Reasoning Palette: Modulating Reasoning via Latent Contextualization for Controllable Exploration for (V)LMs
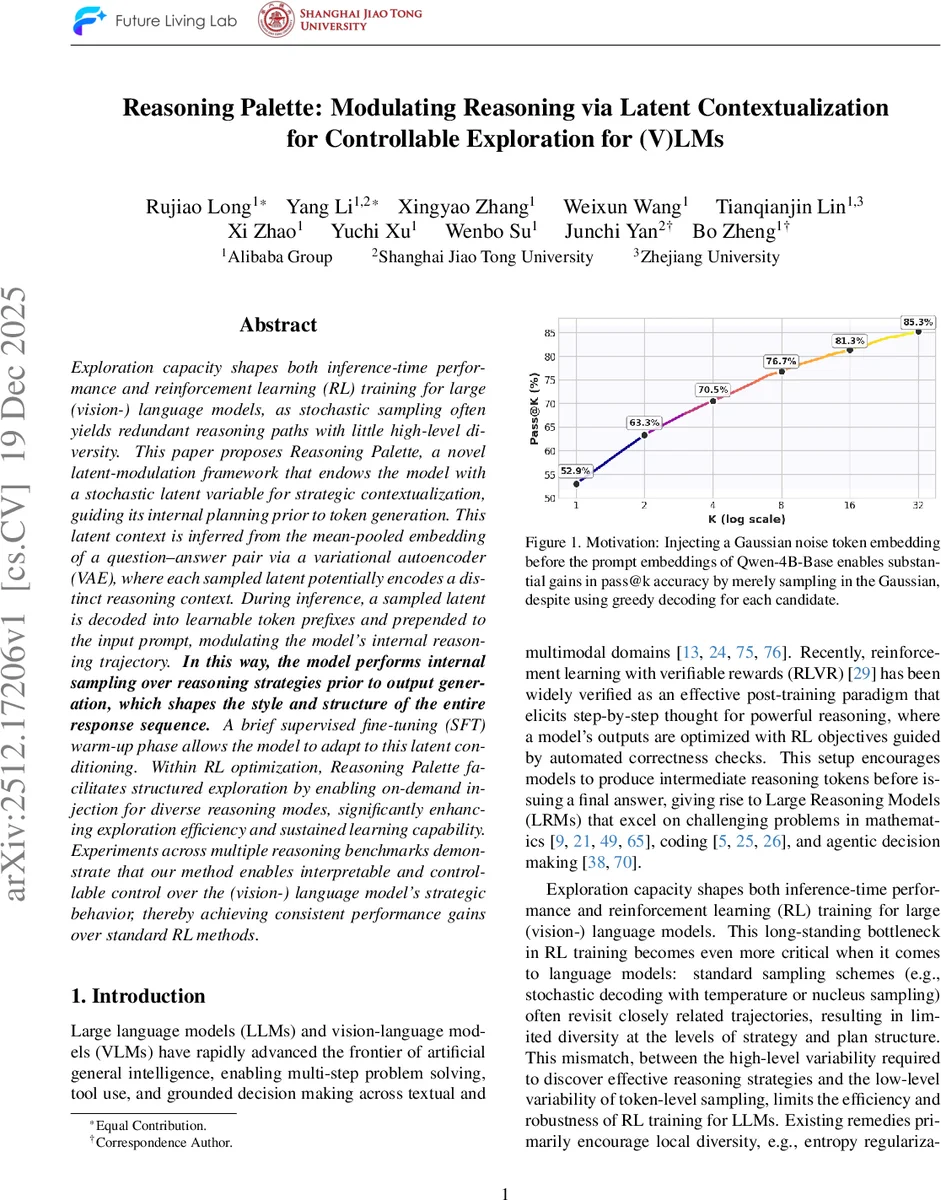
Exploration capacity shapes both inference-time performance and reinforcement learning (RL) training for large (vision-) language models, as stochastic sampling often yields redundant reasoning paths with little high-level diversity. This paper proposes Reasoning Palette, a novel latent-modulation framework that endows the model with a stochastic latent variable for strategic contextualization, guiding its internal planning prior to token generation. This latent context is inferred from the mean-pooled embedding of a question-answer pair via a variational autoencoder (VAE), where each sampled latent potentially encodes a distinct reasoning context. During inference, a sampled latent is decoded into learnable token prefixes and prepended to the input prompt, modulating the model’s internal reasoning trajectory. In this way, the model performs internal sampling over reasoning strategies prior to output generation, which shapes the style and structure of the entire response sequence. A brief supervised fine-tuning (SFT) warm-up phase allows the model to adapt to this latent conditioning. Within RL optimization, Reasoning Palette facilitates structured exploration by enabling on-demand injection for diverse reasoning modes, significantly enhancing exploration efficiency and sustained learning capability. Experiments across multiple reasoning benchmarks demonstrate that our method enables interpretable and controllable control over the (vision-) language model’s strategic behavior, thereby achieving consistent performance gains over standard RL methods.
💡 Research Summary
Reasoning Palette introduces a novel latent‑modulation framework designed to improve both inference‑time diversity and reinforcement‑learning (RL) exploration efficiency for large language models (LLMs) and vision‑language models (VLMs). The core idea is to equip the model with a stochastic latent variable that captures high‑level reasoning strategies before any token is generated. To obtain this latent, the authors first compute a mean‑pooled embedding of a question‑answer pair using the frozen token embedding matrix of a pre‑trained model. This embedding, denoted h, is fed into a variational auto‑encoder (VAE). The VAE encoder maps h to the parameters (μ, σ) of a diagonal Gaussian posterior, from which a latent vector z is sampled. The decoder then reconstructs h from z, and, crucially, the decoder is also used to generate a short sequence of learnable token‑prefix embeddings pz (of length L) by either sampling L independent latents or tiling a single latent. Because pz lives in the same space as the model’s native token embeddings, it can be directly prepended to the prompt embeddings without any architectural changes.
A lightweight supervised fine‑tuning (SFT) warm‑up follows. Synthetic training examples are created by sampling z from the isotropic prior, decoding it into pz, and pairing pz with original prompt‑response pairs from the VAE training corpus. The base model is fine‑tuned for a few iterations (typically ten) on the standard language‑modeling loss, learning to condition on arbitrary prefix embeddings while preserving its general instruction‑following abilities. This short SFT prevents the model from over‑fitting to a deterministic prefix and ensures that variations in z still lead to observable changes in output.
During RL training, each episode begins by sampling a fresh latent z and constructing its prefix pz. The prefix‑augmented prompt is then fed to the policy πθ, which generates a response. The reward is a verifiable signal (e.g., correctness of a math solution) as in RL‑VR settings. By sampling a new z for every episode, the policy explores distinct reasoning “families” rather than merely different token‑level continuations. The authors integrate this mechanism with standard PPO and with Group‑Relative Policy Optimization (GRPO), showing that the latent‑driven exploration yields higher average rewards, faster convergence, and more stable learning under sparse reward conditions.
Empirical evaluation spans several reasoning benchmarks: mathematical problem solving, code generation, multi‑hop question answering, and factual retrieval. Across the board, Reasoning Palette consistently outperforms baselines that rely on temperature or nucleus sampling, as well as methods that only tune soft prompts. Notably, even a single Gaussian noise token inserted before the prompt (as illustrated in Figure 1) dramatically boosts Pass@k under greedy decoding, highlighting the power of pre‑generation latent conditioning. Ablation studies on prefix length L reveal a sweet spot (typically L = 3–4) where control strength is sufficient without sacrificing the model’s flexibility. Visualization of the latent space shows semantically coherent clusters corresponding to distinct reasoning modes (e.g., symbolic computation vs. natural‑language explanation), enabling post‑hoc analysis and targeted sampling for specific tasks.
In summary, Reasoning Palette contributes four key advances: (1) a VAE‑learned continuous latent space that encodes high‑level reasoning strategies; (2) a mechanism to translate sampled latents into token prefixes that seamlessly integrate with existing LLM/VLM architectures; (3) a brief SFT phase that aligns the base model to latent‑conditioned prefixes while preserving general capabilities; and (4) a structured exploration paradigm for RL that samples over reasoning strategies rather than individual tokens. This combination yields both measurable performance gains and interpretable, controllable behavior, opening new avenues for fine‑grained steering of large generative models in both inference and reinforcement‑learning contexts.
Comments & Academic Discussion
Loading comments...
Leave a Comment