📝 Original Info
- Title: CrashChat: A Multimodal Large Language Model for Multitask Traffic Crash Video Analysis
- ArXiv ID: 2512.18878
- Date: 2025-12-21
- Authors: Researchers from original ArXiv paper
📝 Abstract
Automating crash video analysis is essential to leverage the growing availability of driving video data for traffic safety research and accountability attribution in autonomous driving. Crash video analysis is a challenging multitask problem due to the complex spatiotemporal dynamics of crash events in video data and the diverse analytical requirements involved. It requires capabilities spanning crash recognition, temporal grounding, and high-level video understanding. Existing models, however, cannot perform all these tasks within a unified framework, and effective training strategies for such models remain underexplored. To fill these gaps, this paper proposes CrashChat, a multimodal large language model (MLLM) for multitask traffic crash analysis, built upon VideoLLaMA3. CrashChat acquires domain-specific knowledge through instruction fine-tuning and employs a novel multitask learning strategy based on task decoupling and grouping, which maximizes the benefit of joint learning within and across task groups while mitigating negative transfer. Numerical experiments on consolidated public datasets demonstrate that CrashChat consistently outperforms existing MLLMs across model scales and traditional vision-based methods, achieving state-of-the-art performance. It reaches near-perfect accuracy in crash recognition, a 176\% improvement in crash localization, and a 40\% improvement in the more challenging pre-crash localization. Compared to general MLLMs, it substantially enhances textual accuracy and content coverage in crash description and reasoning tasks, with 0.18-0.41 increases in BLEU scores and 0.18-0.42 increases in ROUGE scores. Beyond its strong performance, CrashChat is a convenient, end-to-end analytical tool ready for practical implementation. The dataset and implementation code for CrashChat are available at https://github.com/Liangkd/CrashChat.
💡 Deep Analysis
Deep Dive into CrashChat: A Multimodal Large Language Model for Multitask Traffic Crash Video Analysis.
Automating crash video analysis is essential to leverage the growing availability of driving video data for traffic safety research and accountability attribution in autonomous driving. Crash video analysis is a challenging multitask problem due to the complex spatiotemporal dynamics of crash events in video data and the diverse analytical requirements involved. It requires capabilities spanning crash recognition, temporal grounding, and high-level video understanding. Existing models, however, cannot perform all these tasks within a unified framework, and effective training strategies for such models remain underexplored. To fill these gaps, this paper proposes CrashChat, a multimodal large language model (MLLM) for multitask traffic crash analysis, built upon VideoLLaMA3. CrashChat acquires domain-specific knowledge through instruction fine-tuning and employs a novel multitask learning strategy based on task decoupling and grouping, which maximizes the benefit of joint learning withi
📄 Full Content
CrashChat: A Multimodal Large Language Model
for Multitask Traffic Crash Video Analysis
Kaidi Liang1[0009-0001-9129-2744], Ke Li1[0009-0001-4958-3302], Xianbiao
Hu2[0000-0002-0149-1847], and Ruwen Qin1[0000-0003-2656-8705]
1 Stony Brook University, Department of Civil Engineering, Stony Brook, NY 11794,
USA
{kaidi.liang,ke.li,ruwen.qin}@stonybrook.edu
2 The Pennsylvania State University, Department of Civil and Environmental
Engineering, University Park, PA 16802-1408, USA
xbhu@psu.edu
Abstract. Automating crash video analysis is essential to leverage the
growing availability of driving video data for traffic safety research and
accountability attribution in autonomous driving. Crash video analysis
is a challenging multitask problem due to the complex spatiotemporal
dynamics of crash events in video data and the diverse analytical re-
quirements involved. It requires capabilities spanning crash recognition,
temporal grounding, and high-level video understanding. Existing mod-
els, however, cannot perform all these tasks within a unified framework,
and effective training strategies for such models remain underexplored.
To fill these gaps, this paper proposes CrashChat, a multimodal large
language model (MLLM) for multitask traffic crash analysis, built upon
VideoLLaMA3. CrashChat acquires domain-specific knowledge through
instruction fine-tuning and employs a novel multitask learning strategy
based on task decoupling and grouping, which maximizes the benefit of
joint learning within and across task groups while mitigating negative
transfer. Numerical experiments on consolidated public datasets demon-
strate that CrashChat consistently outperforms existing MLLMs across
model scales and traditional vision-based methods, achieving state-of-
the-art performance. It reaches near-perfect accuracy in crash recogni-
tion, a 176% improvement in crash localization, and a 40% improve-
ment in the more challenging pre-crash localization. Compared to general
MLLMs, it substantially enhances textual accuracy and content cover-
age in crash description and reasoning tasks, with 0.18-0.41 increases in
BLEU scores and 0.18-0.42 increases in ROUGE scores. Beyond its strong
performance, CrashChat is a convenient, end-to-end analytical tool ready
for practical implementation. The dataset and implementation code for
CrashChat are available at https://github.com/Liangkd/CrashChat.
Keywords: Multimodal Large Language Model · Video Understanding
· Visual Risk Perception · Multitask Learning · Autonomous Driving.
arXiv:2512.18878v1 [cs.CV] 21 Dec 2025
2
Liang et al.
1
Introduction
Video data are increasingly recognized as a readily accessible and informative
source for traffic crash analysis, especially for autonomous vehicles. For instance,
retrieving and analyzing crash footage captured by in-vehicle cameras can pro-
vide objective evidence about adverse events, facilitating timely and accurate
crash reporting. Given the vast volume of captured video data and the complex-
ity of crash events, automating crash-related video analysis has become a critical
need. Specifically, a tool is needed to automatically identify anomalous segments
from massive amounts of video data, ground them in their temporal evolution,
and generate a semantic understanding of the events.
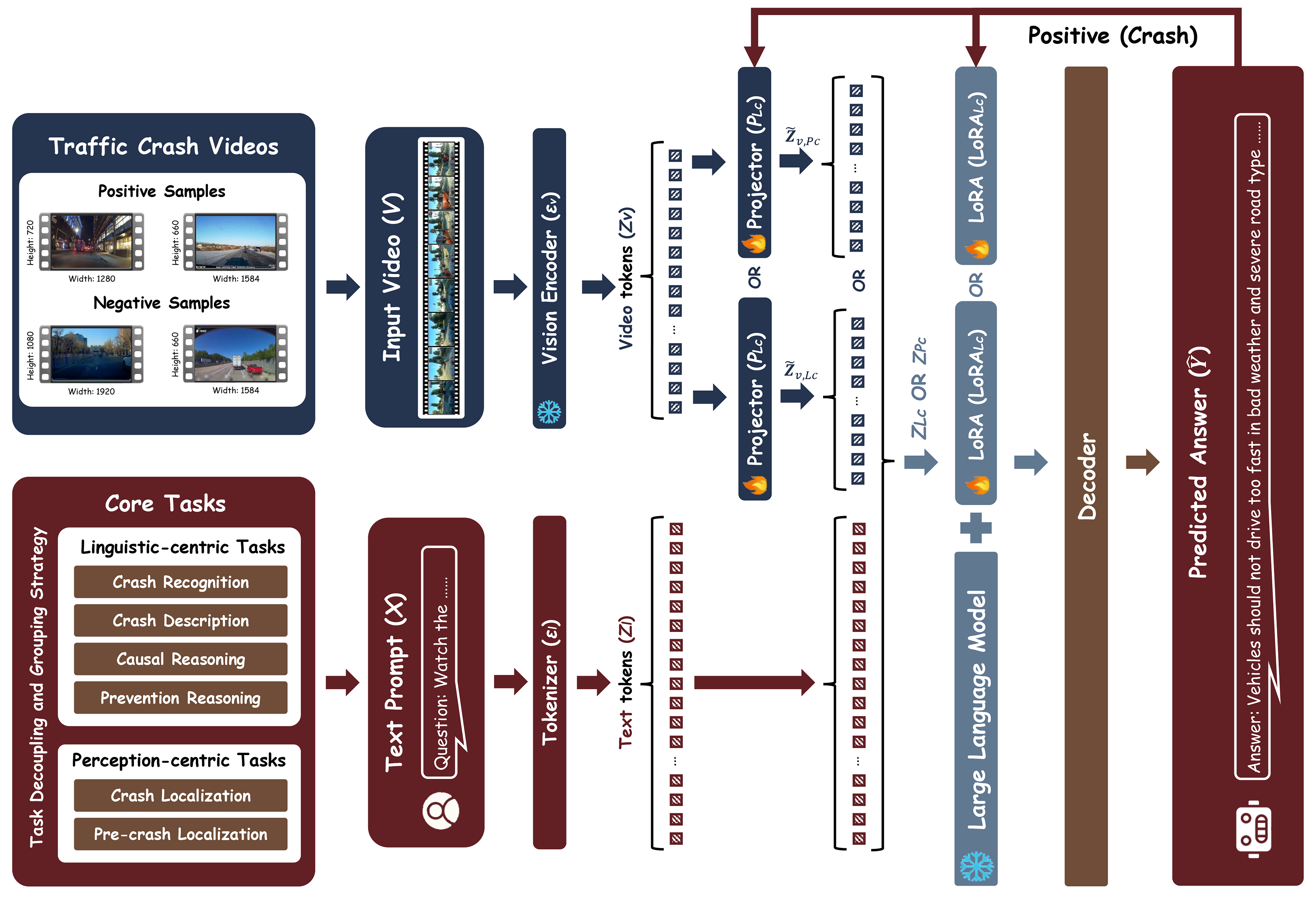
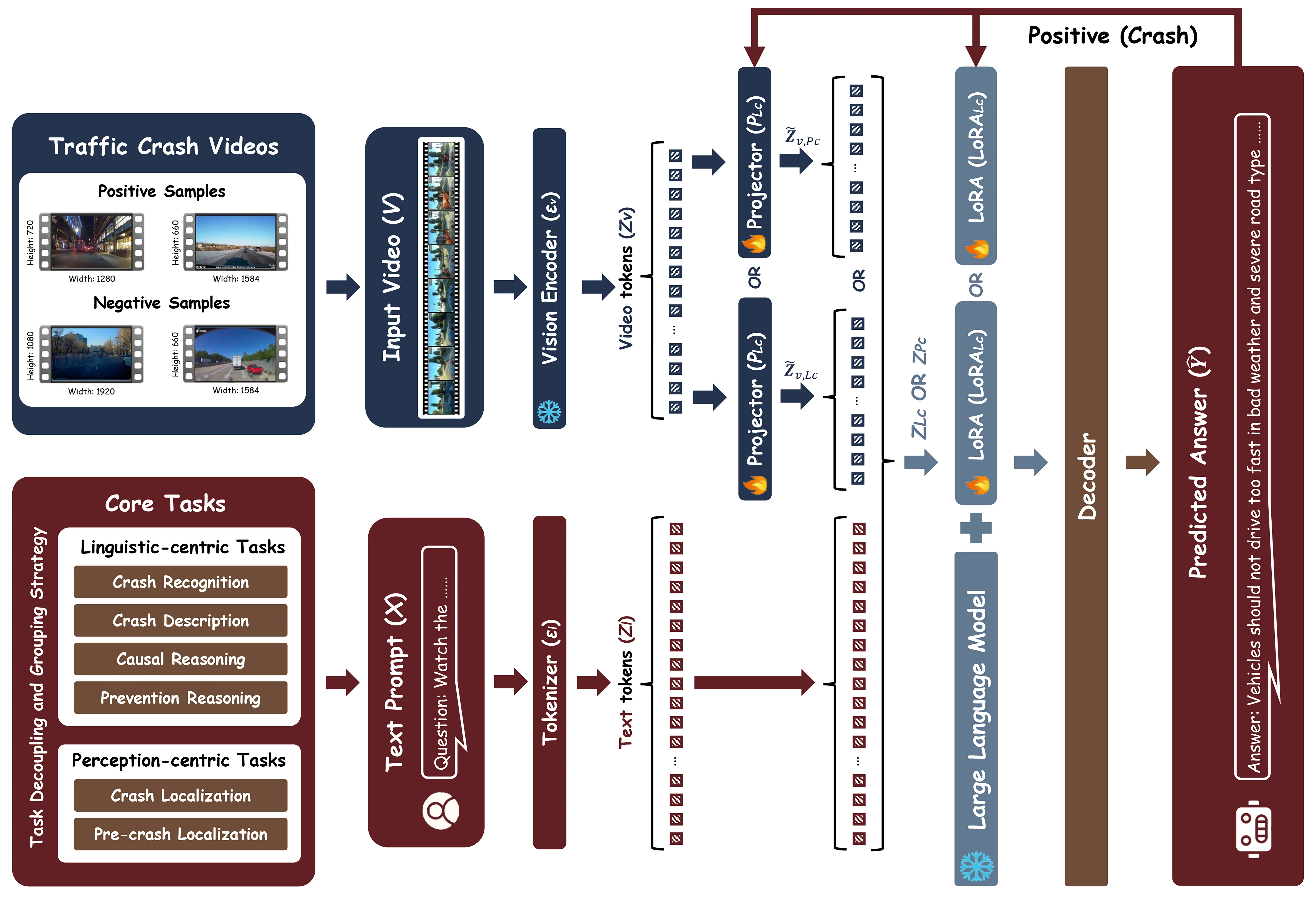
Crash video analysis is inherently a multitask problem. The desired capabili-
ties, including crash recognition, temporal grounding, and understanding, can be
enabled by six core tasks, as illustrated in Fig. 1. Crash recognition determines
whether the input video contains a crash event. Crash localization identifies the
precise interval during which the crash occurred, while pre-crash localization
further determines when visual cues first appeared, signaling that a crash is im-
minent. Crash description provides a structured narrative of the event. Causal
reasoning infers the underlying causes of the crash, and prevention reasoning
identifies conditions or actions that could have avoided it.
Fig. 1. CrashChat - a multitask multimodal large language model performing six core
tasks in support of crash video analysis in a unified way
CrashChat: MLLM for Crash Video Analysis
3
While focusing on different aspects of crash video analysis, the six tasks are
intertwined. Crash recognition narrows down to the target segment, thereby en-
hancing the efficiency of temporal grounding. Further unfolding the identified
segment into normal, pre-crash, and crash phases assists in distinguishing causal
actions from subsequent effects. Conversely, the improved understanding of crash
events will further enhance crash recognition. Therefore, a multitask framework
can perform better than its monotask counterparts. Positive outcomes from mul-
titasking rely on a good understanding of the relationship among those tasks and
appropriate designs of the training strategy [2]. Yet, this remains largely unex-
plored for crash video analysis, where task interactions are complex.
Multimodal large lang
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.