Transformers operate as horizontal token-bytoken scanners; at each generation step, attending to an ever-growing sequence of tokenlevel states. This access pattern increases prefill latency and makes long-context decoding more memory-bound, as KV-cache reads and writes dominate inference time over arithmetic operations. We propose Parallel Hierarchical Operation for TOp-down Networks (PHOTON), a hierarchical autoregressive model that replaces horizontal scanning with vertical, multi-resolution context scanning. PHOTON maintains a hierarchy of latent streams: a bottom-up encoder compresses tokens into low-rate contextual states, while lightweight top-down decoders reconstruct fine-grained token representations in parallel. We further introduce recursive generation that updates only the coarsest latent stream and eliminates bottom-up re-encoding. Experimental results show that PHOTON is superior to competitive Transformer-based language models regarding the throughput-quality tradeoff, providing advantages in long-context and multi-query tasks. In particular, this reduces decode-time KV-cache traffic, yielding up to 10 3 × higher throughput per unit memory.
Deep Dive into 수직 계층 구조로 토큰 생성 가속화하는 PHOTON 모델.
Transformers operate as horizontal token-bytoken scanners; at each generation step, attending to an ever-growing sequence of tokenlevel states. This access pattern increases prefill latency and makes long-context decoding more memory-bound, as KV-cache reads and writes dominate inference time over arithmetic operations. We propose Parallel Hierarchical Operation for TOp-down Networks (PHOTON), a hierarchical autoregressive model that replaces horizontal scanning with vertical, multi-resolution context scanning. PHOTON maintains a hierarchy of latent streams: a bottom-up encoder compresses tokens into low-rate contextual states, while lightweight top-down decoders reconstruct fine-grained token representations in parallel. We further introduce recursive generation that updates only the coarsest latent stream and eliminates bottom-up re-encoding. Experimental results show that PHOTON is superior to competitive Transformer-based language models regarding the throughput-quality tradeoff, p
Transformer-based language models have achieved remarkable capabilities; however, the inference cost rapidly increases with context length under recent serving workloads (Bahdanau et al., 2014;Vaswani et al., 2017). Even with KV caching, autoregressive Transformers operate as horizontal token-by-token scanners; each new token attends to a continually growing flat history of token-level states. The prefill stage computes and stores the KV cache for the entire prompt. During decoding, throughput becomes increasingly memory-bound as the context grows, since each step repeatedly reads from and updates a large KV cache. As a re-sult, performance is often limited by memory bandwidth rather than computational capacity. The bottleneck is most pronounced in long-context, multiquery serving.
This raises a simple question: Must generation remain horizontal token-by-token scanning over a flat history? The structure of natural language suggests otherwise (Chomsky, 2002;Lambek, 1958;Hauser et al., 2002;Halle, 1973). Natural language is inherently hierarchical: subwords form words, words form sentences, and sentences create documents. Moreover, coherent generation relies on maintaining an evolving discourse state rather than repeatedly revisiting all fine-grained token representations (Mann and Thompson, 1988;Grosz and Sidner, 1986;Grosz et al., 1995). These observations motivate vertical scanning, which represents context through compact coarse states and descends to token-level detail only when necessary.
Hierarchical or multi-scale sequence modeling has recently been explored (Pappagari et al., 2019;Han et al., 2021;Dai et al., 2020;Nawrot et al., 2022Nawrot et al., , 2023;;Fleshman and Van Durme, 2023;Mujika, 2023;Yu et al., 2023;Ho et al., 2024). In particular, Block Transformer (Ho et al., 2024) reduces inference-time KV overhead by separating coarse block-level computation from token-level decoding. However, it employs only a single-level hierarchy that largely serves as a block-structured attention mechanism for efficiency, rather than maintaining a persistent multi-level state that is updated across abstractions during inference.
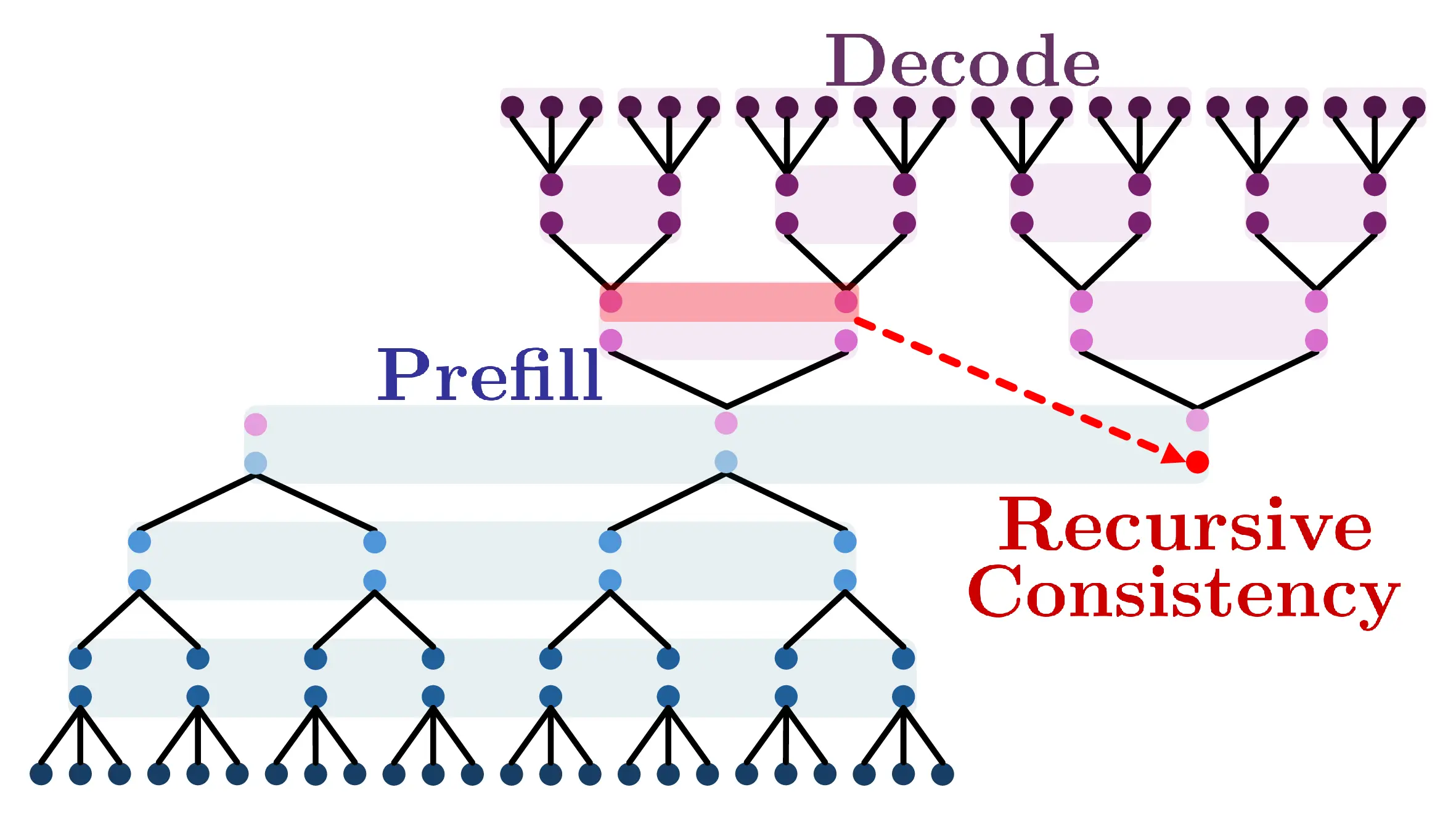
We introduce Parallel Hierarchical Operation for TOp-down Networks (PHOTON), a hierarchical autoregressive model that replaces horizontal token-by-token scanning with multi-resolution vertical scanning over contextual states. As illustrated in Figure 1, PHOTON constructs a hierarchy of latent streams via (i) a bottom-up encoder that compresses tokens into low-rate contextual states and (ii) a top-down decoder stack that progressively re- constructs finer representations using local autoregressive modules with bounded attention. Since these local decoders operate independently across lower-level contexts, decoding can proceed in parallel across these contexts. PHOTON is trained using standard next-token prediction along with auxiliary objectives that enforce recursive consistency at multiple levels by aligning bottom-up summaries with top-down reconstructions. We also propose recursive generation: unlike Block Transformer, PHOTON avoids bottom-up re-encoding of newly generated tokens by directly updating the coarse stream from decoder-side reconstructions. This design retains only the hierarchical decoder on the GPU during decoding, thus reducing both model residency and KV-cache footprint.
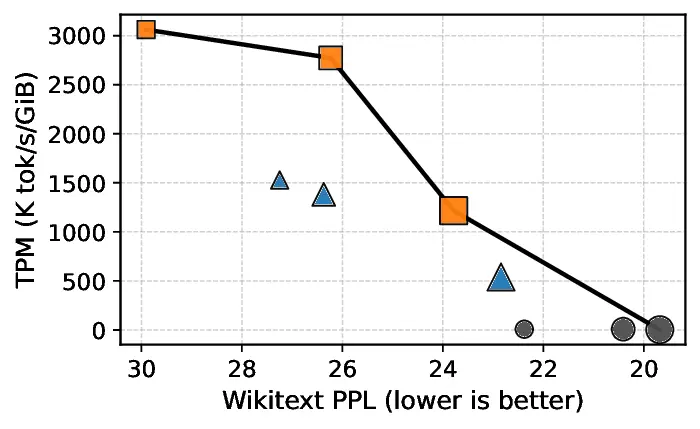
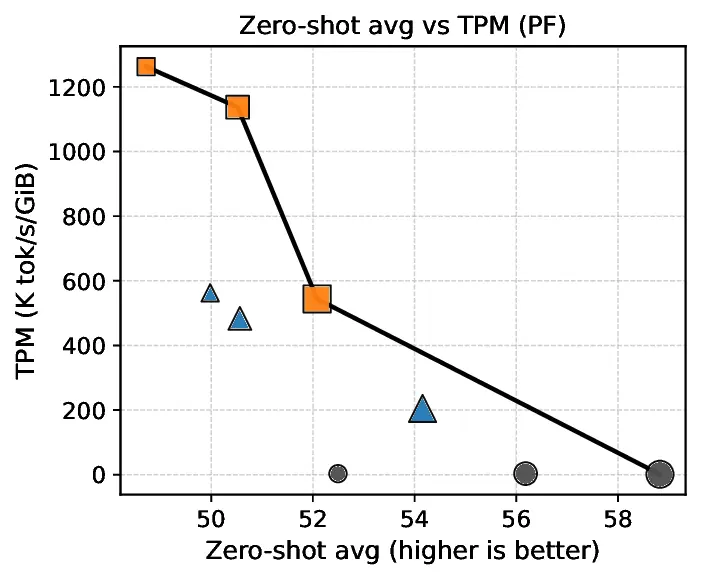
Experiments show that PHOTON achieves a better Pareto frontier in terms of throughput per unit memory and quality compared to both vanilla and Block Transformer baselines. In particular, by reducing decode-time KV-cache traffic, PHOTON achieves up to 10 3 × higher throughput per unit of memory.
This section presents the architecture of PHOTON, a hierarchical autoregressive language model for sequence modeling across multiple resolutions. PHO-TON comprises two components: (i) a hierarchical encoder that progressively compresses the input token sequence into coarser latent streams, and (ii) a hierarchical decoder that reconstructs finergrained streams in a top-down manner using local autoregressive decoders with strictly bounded attention, enabling parallel decoding across independent lower-level contexts. A conceptual overview is provided in Figure 1.
Notation. Let V denote the vocabulary and t 1:T ∈ V T be a sequence of length T . Define [N ] := {1, . . . , N }. Let X (0) ∈ R T ×D 0 be the embedding matrix, where D 0 is the base hidden dimension. We consider an L-level hierarchy indexed by l ∈ {1, . . . , L}. Each level l uses a chunk length C l ∈ N that groups level-(l -1) states into level-l units. Let M 0 := T and M l := M l-1/C l denote the number of units at level l. Thus, level l consists of M l contiguous chunks, each spanning C l level-(l -1) units. Choose chunk lengths such that T is divisible by C ≤L := L k=1 C k , ensuring all M l are integers. For each g ∈ [M l ], define the index set of the g-th level-l chunk as
The corresponding level-(l-1) subtensor is defined as follows:
All lea
…(Full text truncated)…
This content is AI-processed based on ArXiv data.