📝 Original Info
- Title: Multi-Agent LLM Committees for Autonomous Software Beta Testing
- ArXiv ID: 2512.21352
- Date: 2025-12-21
- Authors: Researchers from original ArXiv paper
📝 Abstract
Manual software beta testing is costly and time-consuming, while single-agent large language model (LLM) approaches suffer from hallucinations and inconsistent behavior. We propose a multi-agent committee framework in which diverse vision-enabled LLMs collaborate through a three-round voting protocol to reach consensus on testing actions. The framework combines model diversity, persona-driven behavioral variation, and visual user interface understanding to systematically explore web applications. Across 84 experimental runs with 9 testing personas and 4 scenarios, multi-agent committees achieve an 89.5 percent overall task success rate. Configurations with 2 to 4 agents reach 91.7 to 100 percent success, compared to 78.0 percent for single-agent baselines, yielding improvements of 13.7 to 22.0 percentage points. At the action level, the system attains a 93.1 percent success rate with a median per-action latency of 0.71 seconds, enabling real-time and continuous integration testing. Vision-enabled agents successfully identify user interface elements, with navigation and reporting achieving 100 percent success and form filling achieving 99.2 percent success. We evaluate the framework on WebShop and OWASP benchmarks, achieving 74.7 percent success on WebShop compared to a 50.1 percent published GPT-3 baseline, and 82.0 percent success on OWASP Juice Shop security testing with coverage of 8 of the 10 OWASP Top 10 vulnerability categories. Across 20 injected regressions, the committee achieves an F1 score of 0.91 for bug detection, compared to 0.78 for single-agent baselines. The open-source implementation enables reproducible research and practical deployment of LLM-based software testing in CI/CD pipelines.
💡 Deep Analysis
Deep Dive into Multi-Agent LLM Committees for Autonomous Software Beta Testing.
Manual software beta testing is costly and time-consuming, while single-agent large language model (LLM) approaches suffer from hallucinations and inconsistent behavior. We propose a multi-agent committee framework in which diverse vision-enabled LLMs collaborate through a three-round voting protocol to reach consensus on testing actions. The framework combines model diversity, persona-driven behavioral variation, and visual user interface understanding to systematically explore web applications. Across 84 experimental runs with 9 testing personas and 4 scenarios, multi-agent committees achieve an 89.5 percent overall task success rate. Configurations with 2 to 4 agents reach 91.7 to 100 percent success, compared to 78.0 percent for single-agent baselines, yielding improvements of 13.7 to 22.0 percentage points. At the action level, the system attains a 93.1 percent success rate with a median per-action latency of 0.71 seconds, enabling real-time and continuous integration testing. Vis
📄 Full Content
Multi-Agent LLM Committees for Autonomous Software Beta Testing
Sumanth Bharadwaj Hachalli Karanam
Data Science, New York University, New York, 10038
sh8111@nyu.edu
Dhiwahar Adhithya Kennady
Data Science, New York University, New York, 10038
dk5025@nyu.edu
Abstract
Manual software beta testing is costly and time-consuming,
while single-agent LLM approaches suffer from hallucinations
and inconsistent behavior. We introduce a novel multi-agent
committee framework where diverse vision-enabled LLMs col-
laborate through a three-round voting protocol to achieve con-
sensus on testing actions. Our system combines model diversity
(GPT-4o, Gemini 2.5 Pro Flash, Grok 2 Vision 1212), persona-
driven behavioral variation, and visual UI understanding to
systematically explore web applications. Through experiments
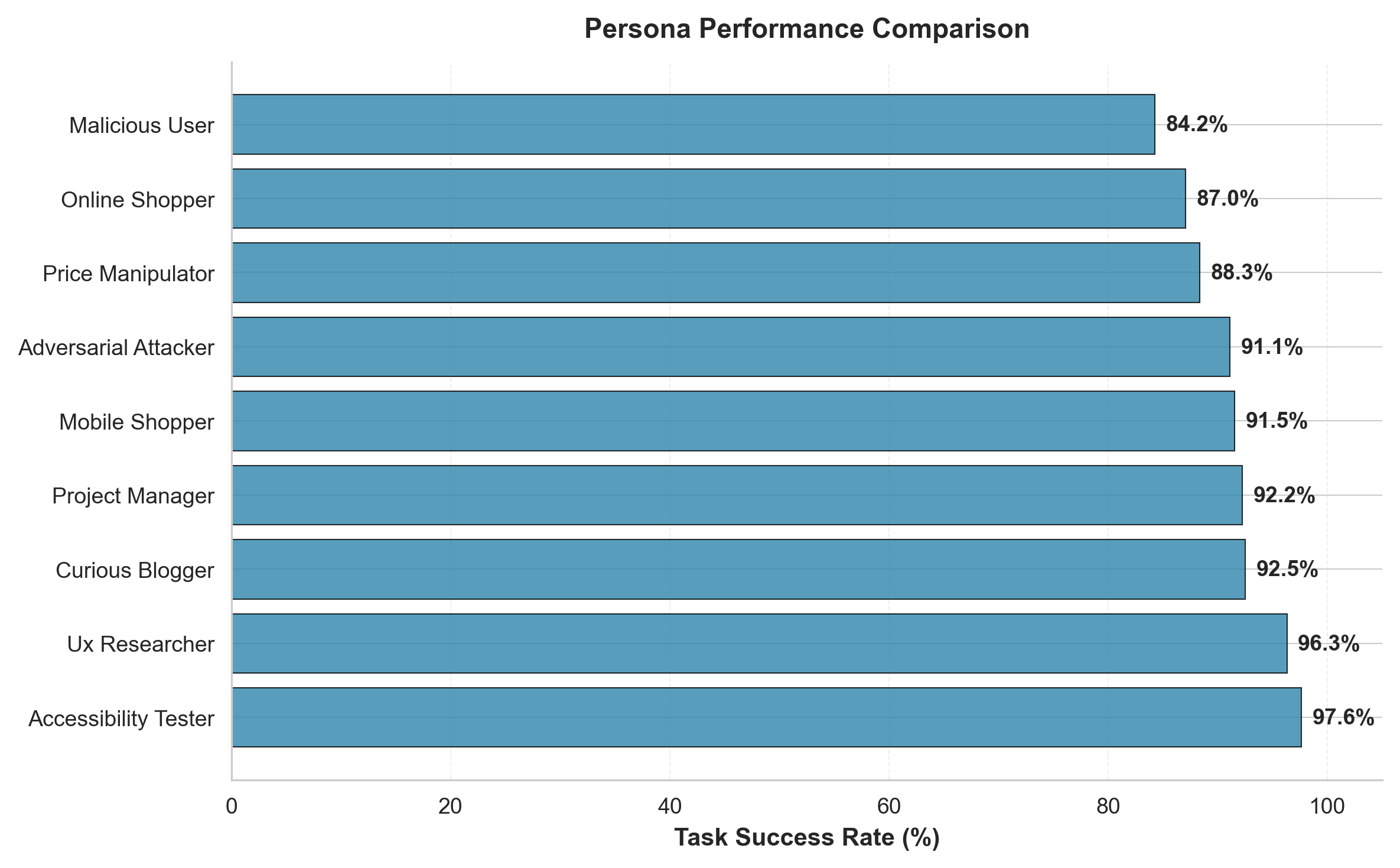
across 84 runs with 9 distinct testing personas and 4 scenarios,
we demonstrate that multi-agent committees achieve an 89.5%
overall task success rate, with multi-agent configurations (2-
4 agents) achieving 91.7–100% success compared to 78.0%
for single-agent baselines (+13.7–22.0 percentage points im-
provement). At the action level, the framework attains a 93.1%
overall action success rate and a median per-action latency of
0.71 seconds (mean 0.87 seconds), making it suitable for real-
time and continuous integration testing. Our vision-enabled
approach successfully identifies UI elements with navigation
and reporting achieving 100% success rates and form filling
achieving 99.2% success. We validate our framework against
WebShop and OWASP benchmarks, achieving 74.7% success
on WebShop (vs. 50.1% published GPT-3 baseline, +24.6pp)
and 82.0% on OWASP Juice Shop security testing with cov-
erage of 8 of the 10 OWASP Top 10 vulnerability categories.
Across 20 injected regressions, our committees reach an F1
score of 0.91 for bug detection (vs. 0.78 for single-agent base-
lines), while security validators attain high precision on SQL
injection and XSS attempts. Our open-source implementation
provides a reproducible framework for LLM-based software
testing research and practical deployment in CI/CD pipelines.
1. Introduction
Software beta testing is a critical yet resource-intensive
phase of development, requiring human testers to systemat-
ically explore applications, identify bugs, and validate user
workflows [1]. Companies spend significant resources on
quality assurance, with manual testing consuming 20–40%
of development budgets [2]. Recent advances in large lan-
guage models (LLMs) have opened possibilities for automated
testing [3, 4], but single-agent approaches face fundamental
challenges: hallucinations leading to invalid actions [5,6], in-
consistent behavior across runs, and difficulty understanding
visual interfaces.
Human beta testing naturally involves diverse perspectives,
since users with different goals, technical backgrounds, and in-
teraction patterns often discover different categories of bugs [7].
A security-focused tester finds vulnerabilities that a usability
tester might miss, while an accessibility tester identifies issues
invisible to others. Persona-based testing approaches [8] lever-
age this diversity systematically. This insight motivates our
central research question: Can multi-agent LLM committees
with diverse personas and consensus-based decision making
outperform single-agent approaches in automated software
testing and regression detection?
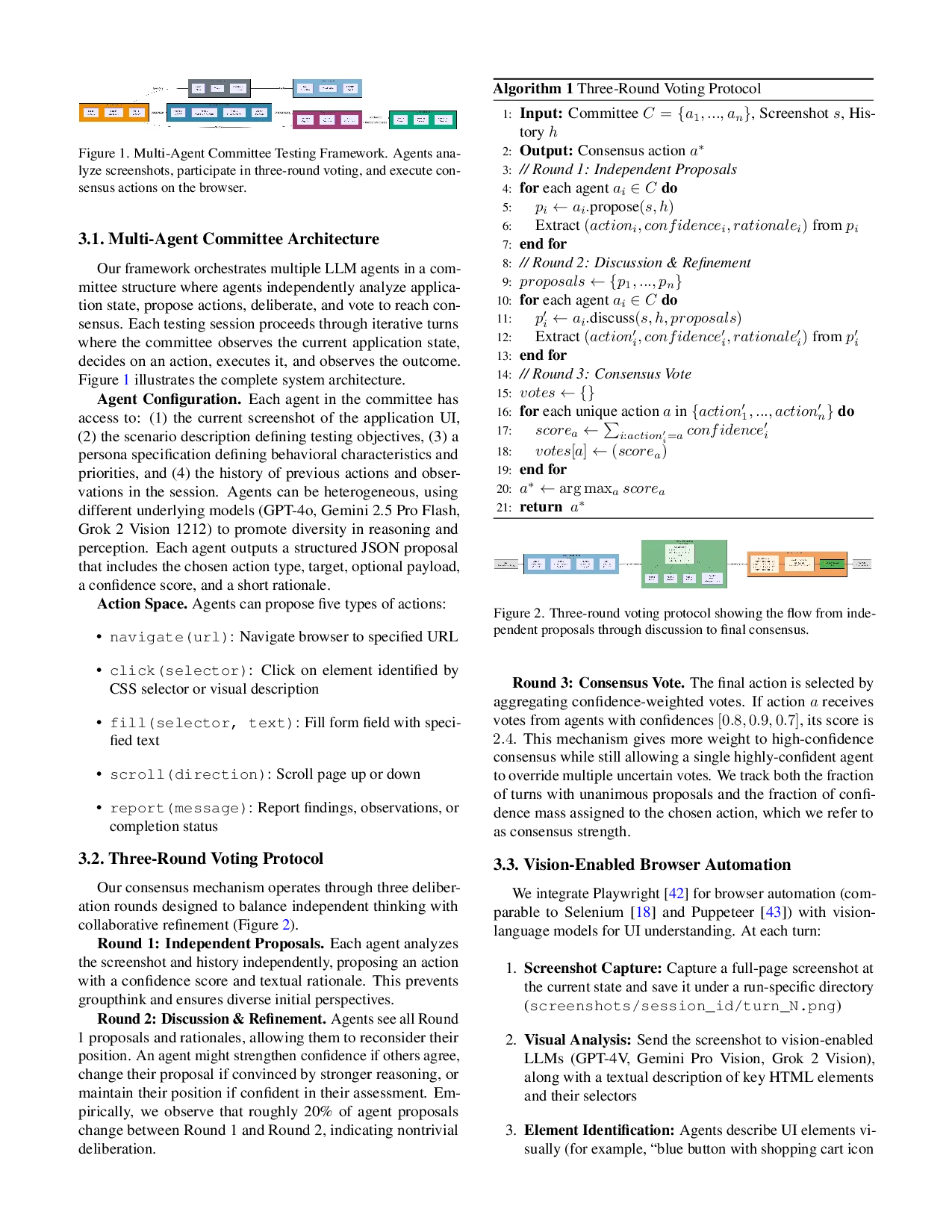
This paper introduces a multi-agent framework where com-
mittee members collaborate through structured deliberation
to test web applications. Our system features: (1) a three-
round voting protocol that achieves consensus through in-
dependent proposals, group discussion, and final voting, (2)
vision-enabled agents that analyze screenshots to identify UI
elements and validate actions, (3) persona-driven behavioral
diversity spanning user archetypes from typical shoppers to
adversarial attackers, and (4) safety validators that detect se-
curity vulnerabilities during test execution. The framework is
instrumented with a storage and metrics layer that logs every
agent proposal, consensus action, and validator outcome into
a SQLite database, enabling rigorous statistical analysis of
success rates, latencies, and committee agreement.
We evaluate our framework through comprehensive exper-
iments across multiple dimensions. Experiment 1A (Multi-
Agent Scaling) compares committee sizes from 1–4 agents to
measure consensus quality and error reduction. Experiment
1B (Persona Diversity) tests 9 distinct personas including on-
line shoppers, accessibility testers, and adversarial attackers
across e-commerce and security scenarios. Experiment 1C
(Regression Detection) validates regression detection capabil-
ities on 20 injected bugs with precision, recall, and F1 metrics.
Experiment 2 benchmarks against OWASP Juice Shop secu-
arXiv:2512.21352v1 [cs.SE] 21 Dec 2025
rity testing. Experiment 3 benchmarks against the WebShop
e-commerce tasks.
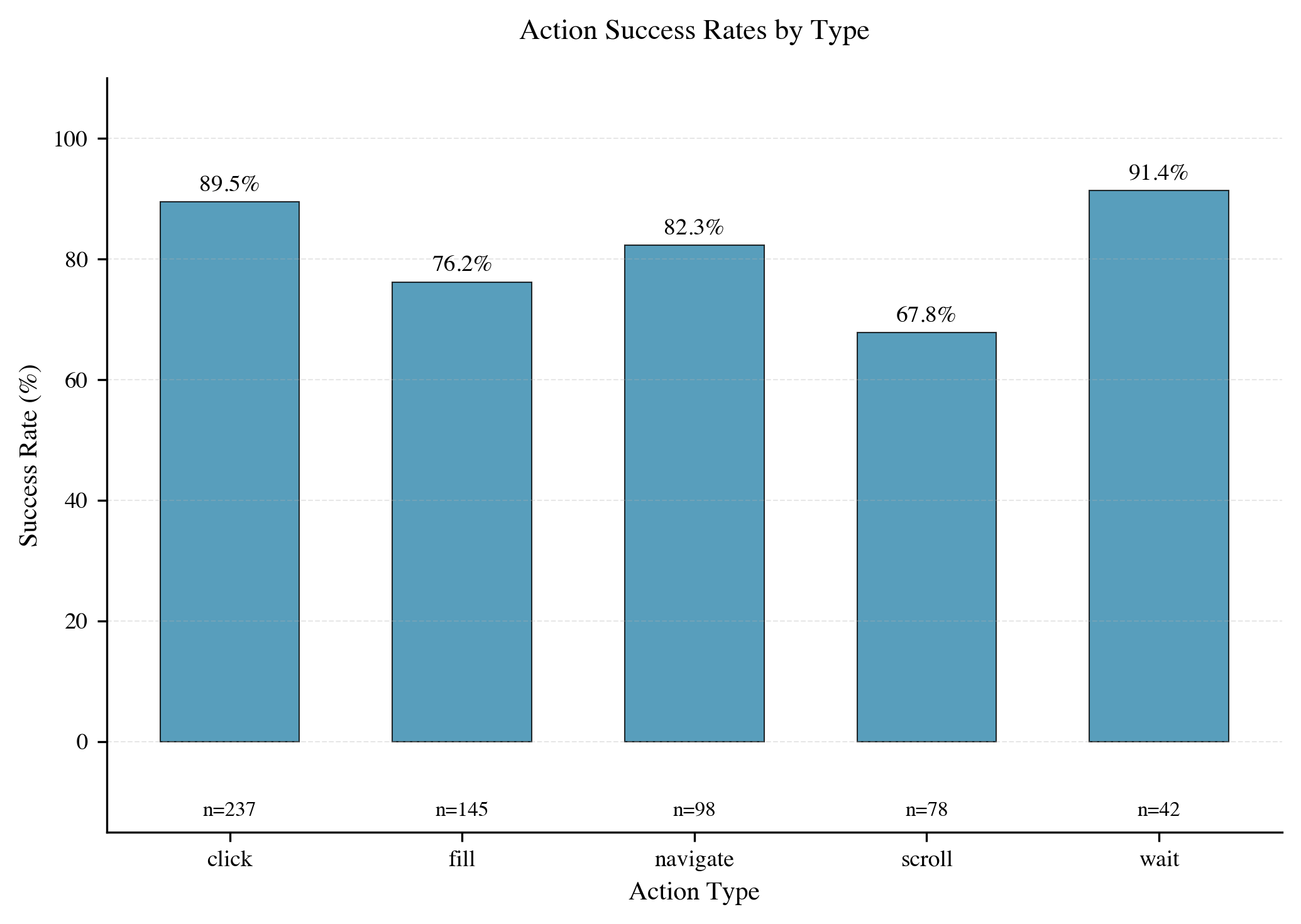
Our key findin
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.