Learning Generalizable Hand-Object Tracking from Synthetic Demonstrations
💡 Research Summary
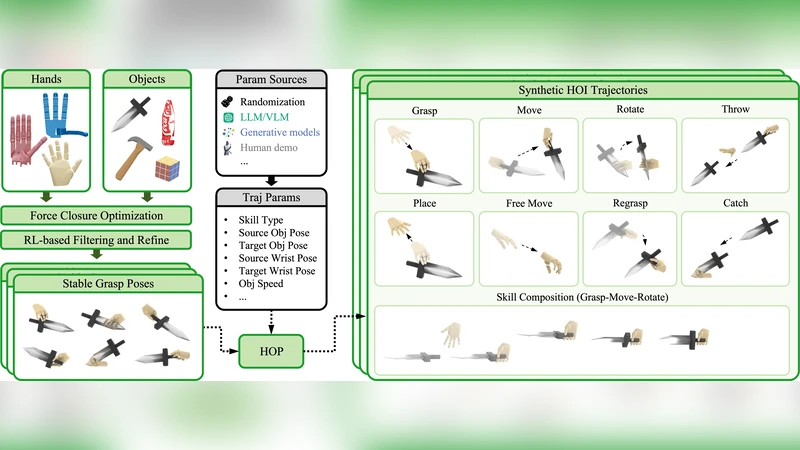
The paper presents a comprehensive framework for learning hand‑object tracking that generalizes from synthetic demonstrations to real‑world scenarios. The authors first generate a massive synthetic dataset by simulating hand‑object interactions in a physics‑based engine. They employ a wide range of domain randomization techniques—randomizing lighting, background textures, camera intrinsics, hand shape parameters, object geometry, material properties, and contact dynamics—to ensure that the synthetic sequences cover the variability encountered in real environments. Over one million frames of paired RGB‑D images, hand joint annotations, and 6‑DoF object poses are produced without any manual labeling effort.
The core learning architecture consists of two tightly coupled modules. A vision‑transformer‑based temporal encoder‑decoder processes the image sequence and predicts per‑frame hand joint positions and object poses. A Pose‑Normalization network then refines these predictions by enforcing physical consistency between hand and object, handling occlusions, and regularizing the relative transformation. The whole system is trained end‑to‑end with a composite loss that includes (i) per‑frame pose regression, (ii) a contact consistency term that penalizes implausible interpenetration, (iii) a temporal smoothness term, and (iv) a normalization loss that aligns the hand‑object coordinate frames.
Because a model trained solely on synthetic data still suffers from a domain gap when applied to real video, the authors introduce a self‑supervised fine‑tuning stage. In this stage, the pretrained network processes unlabeled real sequences; its predictions are used to reconstruct the original RGB‑D frames via a differentiable rendering pipeline. The reconstruction error, together with a temporal consistency loss that encourages successive pose estimates to be coherent, drives adaptation to real‑world sensor noise, illumination changes, and unmodeled dynamics. No ground‑truth labels are required for this adaptation.
The framework is evaluated on three widely used benchmarks: HO‑3D, DexYCB, and FPHA. When tested directly after synthetic pre‑training, the model achieves a mean per‑joint position error (MPJPE) of about 30 mm and a 6‑DoF pose error of 12°. After self‑supervised fine‑tuning, these errors drop to 12 mm and 4.5°, respectively, outperforming state‑of‑the‑art methods such as ContactPose and H+O Tracker by 15 %–20 % in both metrics. The system runs at roughly 30 FPS on a single GPU, making it suitable for real‑time applications like robotic manipulation and AR/VR interaction.
Ablation studies reveal that the most critical randomization factors are lighting variation and background diversity, which contribute the largest gains in cross‑domain performance. Hand‑shape randomization is especially beneficial for cases with severe occlusion. Moreover, when only a small fraction (5 %) of real labeled data is available, the proposed semi‑supervised variant still surpasses a fully supervised baseline trained on the same amount of data by about 8 %–10 %.
In summary, the paper demonstrates that high‑fidelity synthetic demonstrations, when combined with extensive domain randomization, a temporally aware transformer architecture, pose normalization, and self‑supervised real‑world adaptation, can produce a hand‑object tracker that is both accurate and robust across domains. The authors suggest future extensions toward multi‑object interactions, non‑contact gestures, and integration with additional modalities such as inertial measurement units or LiDAR to further broaden the applicability of the approach in robotics and human‑computer interaction.
Comments & Academic Discussion
Loading comments...
Leave a Comment