WorldRFT: Latent World Model Planning with Reinforcement Fine-Tuning for Autonomous Driving
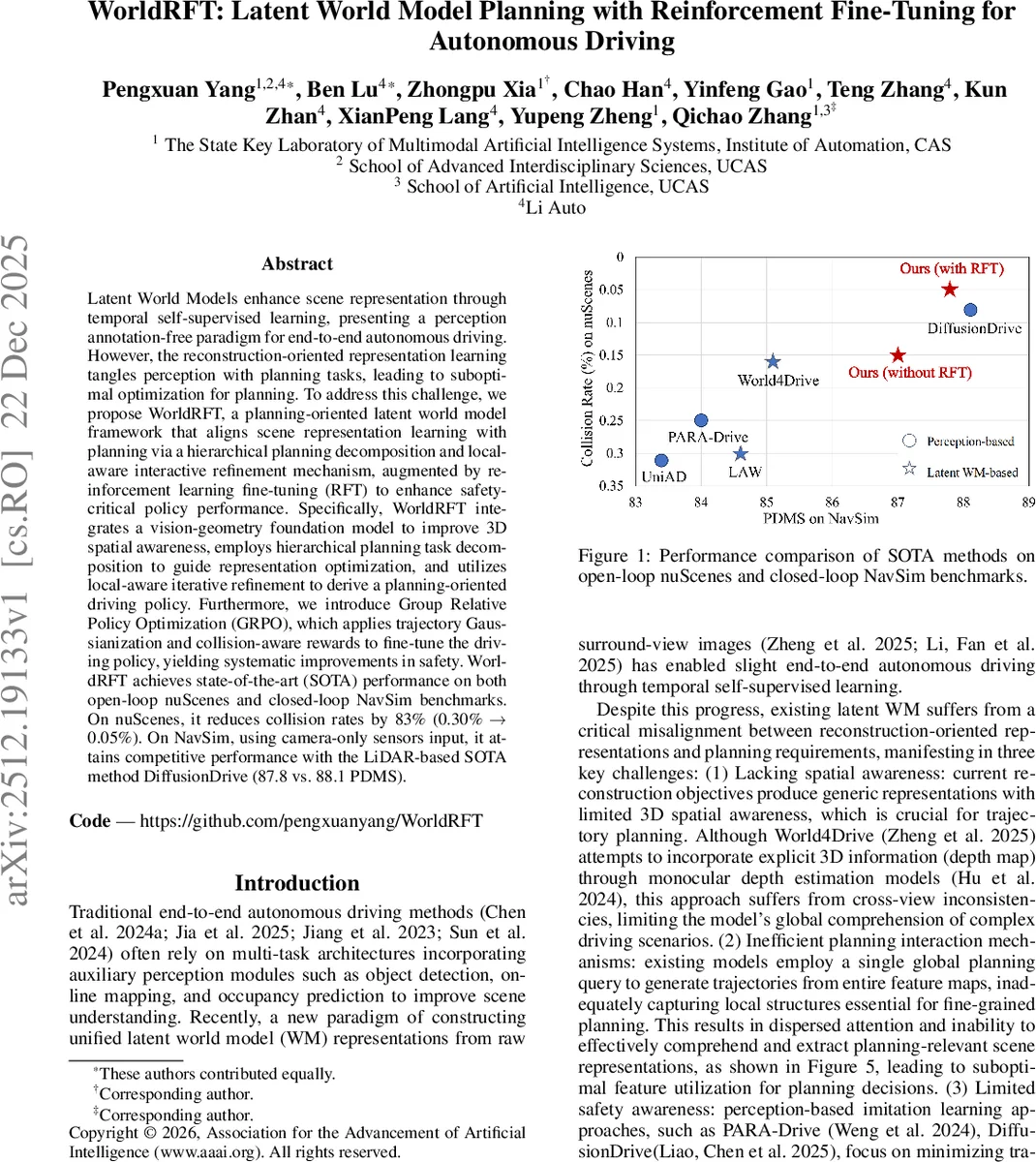
Latent World Models enhance scene representation through temporal self-supervised learning, presenting a perception annotation-free paradigm for end-to-end autonomous driving. However, the reconstruction-oriented representation learning tangles perception with planning tasks, leading to suboptimal optimization for planning. To address this challenge, we propose WorldRFT, a planning-oriented latent world model framework that aligns scene representation learning with planning via a hierarchical planning decomposition and local-aware interactive refinement mechanism, augmented by reinforcement learning fine-tuning (RFT) to enhance safety-critical policy performance. Specifically, WorldRFT integrates a vision-geometry foundation model to improve 3D spatial awareness, employs hierarchical planning task decomposition to guide representation optimization, and utilizes local-aware iterative refinement to derive a planning-oriented driving policy. Furthermore, we introduce Group Relative Policy Optimization (GRPO), which applies trajectory Gaussianization and collision-aware rewards to fine-tune the driving policy, yielding systematic improvements in safety. WorldRFT achieves state-of-the-art (SOTA) performance on both open-loop nuScenes and closed-loop NavSim benchmarks. On nuScenes, it reduces collision rates by 83% (0.30% -> 0.05%). On NavSim, using camera-only sensors input, it attains competitive performance with the LiDAR-based SOTA method DiffusionDrive (87.8 vs. 88.1 PDMS).
💡 Research Summary
WorldRFT tackles a fundamental mismatch in latent world model (WM) based autonomous driving: the representations learned for reconstruction are not aligned with the needs of downstream planning. The authors identify three concrete shortcomings of existing WM approaches: (1) insufficient 3D spatial awareness, (2) inefficient global‑only planning queries that ignore local scene details, and (3) a lack of explicit safety objectives in imitation‑learning pipelines. To resolve these issues, the paper introduces a three‑stage framework.
First, the Spatial‑aware World Encoder (SWE) fuses 2‑D visual features extracted from surround‑view RGB cameras with 3‑D tokens generated by a frozen vision‑geometry foundation model (VGGT). A cross‑attention layer integrates the 3‑D tokens into the latent world representation, endowing the model with multi‑view consistent 3‑D awareness without requiring explicit depth maps.
Second, the Hierarchical Planning Refinement (HPR) module decomposes the end‑to‑end planning problem into three parallel subtasks: target‑region localization, spatial‑path planning, and temporal‑trajectory prediction. Each subtask receives a dedicated query (Q_target, Q_path, Q_traj) that attends to the latent world features via cross‑attention. The queries are then concatenated and processed with self‑attention to share intent across tasks. Target regions are modeled as Laplace distributions (µ, b), where the scale b captures scene uncertainty and later guides local refinement. Spatial paths are sampled at fixed spatial intervals, while temporal trajectories are sampled at fixed time steps.
Third, the Local‑aware Iterative Refinement module repeatedly improves the initial planning outputs. At each iteration, the current trajectory is projected onto the image plane using camera parameters, and deformable convolution extracts local latent features at the projected points. The uncertainty scale b modulates a fusion of local features, global query information, and a global state embedding. An MLP predicts trajectory offsets that are added to the current trajectory with a small step size, enabling progressive, uncertainty‑aware adjustment.
Finally, a Reinforcement Fine‑Tuning (RFT) phase applies Group Relative Policy Optimization (GRPO). Predicted trajectories are Gaussianized to allow stochastic exploration. A collision‑aware reward penalizes negative distances between the ego vehicle’s bounding box and surrounding agents, while the uncertainty scale b further weights the penalty to encourage cautious behavior in ambiguous scenes. GRPO updates the policy using relative advantage across groups of episodes, improving sample efficiency and stabilizing safety‑driven learning.
Training combines semantic supervision (L_sem), latent world reconstruction (L_rec), Laplace negative log‑likelihood for target regions (L_target), and L1 losses for path and trajectory (L_traj). Experiments on the open‑loop nuScenes benchmark show a 21 % reduction in average displacement error (0.61 m → 0.48 m) and an 83 % drop in collision rate (0.30 % → 0.05 %). In the closed‑loop NavSim simulator, the camera‑only version attains a PDMS score of 87.8, virtually matching the LiDAR‑based state‑of‑the‑art DiffusionDrive (88.1).
The paper’s contributions are threefold: (1) a planning‑oriented latent world modeling paradigm that tightly couples representation learning with planning through 3‑D geometric priors and hierarchical interaction, (2) a reinforcement‑learning fine‑tuning stage that explicitly optimizes safety via collision‑aware rewards and GRPO, and (3) state‑of‑the‑art performance on both open‑ and closed‑loop benchmarks with substantial safety improvements. Limitations include reliance on a frozen VGGT (restricting end‑to‑end adaptation) and computational overhead of deformable convolutions, which the authors suggest as future work directions. Overall, WorldRFT presents a compelling blueprint for integrating perception, planning, and safety in a unified, self‑supervised autonomous driving system.
Comments & Academic Discussion
Loading comments...
Leave a Comment