When Less is More: 8-bit Quantization Improves Continual Learning in Large Language Models
💡 Research Summary
The paper presents the first systematic investigation of how quantization precision and replay buffer size interact in continual learning for large language models (LLMs). Using LLaMA‑3.1‑8B, the authors fine‑tune three precision variants—FP16 (full‑precision), 8‑bit integer (INT8), and 4‑bit integer (INT4)—with Low‑Rank Adaptation (LoRA) adapters (rank 8, α = 16, no dropout). They follow the LoRI benchmark protocol, training sequentially on three task families: Natural Language Understanding (NLU, eight datasets), Mathematical Reasoning (GSM8K), and Code Generation (CodeAlpaca evaluated with HumanEval pass@1).
For each transition (NLU → Math → Code) they interleave replay samples drawn uniformly from all previously seen data. Replay buffer sizes range from 0 % to 20 % of the original training data, sampled on a logarithmic scale (0 %, 0.1 %, 0.5 %, 1 %, 2 %, 5 %, 10 %, 20 %). This yields a “quantization‑replay trade‑off map” that reveals where performance collapses and where minimal replay suffices.
Key findings:
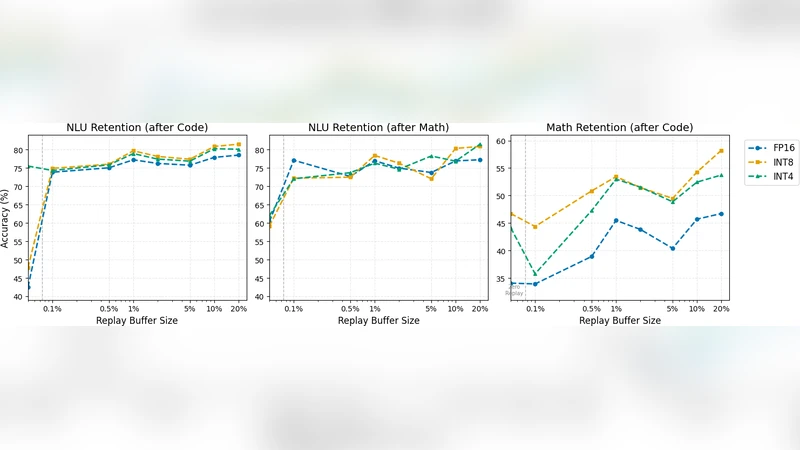
- Baseline quantization impact – In isolation, INT8 incurs only a 1–2 % drop relative to FP16, while INT4 loses 3–5 % accuracy. This confirms prior work that quantization‑aware training can preserve LLM performance even at low bit‑widths.
- Amplification under continual learning – Without replay, the modest baseline gaps widen dramatically. FP16 and INT8 retain more of their initial NLU accuracy, whereas INT4 suffers a >30 % absolute drop (e.g., from 72 % to 42 %).
- Replay as a stabilizer – Adding even a tiny replay buffer (0.1 %) dramatically improves retention across all precisions. At 0.1 % replay, NLU retention after Math training rises from ~45 % to ~65 % for every precision. INT8 consistently achieves the best balance: with 1–2 % replay it matches or exceeds FP16 forward accuracy on later tasks, and on Code generation INT4 even doubles FP16’s pass@1 (40 % vs 20 %).
- Quantization‑induced regularization hypothesis – The authors argue that quantization noise acts as an implicit regularizer, flattening the loss landscape and preventing over‑fitting to new task gradients. High‑precision FP16 models, while initially stronger, more readily overwrite prior knowledge because they lack this stochastic “anchor”. The noise in INT8/INT4 amplifies the effect of a few replayed examples, helping the model retain earlier knowledge while still learning new tasks.
Practical guidelines derived from the study:
- For NLU tasks, a small replay buffer (1–2 %) is sufficient regardless of precision.
- For Math reasoning, allocate at least 5–10 % replay; 8‑bit and 4‑bit models benefit from the higher end of this range.
- For Code generation, 4‑bit models see the biggest gains with 5–10 % replay, while 8‑bit and FP16 models may need 10–20 % to achieve comparable stability.
Limitations acknowledged include: (1) experiments are limited to LLaMA‑3.1‑8B and three task families, so results may not generalize to other architectures or multimodal domains; (2) only uniform quantization levels were explored—mixed‑precision or adaptive schemes remain untested; (3) the study lacks multi‑seed runs and confidence intervals, and uses simple reservoir sampling for replay rather than more sophisticated selection strategies.
Future work is suggested to expand the benchmark to larger and diverse models, investigate adaptive quantization, and explore advanced replay selection (e.g., herding, clustering) to further refine the quantization‑replay trade‑off.
Overall, the paper challenges the conventional wisdom that higher numerical precision is always beneficial for continual learning. It demonstrates that 8‑bit quantization can simultaneously reduce computational cost and improve long‑term knowledge retention, especially when paired with modest replay buffers. This insight has immediate implications for deploying LLMs in real‑world settings where models must be updated continuously under strict memory and latency constraints.
Comments & Academic Discussion
Loading comments...
Leave a Comment