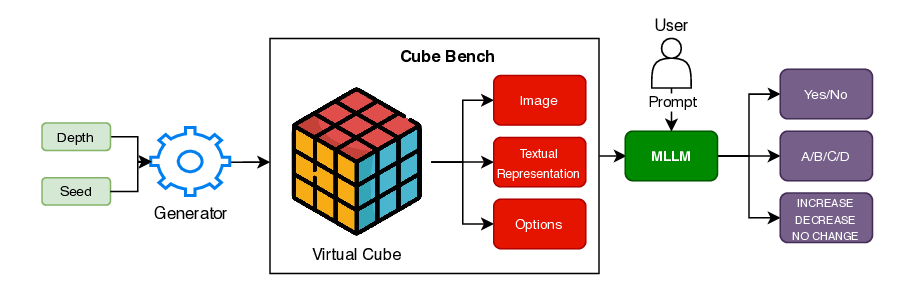
We introduce Cube Bench, a Rubik's-cube benchmark for evaluating spatial and sequential reasoning in multimodal large language models (MLLMs). The benchmark decomposes performance into five skills: (i) reconstructing cube faces from images and text, (ii) choosing the optimal next move, (iii) predicting the outcome of a candidate move without applying it, (iv) executing multi-step plans while recovering from mistakes, and (v) detecting and revising one's own errors. Using a shared set of scrambled cube states, identical prompts and parsers, and a single distance-to-solved metric, we compare recent MLLMs side by side as a function of scramble depth. Across seven MLLMs, accuracy drops sharply with depth; once a trajectory stalls or diverges, models rarely recover, and high face-reconstruction accuracy does not guarantee competent action selection or multi-step execution. A pronounced closed-vs open-source gap emerges: the strongest closed model leads on both single-step perception tasks and multistep control tasks, while open-weight models cluster near chance on the hardest settings; yet even the best MLLM degrades at higher cube complexity. A simple self-correction via reflective thinking yields modest gains but can also introduce overthinking. Cube Bench offers a compact, reproducible probe of sequential spatial reasoning in MLLMs. 1
Deep Dive into 큐브벤치 멀티모달 대형 언어 모델의 공간·순차 추론 평가.
We introduce Cube Bench, a Rubik’s-cube benchmark for evaluating spatial and sequential reasoning in multimodal large language models (MLLMs). The benchmark decomposes performance into five skills: (i) reconstructing cube faces from images and text, (ii) choosing the optimal next move, (iii) predicting the outcome of a candidate move without applying it, (iv) executing multi-step plans while recovering from mistakes, and (v) detecting and revising one’s own errors. Using a shared set of scrambled cube states, identical prompts and parsers, and a single distance-to-solved metric, we compare recent MLLMs side by side as a function of scramble depth. Across seven MLLMs, accuracy drops sharply with depth; once a trajectory stalls or diverges, models rarely recover, and high face-reconstruction accuracy does not guarantee competent action selection or multi-step execution. A pronounced closed-vs open-source gap emerges: the strongest closed model leads on both single-step perception tasks a
Multimodal large language models (MLLMs) now match or surpass prior systems on static perception benchmarks, i.e., recognizing objects, transcribing text in images, and answering short questions. However, practical deployments require models that can act interactively: taking actions, observing consequences, and staying coherent across many steps (closed-loop control). In such settings, small errors compound and recovery is rare; single-shot vision tests provide little signal about whether a model can plan, act, and 1 The code is available at https://github.com/dana-23/ cube-bench. correct itself. Surveys of multimodal benchmarks highlight this mismatch between static leaderboards and the demands of interactive use [13], and recent web-based agent evaluations similarly report that strong snapshot performance does not directly translate to reliable multi-step behaviour [10,31]. Classical work on sequential decision making has long emphasized how compounding errors degrade longhorizon performance [5].
Existing visual and spatial reasoning benchmarks mostly operate in this static regime. Synthetic datasets such as CLEVR, GQA, and related visual question answering benchmarks probe fine-grained spatial relations, counting, and logical composition from a single image, but typically stop at one-shot answers about a fixed scene. More recent multimodal leaderboards continue this pattern, emphasizing captioning, OCR, and short-form VQA on web images [13]. These settings test local spatial understanding, yet they rarely couple perception to an explicit dynamics model, track progress toward a goal, or require models to maintain a consistent internal state over multiple actions. On the other side, rich agentic environments on the web or in 3D scenes [10,31] introduce realistic noise and partial observability, but success metrics are often coarse, and it is difficult to disentangle failures of perception, planning, and control. We therefore lack a compact, generator-based domain that is simultaneously spatial and sequential, fully observed, exactly solvable, and regenerable on demand with strict fairness controls and oracle progress signals, making it possible to localize failures within a decision loop rather than aggregate them into a single static score.
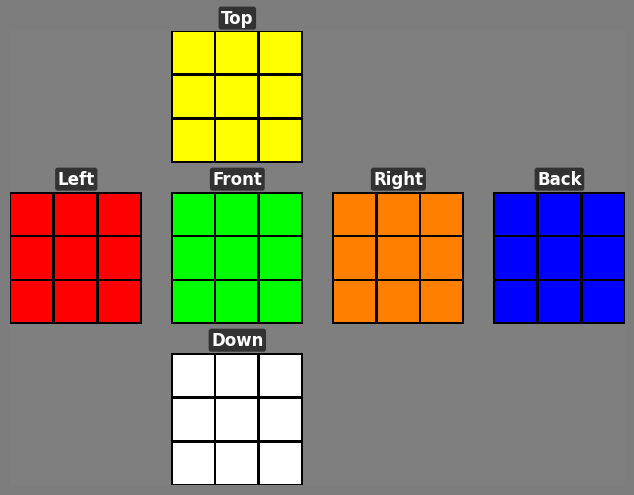
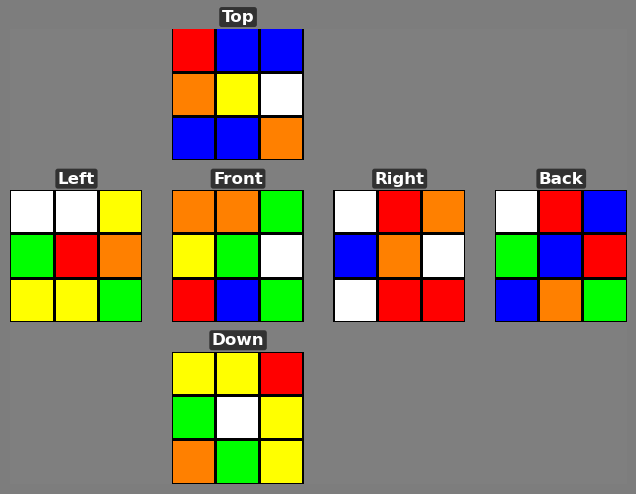
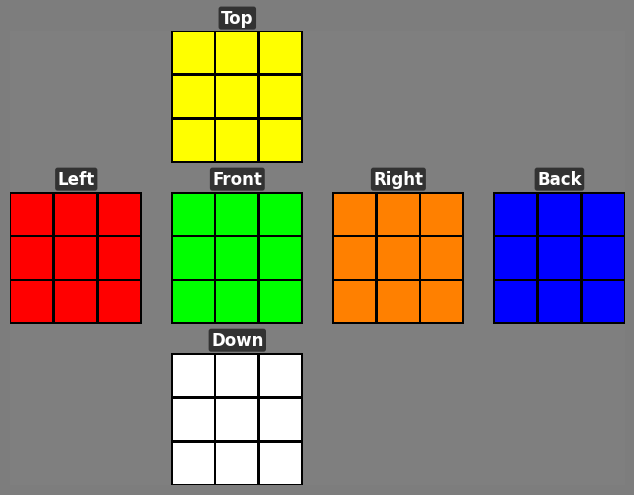
We introduce Cube Bench, a compact and fully controllable generator-based benchmark for studying long-horizon decision making under complete state information (see Figure 1). Conceptually, Cube Bench instantiates a simple TEA loop i.e., Transition → Evaluation → Argmin (Action): the cube dynamics define an exact transition model, oracle distance provides a scalar evaluation of each state, and the model’s role is to choose actions that (ideally) minimize distance to the goal at each step. Cube Bench uses the Rubik’s Cube as a testbed: it is visually simple, easy to simulate exactly, and combinatorially rich, with known optimal and near-optimal solvers that tell us precisely how many moves remain to reach the goal [11,21]. This lets us, unlike static image corpora, generate unlimited episodes, render both an image and a concise text description of each state, present a small menu of candidate moves, and compute exact feedback on how much each move improves or worsens the situation.
On top of this testbed we define seven tests that target different stages of the see → evaluate → act → reflect → recover loop: (i) reconstructing the full state from vision; (ii) checking consistency between vision and text; (iii) choosing the next move from a short list; (iv) judging whether a move helps or harms progress; (v) executing a sequence of moves to reach the goal; (vi) using self-reflection to revise an earlier choice; and (vii) trying to recover after the first error. Our framework enforces strict fairness controls, yielding measurements that are easy to replicate, difficult to game, and tailored to disentangle which stage of the TEA loop is failing.
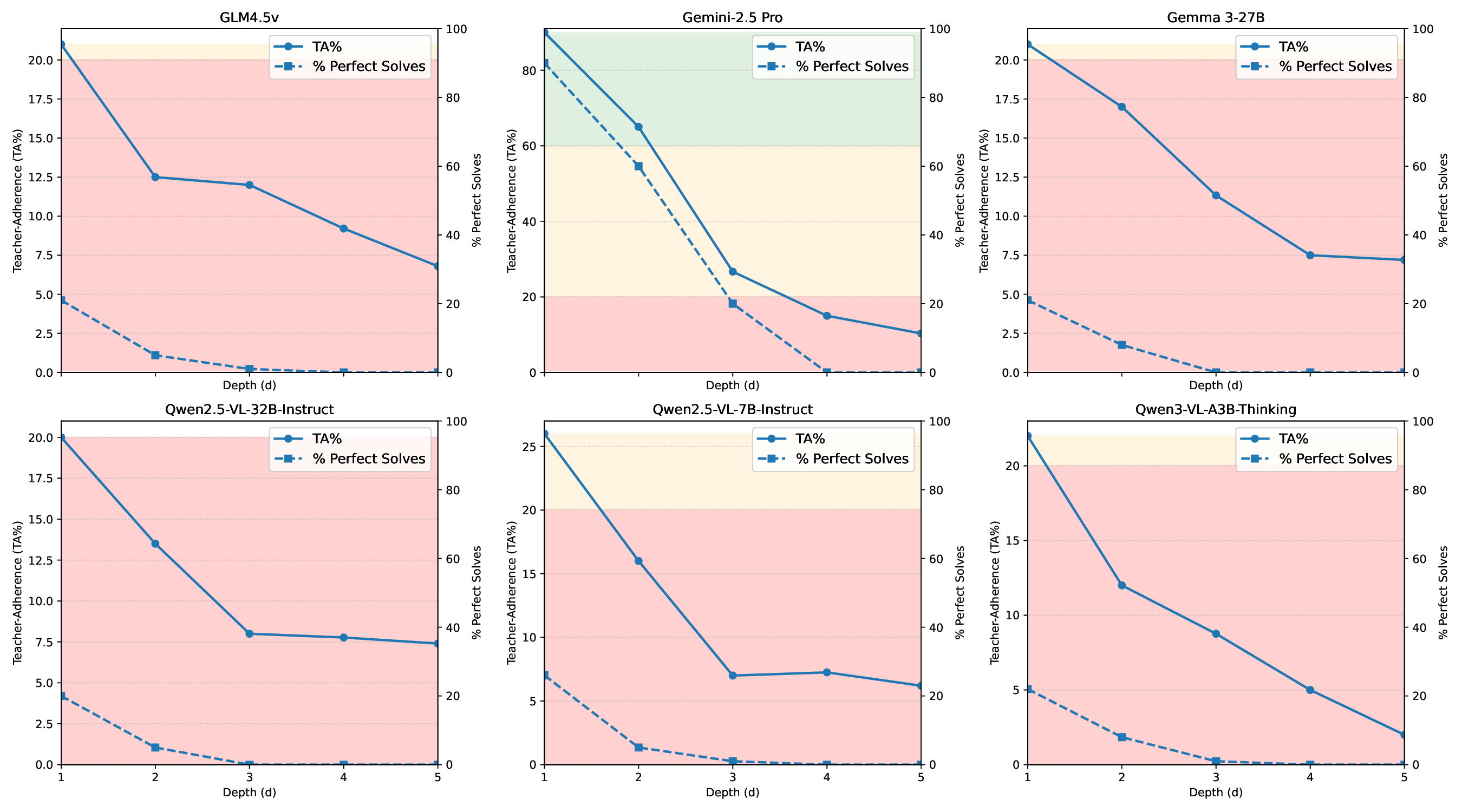
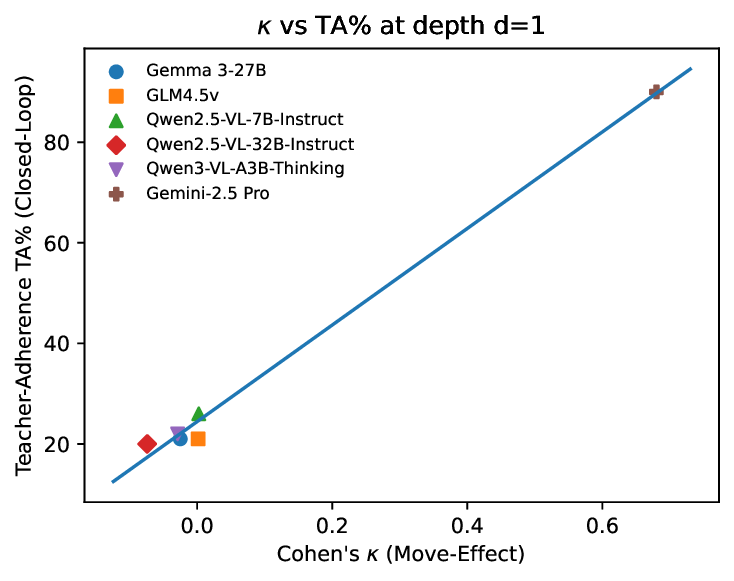
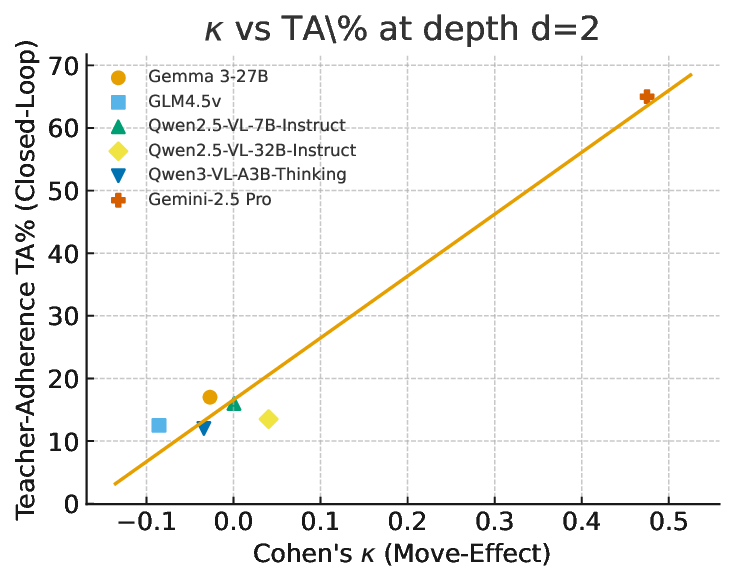
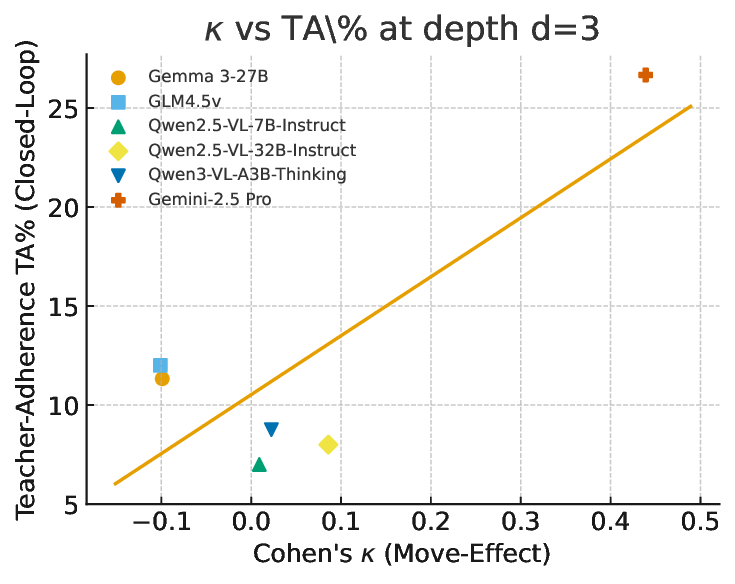
Evaluating strong open-and closed-source MLLMs under identical rules reveals a consistent picture. First, seeing is not reasoning: models that parse cube faces well still struggle to sustain improvement over multiple steps. Second, feedback breaks coherence: when outputs are fed back as inputs, error rates rise sharply with scramble depth, and recovery after a wrong move is rare. Third, reflection helps but is fragile: structured, label-aware reflection can repair some mistakes, yet unconstrained reflection can induce overthinking and instability [16,23,30]. Together, these results pinpoint lingering weaknesses in sequential spatial reasoning, i.e., state tracking and action evaluation, that are not revealed by current single-step benchmarks or coarse web-agent success rates.
Static perception benchmarks for MLLMs. A large body of work evaluates multimodal LLMs on single-shot perception tasks such as classification, detection, captioning, VQA, OCR, and charts, e.g., ImageNet, COCO, CLEVR, GQA, TextCaps, and ChartQA [7,8,14,17,2
…(Full text truncated)…
This content is AI-processed based on ArXiv data.