📝 Original Info
- Title: On Extending Semantic Abstraction for Efficient Search of Hidden Objects
- ArXiv ID: 2512.22220
- Date: 2025-12-22
- Authors: Tasha Pais, Nikhilesh Belulkar
📝 Abstract
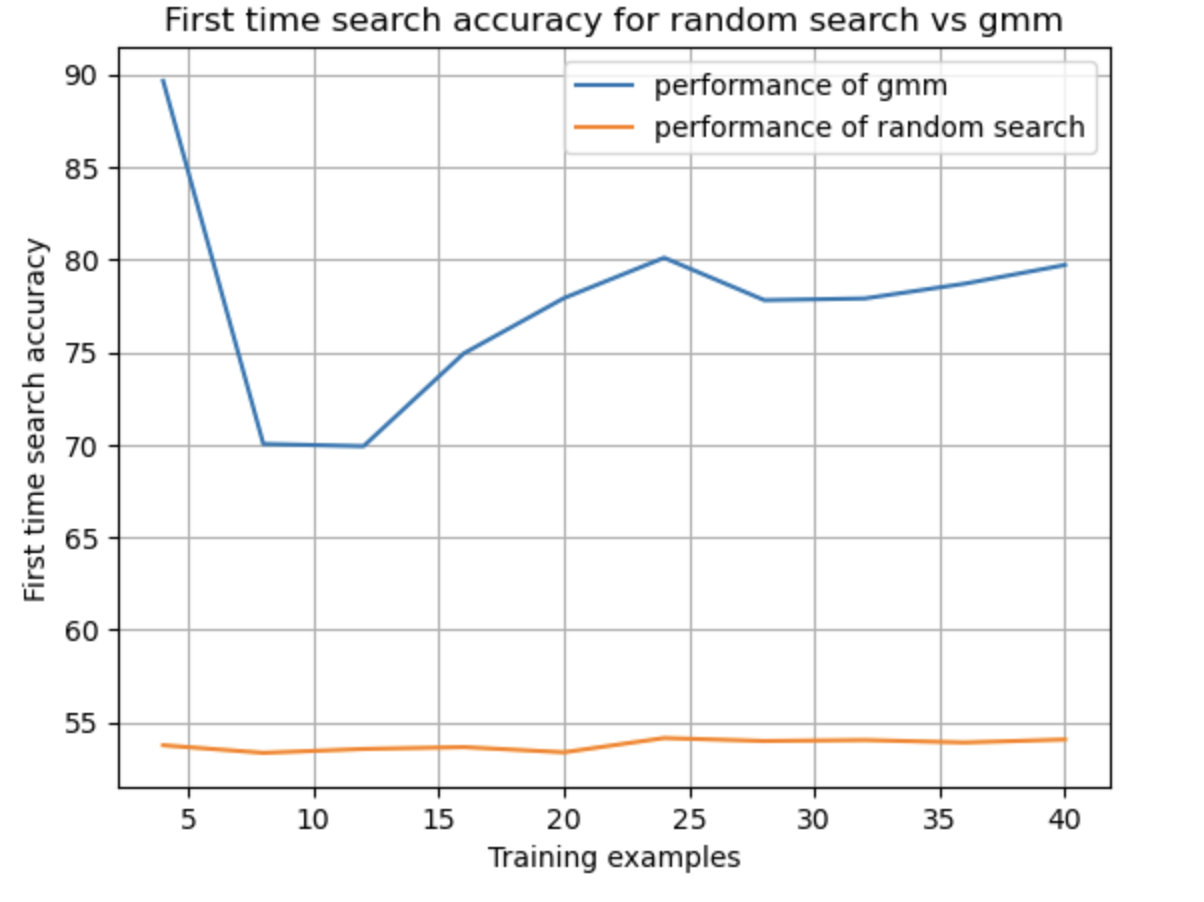
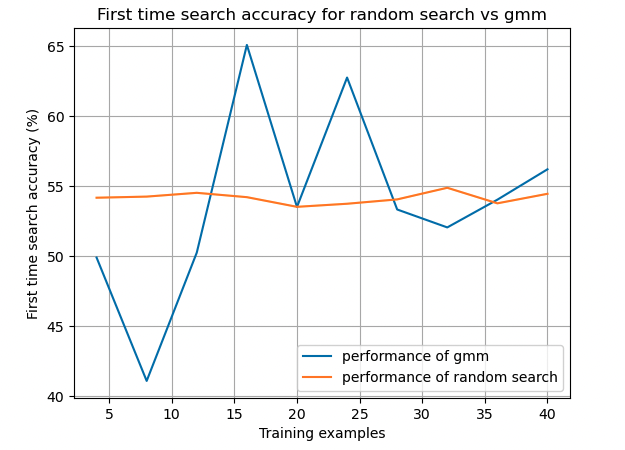
Semantic Abstraction's key observation is that 2D VLMs' relevancy activations roughly correspond to their confidence of whether and where an object is in the scene. Thus, relevancy maps are treated as "abstract object" representations. We use this framework for learning 3D localization and completion for the exclusive domain of hidden objects, defined as objects that cannot be directly identified by a VLM because they are at least partially occluded. This process of localizing hidden objects is a form of unstructured search that can be performed more efficiently using historical data of where an object is frequently placed. Our model can accurately identify the complete 3D location of a hidden object on the first try significantly faster than a naive random search. These extensions to semantic abstraction hope to provide household robots with the skills necessary to save time and effort when looking for lost objects.
💡 Deep Analysis
Deep Dive into On Extending Semantic Abstraction for Efficient Search of Hidden Objects.
Semantic Abstraction’s key observation is that 2D VLMs’ relevancy activations roughly correspond to their confidence of whether and where an object is in the scene. Thus, relevancy maps are treated as “abstract object” representations. We use this framework for learning 3D localization and completion for the exclusive domain of hidden objects, defined as objects that cannot be directly identified by a VLM because they are at least partially occluded. This process of localizing hidden objects is a form of unstructured search that can be performed more efficiently using historical data of where an object is frequently placed. Our model can accurately identify the complete 3D location of a hidden object on the first try significantly faster than a naive random search. These extensions to semantic abstraction hope to provide household robots with the skills necessary to save time and effort when looking for lost objects.
📄 Full Content
On Extending Semantic Abstraction for Efficient
Search of Hidden Objects
Nikhilesh Belulkar
nb2953@columbia.edu
Department of Computer Science
Columbia University
New York, NY 10025
Tasha Pais
tdp2129@columbia.edu
Department of Computer Science
Columbia University
New York, NY 10025
Abstract
Semantic Abstraction’s key observation is that 2D VLMs’ relevancy activations
roughly correspond to their confidence of whether and where an object is in the
scene. Thus, relevancy maps are treated as "abstract object" representations. We
use this framework for learning 3D localization and completion for the exclusive
domain of hidden objects, defined as objects that cannot be directly identified by a
VLM because they are at least partially occluded. This process of localizing hidden
objects is a form of unstructured search that can be performed more efficiently using
historical data of where an object is frequently placed. Our model can accurately
identify the complete 3D location of a hidden object on the first try significantly
faster than a naive random search. These extensions to semantic abstraction hope
to provide household robots with the skills necessary to save time and effort when
looking for lost objects.
Additional Resources: Code
1
Problem Definition
In the world of personal assistant robots, retrieval of specific objects given a time constraint is an
important task. For instance, a user could command a robot to "find my keys" while getting ready to
leave the house. Since the robot has sufficiently explored the environment from past actions and has
a quantitative understanding of where an individual’s unique preference for an object’s placement
is, the robot’s memory is much better suited to quickly search and retrieve an object while a user
continues a different task. This can be a form of human-robot collaboration when the task is clear
and often repeated.
A point cloud is the most complete representation of an object in 3D space. When aggregating views
of a partially hidden object from multiple camera angles, it can be difficult to localize the object.
Given that an object may be hidden in one view and visible in another, we concatenate an object’s
point cloud from multiple views.
2
Method
Our method uses semantic abstraction as the primary system over which we develop our algorithm to
optimize search.
The key steps of our procedure are summarized below:
1. Collect multiple egocentric views of the environment through interaction, ex: opening
cabinets and drawers.
I Can’t Believe It’s Not Better Workshop III at NeurIPS 2022.
arXiv:2512.22220v1 [cs.CV] 22 Dec 2025
2. From these views, query semantic abstraction with objects and their labels to generate point
clouds for individual objects, ex: "apple in fridge", "tomato in fridge", "fork in drawer".
3. Aggregate the location data from several views and use the Expectation-Maximization
algorithm to generate a Gaussian Mixture Model (GMM) about the location of a particular
object.
4. Once this GMM has been developed, use it to optimize search times when queried for a
specific object.
2.1
Step One
The robot interacts with its environment collecting several different views. Since this is an embodied
AI task, we chose RoboTHOR as the simulation environment. This random interaction is currently an
explicitly predefined procedure in our code. In the future, we intend to use an LLM like ChatGPT to
translate natural language queries into actions and provide an understanding of where certain objects
are typically located to begin search.
Figure 1: The camera view most often used to query Semantic Abstraction
2.2
Step Two
Given an image, we utilized much of the infrastructure provided by semantic abstraction to generate
a point cloud representing the relevancy of different parts of the image to the query provided.
A query is made to CLIP. CLIP is a database that contains images and captions. Through contrastive
learning CLIP localizes the parts of an image relevant to a caption. It utilizes this understanding to
score how relevant each pixel of an image is to a particular query. For instance in the image below a
relevancy score is provided to each pixel in the image when queried with "fork in cabinet".
Further, we also used the intrinsic and extrinsic camera parameters of each view to map where each
pixel is in three-dimensional space. This is best visualized through the point cloud produced below.
Figure 2: Query to localize the location of a fork inside a cabinet
Once each pixel’s 3D location is mapped to its corresponding CLIP relevancy score, we can create a
buffer of point clouds in 3-dimensional space labeled with their object names.
2
2.3
Step Three
Once we have the precise location of an object mapped over time, we then use this data to perform
the Expectation-Maximization algorithm to generate a Gaussian Mixture Model.
The EM randomly initializes the means and covariance matrices of a specific number of Gaussian
distributions. The algorithm then computes t
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.