Phasor Measurement Units (PMUs) generate high-frequency, time-synchronized data essential for real-time power grid monitoring, yet the growing scale of PMU deployments creates significant challenges in latency, scalability, and reliability. Conventional centralized processing architectures are increasingly unable to handle the volume and velocity of PMU data, particularly in modern grids with dynamic operating conditions. This paper presents a scalable cloud-native architecture for intelligent PMU data processing that integrates artificial intelligence with edge and cloud computing. The proposed framework employs distributed stream processing, containerized microservices, and elastic resource orchestration to enable low-latency ingestion, real-time anomaly detection, and advanced analytics. Machine learning models for time-series analysis are incorporated to enhance grid observability and predictive capabilities. Analytical models are developed to evaluate system latency, throughput, and reliability, showing that the architecture can achieve sub-second response times while scaling to large PMU deployments. Security and privacy mechanisms are embedded to support deployment in critical infrastructure environments. The proposed approach provides a robust and flexible foundation for next-generation smart grid analytics.
Deep Dive into Scalable Cloud-Native Architectures for Intelligent PMU Data Processing.
Phasor Measurement Units (PMUs) generate high-frequency, time-synchronized data essential for real-time power grid monitoring, yet the growing scale of PMU deployments creates significant challenges in latency, scalability, and reliability. Conventional centralized processing architectures are increasingly unable to handle the volume and velocity of PMU data, particularly in modern grids with dynamic operating conditions. This paper presents a scalable cloud-native architecture for intelligent PMU data processing that integrates artificial intelligence with edge and cloud computing. The proposed framework employs distributed stream processing, containerized microservices, and elastic resource orchestration to enable low-latency ingestion, real-time anomaly detection, and advanced analytics. Machine learning models for time-series analysis are incorporated to enhance grid observability and predictive capabilities. Analytical models are developed to evaluate system latency, throughput, a
The modern power grid undergoes fundamental transformation driven by renewable energy integration and advanced monitoring technologies. PMUs provide synchronized measurements of electrical parameters at rates up to 120 samples per second [1], generating unprecedented data volumes. A typical utility deployment involves hundreds of PMUs, each generating gigabytes daily [2].
The integration of renewable energy sources introduces variability and intermittency, requiring sophisticated monitoring and control strategies. PMUs enable operators to observe rapid fluctuations and take corrective actions before system instability develops. However, the volume and velocity of PMU data overwhelm conventional processing architectures, necessitating new computational paradigms.
Artificial Intelligence offers transformative potential for PMU analytics. Machine learning algorithms identify subtle failure patterns, classify disturbances, and predict system behavior [3]. Edge AI techniques have demonstrated effectiveness in real-time anomaly detection for resource-constrained devices [4], [5]. However, computational demands coupled with distributed PMU networks present implementation challenges. Cloud computing provides scalable resources, elastic storage, and advanced networking capabilities [6].
Critical gaps in existing research include: (1) lack of scalability frameworks for AI algorithms across distributed cloud infrastructure, (2) insufficient analysis of latency-accuracy tradeoffs, (3) security vulnerabilities particularly denial-ofservice attacks in wide-area control, and (4) privacy concerns in cloud-aggregated grid data.
Our contributions include: a comprehensive theoretical framework for AI-enhanced cloud-based PMU analytics; mathematical formulations for distributed machine learning optimized for PMU time-series data; analysis of edge-cloud hybrid architectures with security and privacy considerations; and theoretical performance bounds for AI algorithms in cloud contexts.
Prior research on PMU data processing has primarily focused on centralized architectures deployed within utility control centers or regional data hubs [7]. Early synchrophasor analytics systems relied on monolithic processing pipelines optimized for deterministic execution and low-latency control applications. While effective for small-scale deployments, these architectures struggle to scale with the increasing number of PMUs, higher reporting rates, and the growing complexity of analytics driven by renewable integration and wide-area monitoring [8].
Recent studies have explored distributed and cloud-based approaches for power system analytics, leveraging big data frameworks to address scalability and fault tolerance challenges. Stream processing platforms such as Apache Kafka and Apache Flink have been adopted for high-throughput ingestion and real-time analytics of grid telemetry, while batch processing frameworks like Apache Spark enable large-scale historical analysis and model training. These systems provide horizontal scalability, fault tolerance, and decoupled producer-consumer semantics, which are essential for handling the continuous and bursty nature of PMU data streams [9].
Containerization and orchestration technologies, particularly Kubernetes, have further transformed cloud-native system design. Kubernetes enables elastic resource allocation, automated failover, and declarative deployment models, making it well-suited for managing microservice-based PMU analytics pipelines [10]. Prior work has demonstrated the effectiveness of container orchestration in improving resilience and operational efficiency in data-intensive applications, though its adoption in latency-sensitive power grid analytics remains an active research area.
Machine learning integration in PMU analytics has also advanced significantly, with research exploring deep learning, anomaly detection, and distributed learning techniques [11]. However, most existing studies emphasize algorithmic performance rather than the end-to-end system architecture required to operationalize these models reliably at scale. This gap motivates the need for unified cloud-native frameworks that jointly address data ingestion, processing, orchestration, security, and AI lifecycle management.
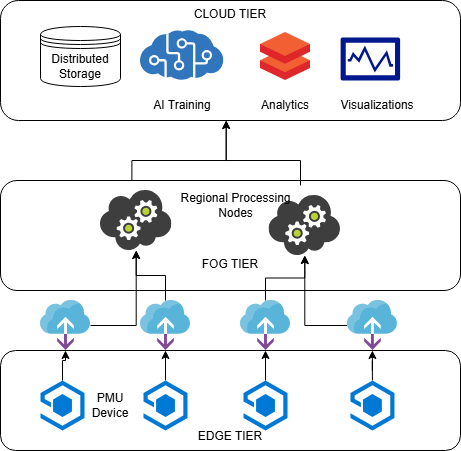
The proposed three-tier architecture builds upon these prior efforts by systematically integrating stream processing, distributed analytics, and elastic orchestration within a unified edge-fog-cloud framework. Technologies such as Apache Kafka are employed for durable, ordered, and fault-tolerant ingestion of PMU data streams, enabling backpressure handling and decoupling between data producers and consumers. Apache Spark supports scalable batch analytics and distributed machine learning, allowing model training and historical analysis to scale beyond single-node memory constraints. Kubernetes orchestrates containerized services across cloud and regional infrastructure, providing automated scalin
…(Full text truncated)…
This content is AI-processed based on ArXiv data.