DeContext as Defense: Safe Image Editing in Diffusion Transformers
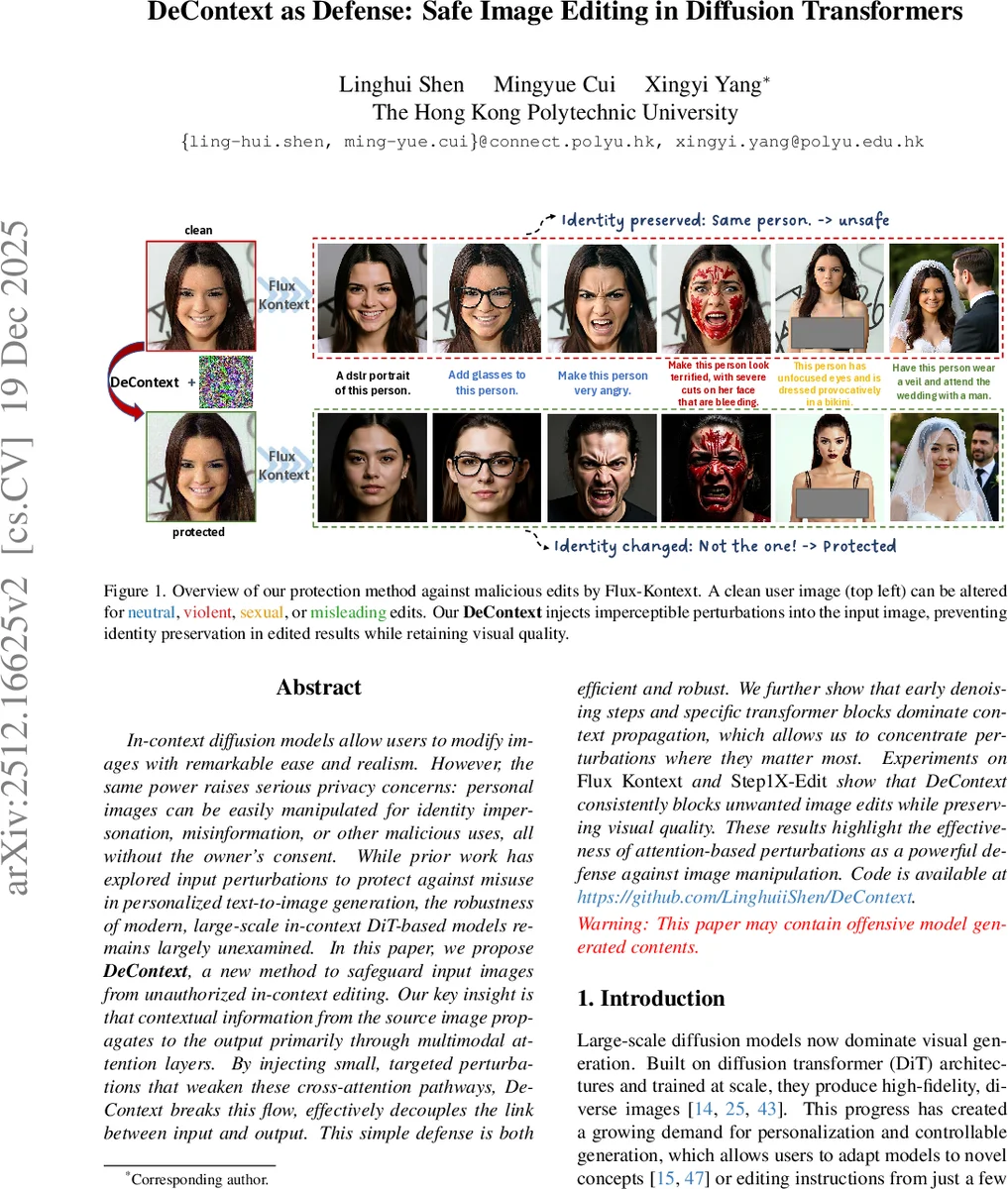
In-context diffusion models allow users to modify images with remarkable ease and realism. However, the same power raises serious privacy concerns: personal images can be easily manipulated for identity impersonation, misinformation, or other malicious uses, all without the owner’s consent. While prior work has explored input perturbations to protect against misuse in personalized text-to-image generation, the robustness of modern, large-scale in-context DiT-based models remains largely unexamined. In this paper, we propose DeContext, a new method to safeguard input images from unauthorized in-context editing. Our key insight is that contextual information from the source image propagates to the output primarily through multimodal attention layers. By injecting small, targeted perturbations that weaken these cross-attention pathways, DeContext breaks this flow, effectively decouples the link between input and output. This simple defense is both efficient and robust. We further show that early denoising steps and specific transformer blocks dominate context propagation, which allows us to concentrate perturbations where they matter most. Experiments on Flux Kontext and Step1X-Edit show that DeContext consistently blocks unwanted image edits while preserving visual quality. These results highlight the effectiveness of attention-based perturbations as a powerful defense against image manipulation. Code is available at https://github.com/LinghuiiShen/DeContext.
💡 Research Summary
The paper addresses a newly emerging privacy threat posed by large‑scale diffusion transformer (DiT) models that support in‑context image editing, such as Flux‑Kontekst and Step1X‑Edit. These models can take a single user‑provided photograph together with a short text prompt and instantly generate edited versions that may be violent, sexual, misleading, or otherwise harmful. Because the conditioning happens at inference time, an adversary can weaponize publicly shared photos without any model fine‑tuning or data collection, leading to identity impersonation, deep‑fakes, and copyright violations.
Existing defenses—most of which target text‑to‑image diffusion or UNet‑based image‑to‑image personalization—are ineffective against DiT‑based systems. The authors first conduct two diagnostic experiments. A standard PGD attack that maximizes the flow‑matching loss produces only mild lighting artifacts; the context image’s identity remains clearly visible in the output, showing that naïve end‑to‑end attacks cannot break the strong conditioning. In contrast, manually zeroing out the cross‑attention entries that connect target‑image queries to context‑image keys completely removes the influence of the conditioning image, confirming that the multimodal attention mechanism is the primary conduit for context propagation.
Guided by this insight, the authors propose DeContext, a defense that directly attacks the attention pathway. Within each transformer block, they compute the average attention weight from target queries to context keys (denoted r_ctx). Their objective is to minimize r_ctx, i.e., maximize L_DeContext = 1 − r_ctx. They perform gradient ascent on the pixel values of the context image while keeping all model weights frozen, using a sign‑gradient update constrained within an ℓ∞‑ball (ε ≈ 8/255). This produces an imperceptible perturbation that makes the context image “invisible” to the model’s attention.
To make the attack efficient and robust, the authors identify two concentration points. First, a temporal analysis of gradient magnitudes across diffusion timesteps shows that early denoising steps (large t, high noise) receive the strongest gradients from the context image; therefore, perturbations are focused on these timesteps. Second, a depth‑wise analysis reveals that the early‑to‑mid transformer layers contribute most to context propagation, so only a subset of blocks (e.g., layers 2‑5) are targeted. Because the diffusion process is stochastic—varying with prompt, timestep, and random noise—the authors adopt a sampling‑based approximation: at each iteration they randomly draw a prompt from a pool of 60 editing commands, a timestep from the identified interval, and a noise seed, then compute the loss and update the perturbation. This yields an unbiased estimator of the expected loss over all possible conditions, ensuring that the final perturbation works across diverse prompts and seeds.
Experiments on Flux‑Kontekst and Step1X‑Edit demonstrate that DeContext dramatically reduces the ability of the model to retain the original identity. Face‑recognition accuracy on edited outputs drops by more than 70 % compared with unprotected images. Visual quality metrics (LPIPS, SSIM, PSNR) show only modest degradation (typically < 0.2 LPIPS or < 2 dB PSNR loss), and human observers find the protected images indistinguishable from clean ones. The defense succeeds across four editing categories—neutral, violent, sexual, and misleading—showing that the attention‑based perturbation is not limited to a specific style. Compared with prior defenses such as PhotoGuard and FaceLock, DeContext achieves higher protection rates while preserving far better image fidelity.
The paper’s contributions are threefold: (1) it introduces the first defense specifically designed for DiT‑based in‑context image editing; (2) it pinpoints multimodal cross‑attention as the critical vulnerability enabling context leakage; and (3) it presents a practical, gradient‑based perturbation strategy that concentrates on the most influential timesteps and transformer blocks. The authors discuss limitations, noting that larger perturbation budgets improve robustness at the cost of perceptibility, and that future architectures with different attention schemes may require adapted defenses. They suggest extending the approach to video, 3D, and multimodal (text‑audio‑image) generative models, and exploring game‑theoretic formulations of attack‑defense dynamics.
In summary, DeContext demonstrates that by subtly disrupting the attention pathways through which a conditioning image influences a diffusion transformer, one can effectively “detach” the context without altering the model itself. This provides a lightweight, scalable, and high‑fidelity safeguard for personal images against unauthorized manipulation in the rapidly advancing landscape of generative AI.
Comments & Academic Discussion
Loading comments...
Leave a Comment